Spring源码浅析——bean创建流程
一、背景知识
-
- 什么是循环依赖
本节我们看一下Spring如何解决循环依赖的问题。循环依赖的问题在很多语言场景上都会出现,比如说python中闭包导致的循环依赖:
class commonClass(object):
def __init__(self):
def b():
self._a = 1
self._b = b
#下面我们对对象进行实例化
ins = new commonClass()
#我们看如下调用的输出:
ins._b.__closure__[0].cell_contents
<__main__.A object at 0x100b63090>
#继续看输出
ins._b
<function b at 0x100b5bb18>
#我们对于以上调用进行赋值
ins1 = ins._b
#此时我们把ins对象删除
del ins
#由于我们指定了新的对象ins1,我们来看看上面使用的两个调用在内存中的存在状况
ins1.__closure__[0].cell_contents
<__main__.A object at 0x100b63090>
ins1.__closure__[0].cell_contents._b
<function b at 0x100b5bb18>
虽然语言不同,但是循环依赖或者循环引用,面临的场景都是类似的,我们上面把ins对象删除前,把它对b()函数的调用赋值给了ins1,然后对ins删除,但是这种闭包导致于原来存在于ins对象的循环引用并没有被清除,而是完全被保留了下来,这种做法会导致,如果没有及时手动的对于使用过的对象清除,会导致gc无法作用到这些对象上面,然后累加越来越多,最终导致内存泄漏。
好的,以下是一个表格形式的输出:
| Spring解决循环依赖 | Python中解决循环引用 | |
|---|---|---|
| 机制 | 三级缓存 | 垃圾回收机制 |
| 应用场景 | Java应用程序 | Python程序 |
| 功能 | 延迟初始化、懒加载 | 释放不再使用的内存空间 |
| 实现方式 | AOP、BeanPostProcessor等 | 内建垃圾回收模块 |
| 缓存方式 | 三级缓存 | N/A |
| 内存管理 | 需要考虑 | 需要考虑 |
希望这个表格能够更加清晰地展示Spring解决循环依赖和Python中解决循环引用之间的相同点和不同点。
而Spring中对于循环依赖有着自己的处理机制,但是也只针对单例对象的属性注入循环依赖是可以被解决的,其它类型的循环依赖却处理不了,后面看完源码后,你就能明白出现这种情况的原因了。
-
- 三级缓存
这种缓存的设计方式,就是为了解决循环依赖问题,这与JVM中的GC标记清除说的并不是一个问题,但是很多人容易搞混,我在这里进一步做下总结:
- Spring中解决循环依赖的方式:
在Spring框架中,当两个或多个bean相互依赖时,可能会发生循环依赖。Spring使用三级缓存和后置处理器来解决循环依赖问题。当一个bean被创建时,Spring将其放入第一级缓存中,并标记为“正在创建中”。如果该bean引用了其他尚未创建的bean,则Spring将开始创建依赖项,并将其放入第二级缓存中。如果在创建过程中遇到循环依赖,则Spring将从第二级缓存中获取先前创建的bean实例,并注入当前bean中。最后,当bean创建完成时,它将从第一级缓存中移除并放入第三级缓存中。
- Java的GC标记清除算法:
标记-清除算法是一种Java垃圾收集器使用的内存回收算法。该算法分为两个阶段:标记阶段和清除阶段。在标记阶段,垃圾收集器标记所有仍然在使用中的对象。在清除阶段,垃圾收集器清除所有未被标记的对象。由此产生的碎片可能会影响性能。
因此,除了它们都是与Java相关的主题外,它们之间没有明显的联系或共同点,所以一定不要搞混了。
/** Cache of singleton objects: bean name --> bean instance */
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<String, Object>(256);
/** Cache of early singleton objects: bean name --> bean instance */
private final Map<String, Object> earlySingletonObjects = new HashMap<String, Object>(16);
/** Cache of singleton factories: bean name --> ObjectFactory */
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<String, ObjectFactory<?>>(16);
| 缓存名称 | 用途 |
|---|---|
| singletonObjects | 存放完全初始化好的 bean,从该缓存中取出的 bean 可以直接使用 |
| earlySingletonObjects | 存放早期 bean 对象(尚未填充属性),用于解决循环依赖 |
| singletonFactories | 存放 bean 工厂对象,用于解决循环依赖 |
-
- 回顾一下获取到bean对象的流程
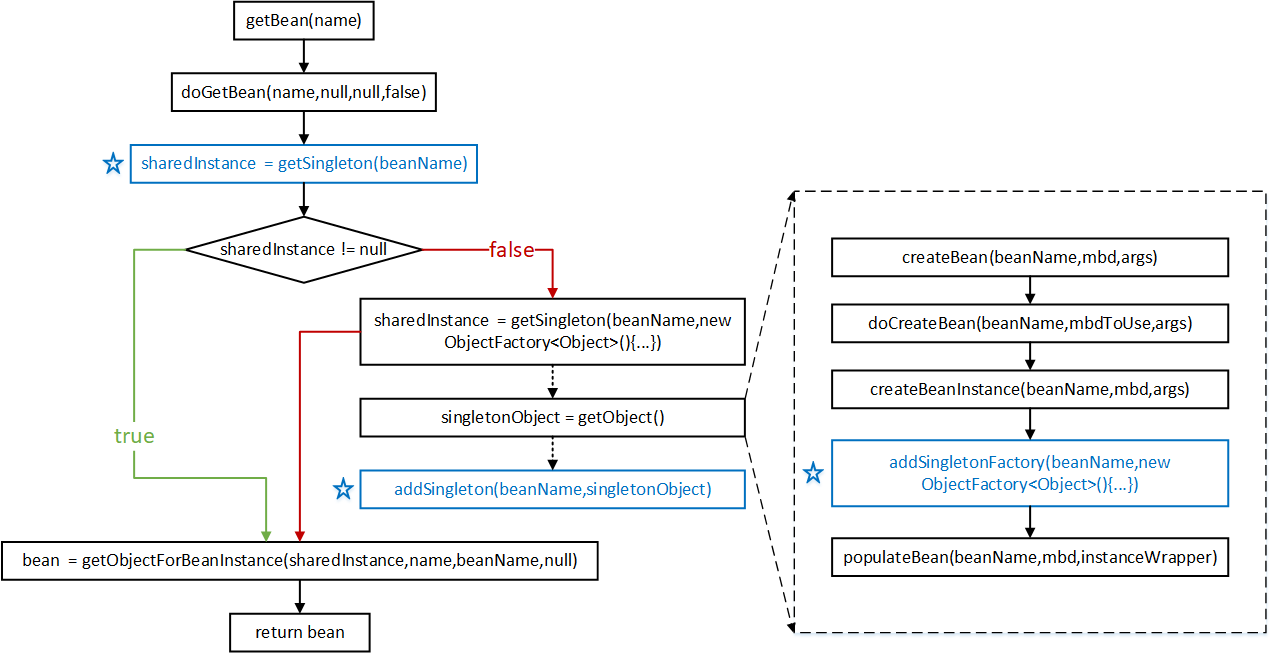
我们来看这张流程图,开始执行以后在sharedInstance != null这里出现逻辑判断,也就是图中标记的红色和绿色两条路,上图中蓝色是用来标注读取/添加缓存的方法。我们来分析下bean初始化的流程,getBean方法开始,由于它是空壳方法,逻辑都包在doGetBean中。doGetBean首先会调用getSingleton(beanName)方法,意在获取到sharedInstance对象,对象如果已经存在,直接进入绿色路径,getObjectForBeanInstance方法使用对象走后面的流程,如果为空,并且缓存中也没记录,就要走创建的逻辑,也就是getSingleton(beanName,new ObjectFactory() {…})部分的逻辑,创建bean实例。虚线部分是getSingleton方法内部调用的两个方法。
进一步简略说明一下。很抱歉,我的前几个回答中的描述有些片面。以下是更全面的描述:
在调用 getSingleton 方法时,Spring 容器会先检查 bean 是否已经创建并放入缓存中。如果该 bean 已经存在,则直接返回缓存中的实例对象;否则,容器将按照以下步骤创建并初始化 bean:
-
首先,容器会检查 bean 的作用域是否为 singleton,并检查
singletonObjects缓存中是否存在与 bean 名称对应的 instance 对象。 -
如果存在 instance 对象,则容器返回该对象;否则,容器将创建一个新的 bean 实例,并执行以下操作:
-
在创建 bean 实例前,容器会调用
beforeSingletonCreation方法更新当前正在创建的 bean 名称,并加入到singletonsCurrentlyInCreation集合中,以便解决循环依赖问题。 -
容器会通过
doCreateBean方法创建 bean 实例,并执行以下操作:-
创建 bean 实例前,容器会调用
resolveBeforeInstantiation方法查找并处理带有@Autowired注解或InstantiationAwareBeanPostProcessor的构造函数或工厂方法参数。 -
在创建 bean 实例过程中,容器会检查是否存在依赖于其他 bean 实例的属性或构造函数参数。如果存在,则容器会递归调用
getSingleton方法获取依赖的 bean 实例,并注入到当前 bean 实例中。如果依赖的 bean 实例尚未创建,则容器会通过递归调用getSingleton方法来创建它们。 -
在创建 bean 实例后,容器会调用
populateBean方法注入各种属性值、回调方法和 BeanPostProcessor 等功能。 -
最后,在初始化 bean 实例前,容器会调用
applyBeanPostProcessorsBeforeInitialization方法应用前置处理器,并执行各种回调方法和初始化操作。如果 bean 实例实现了 InitializingBean 接口,会调用其afterPropertiesSet方法;如果存在自定义的初始化方法,则会调用该方法。
-
-
在创建 bean 实例后,容器会调用
applyBeanPostProcessorsAfterInitialization方法应用后置处理器,并将 bean 实例包装成代理对象(如果有拦截器)。
-
-
最后,在 bean 实例创建并初始化完成后,容器会将其放入
singletonObjects缓存中,并从singletonsCurrentlyInCreation集合中删除当前 bean 名称。
需要注意的是,以上步骤仅适用于 singleton 作用域的 bean。如果 bean 的作用域是 prototype,则容器不会将其放入缓存中,而是每次调用 getSingleton 方法时都会重新创建一个新的实例对象。
二、源码分析
以下是以beanA、beanB为举例对象的12个步骤:
- 容器在调用getBean(beanA)方法时,会先从缓存中查找是否存在beanA的单例实例。
public Object getBean(String name) throws BeansException {
return doGetBean(name, null, null, false);
}
- 如果不存在,容器会调用doGetBean(beanA)方法,进入创建beanA实例的流程。
protected <T> T doGetBean(final String name, final Class<T> requiredType, final Object[] args, boolean typeCheckOnly)
throws BeansException {
...
// 从缓存中获取bean实例
Object sharedInstance = getSingleton(beanName);
...
}
- doGetBean(beanA)方法会再次尝试从缓存中获取beanA的单例实例。
protected <T> T doGetBean(final String name, final Class<T> requiredType, final Object[] args, boolean typeCheckOnly)
throws BeansException {
...
// 再次从缓存中获取bean实例
Object sharedInstance = getSingleton(beanName);
...
}
- 因为之前没有获取到,所以继续执行getSingleton(beanA)方法。
protected Object getSingleton(String beanName) {
// 先从singletonObjects缓存中查找bean实例
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
synchronized (this.singletonObjects) {
// double check
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null) {
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
singletonObject = singletonFactory.getObject();
// 将 beanA 的早期引用放入缓存 earlySingletonObjects 中
this.earlySingletonObjects.put(beanName, singletonObject);
// 将 beanA 的对象工厂从缓存 singletonFactories 中移除
this.singletonFactories.remove(beanName);
}
}
}
}
return singletonObject;
}
- getSingleton(beanA)方法会检查是否存在创建beanA实例的过程中的早期实例(early singleton),如果存在,则直接返回早期实例作为结果。
protected Object getSingleton(String beanName) {
...
// 检查是否存在早期实例
if (singletonObject == null) {
synchronized (this.singletonObjects) {
// double check
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null) {
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
singletonObject = singletonFactory.getObject();
// 将其设置为早期实例
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
...
}
- 如果早期实例不存在,继续执行createBean(beanA)方法。
protected Object createBean(final String beanName, final RootBeanDefinition mbd, final @Nullable Object[] args)
throws BeanCreationException {
...
// 调用createBeanInstance方法实例化bean
instanceWrapper = createBeanInstance(beanName, mbd, args);
...
}
- createBean(beanA)方法会创建一个新的beanA实例,并填充其属性。
// AbstractAutowireCapableBeanFactory.java
protected Object createBean(String beanName, RootBeanDefinition mbd, @Nullable Object[] args) throws BeanCreationException {
// 1. 实例化Bean对象
Object beanInstance = doCreateBean(beanName, mbd, args);
// ...
// 4. 填充属性值
applyPropertyValues(beanName, mbd, beanInstance, mergedBeanDefinition.getBeanClass());
// ...
return beanInstance;
}
- 在填充beanA属性的过程中,容器发现beanA依赖于beanB,因此需要创建beanB实例并将其注入到beanA中。
// AbstractAutowireCapableBeanFactory.java
protected void applyPropertyValues(String beanName, BeanDefinition beanDefinition, Object bean, Class<?> beanType) throws BeansException {
// ...
try {
// 3. 自动注入依赖的其它Bean
for (PropertyValue pv : pvs) {
String propertyName = pv.getName();
Object originalValue = pv.getValue();
Object resolvedValue = resolveValueIfNecessary(beanName, beanDefinition, propertyName, originalValue);
// ...
// 3.1 属性值解析为RuntimeBeanReference,则进行注入
if (resolvedValue instanceof RuntimeBeanReference) {
String referencedBeanName = ((RuntimeBeanReference) resolvedValue).getBeanName();
Object referencedBean = getBean(referencedBeanName);
resolvedValue = referencedBean;
}
// ...
// 3.2 设置属性值
setPropertyValues(new MutablePropertyValues(Collections.singleton(new PropertyValue(propertyName, resolvedValue))), bean, mergedBeanDefinition);
// ...
}
} catch (BeansException ex) {
throw new BeanCreationException(beanDefinition.getResourceDescription(), beanName, "Error setting property values", ex);
}
}
- 容器会递归执行创建beanB实例的流程,直到全部依赖都被满足。
protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, final @Nullable Object[] args) {
// Instantiate the bean.
BeanWrapper instanceWrapper = null;
if (mbd.isSingleton()) {
instanceWrapper = this.factoryBeanInstanceCache.remove(beanName);
}
if (instanceWrapper == null) {
instanceWrapper = createBeanInstance(beanName, mbd, args);
}
final Object bean = instanceWrapper.getWrappedInstance();
Class<?> beanType = instanceWrapper.getWrappedClass();
... // 省略其他操作
// Initialize the bean instance.
Object exposedObject = bean;
try {
populateBean(beanName, mbd, instanceWrapper);
if (exposedObject != null) {
// 执行依赖注入的操作
applyBeanPostProcessorsBeforeInitialization(exposedObject, beanName);
}
initializeBean(beanName, exposedObject, mbd);
if (exposedObject != null) {
// 处理Bean初始化后的回调方法和后置处理器
exposedObject = applyBeanPostProcessorsAfterInitialization(exposedObject, beanName);
}
}
catch (Throwable ex) {
if (ex instanceof BeanCreationException && beanName.equals(((BeanCreationException) ex).getBeanName())) {
throw (BeanCreationException) ex;
}
else {
throw new BeanCreationException(mbd.getResourceDescription(), beanName, "Initialization of bean failed", ex);
}
}
if (mbd.isSingleton()) {
addSingleton(beanName, exposedObject);
}
return exposedObject;
}
- 当所有的依赖都被满足后,容器会回调beanA的初始化方法(如果有的话)。
protected Object initializeBean(final String beanName, final Object bean, @Nullable RootBeanDefinition mbd) {
if (System.getSecurityManager() != null) {
AccessController.doPrivileged((PrivilegedAction<Object>) () -> {
invokeAwareMethods(bean);
return null;
}, getAccessControlContext());
}
else {
invokeAwareMethods(bean);
}
Object wrappedBean = bean;
if (mbd == null || !mbd.isSynthetic()) {
// 执行所有的BeanPostProcessor,在执行初始化方法前后的处理器都会被调用
wrappedBean = applyBeanPostProcessorsBeforeInitialization(wrappedBean, beanName);
}
try {
invokeInitMethods(beanName, wrappedBean, mbd);
}
catch (Throwable ex) {
throw new BeanCreationException(
(mbd != null ? mbd.getResourceDescription() : null),
beanName,
"Invocation of init method failed",
ex);
}
if (mbd == null || !mbd.isSynthetic()) {
// 执行所有的BeanPostProcessor,在执行初始化方法前后的处理器都会被调用
wrappedBean = applyBeanPostProcessorsAfterInitialization(wrappedBean, beanName);
}
return wrappedBean;
}
- 初始化完成后,容器会回调postProcessAfterInitialization(beanA)方法,最终返回完全初始化好的beanA实例。
public Object applyBeanPostProcessorsAfterInitialization(Object existingBean, String beanName) throws BeansException {
Object result = existingBean;
for (BeanPostProcessor processor : getBeanPostProcessors()) {
Object current = processor.postProcessAfterInitialization(result, beanName);
if (current == null) {
return result;
}
result = current;
}
return
}
- 如果beanA是一个单例bean,则将其缓存起来以备后续使用。
public class DefaultSingletonBeanRegistry extends SimpleAliasRegistry implements SingletonBeanRegistry {
//...
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
public void registerSingleton(String beanName, Object singletonObject) throws IllegalStateException {
Assert.notNull(beanName, "Bean name must not be null");
synchronized (this.singletonObjects) {
Object oldObject = this.singletonObjects.get
}
}
}
三、为什么是三级缓存?
Spring框架中使用三级缓存的主要原因是为了解决循环依赖问题。当两个或多个单例Bean之间存在循环依赖时,如果不使用缓存来暂存正在创建的Bean,就会导致无限递归调用。
在这个过程中,Spring使用了两个关键方法:getEarlyBeanReference和AbstractAutoProxyCreator。
- getEarlyBeanReference
Object exposedObject = bean;
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
// SmartInstantiationAwareBeanPostProcessor 这个后置处理器会在返回早期对象时被调用,如果返回的对象需要加强,那这里就会生成代理对象
if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {
SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp;
exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName);
if (exposedObject == null) {
return bean;
}
}
}
}
return exposedObject;
}
在Bean的创建过程中,如果发现Bean的依赖关系中出现循环引用,则会将已经创建出来但还未完成初始化的Bean暴露到二级缓存中,以便后续的处理。具体地,在DefaultSingletonBeanRegistry类的getSingleton()方法中,会调用getEarlyBeanReference()方法获取早期Bean实例。这个方法会尝试从二级缓存(earlySingletonObjects)中获取Bean实例,如果找到了则直接返回,否则会继续创建Bean实例并放入二级缓存中。
- AbstractAutoProxyCreator
public Object postProcessAfterInitialization(@Nullable Object bean, String beanName) throws BeansException {
if (bean != null) {
Object cacheKey = getCacheKey(bean.getClass(), beanName);
if (this.earlyProxyReferences.remove(cacheKey) != bean) {
return wrapIfNecessary(bean, beanName, cacheKey); // 将目标 Bean 包装成代理对象并放入三级缓存中
}
}
return bean;
}
protected Object wrapIfNecessary(Object bean, String beanName, Object cacheKey) {
if (StringUtils.hasLength(beanName) && this.targetSourcedBeans.contains(beanName)) {
return bean;
}
if (Boolean.FALSE.equals(this.advisedBeans.get(cacheKey)) ||
Boolean.FALSE.equals(this.beanFactory.containsSingleton(beanName))) {
return bean;
}
if (isInfrastructureClass(bean.getClass()) || shouldSkip(bean.getClass(), beanName)) {
this.advisedBeans.put(cacheKey, Boolean.FALSE);
return bean;
}
// Create proxy if we have advice.
Object[] specificInterceptors = getAdvicesAndAdvisorsForBean(bean.getClass(), beanName, null);
if (specificInterceptors != DO_NOT_PROXY) {
this.advisedBeans.put(cacheKey, Boolean.TRUE);
Object proxy = createProxy(bean.getClass(), beanName, specificInterceptors, new SingletonTargetSource(bean));
this.proxyTypes.put(cacheKey, proxy.getClass());
return proxy;
}
this.advisedBeans.put(cacheKey, Boolean.FALSE);
return bean;
}
另一个涉及到三级缓存的核心类是AbstractAutoProxyCreator。这个类是Spring AOP中的代理自动创建器,用于为Bean添加切面和代理。
在Bean的创建过程中,如果目标Bean需要被代理,则会把它包装成代理对象并放入三级缓存中。具体地,在AbstractAutoProxyCreator类的postProcessAfterInitialization()方法中,会调用wrapIfNecessary()方法对目标Bean进行代理封装,并将代理对象放入三级缓存(singletonFactories)中。当所有的Bean都创建完成后,Spring会遍历三级缓存中的所有ObjectFactory并调用getObject()方法获取Bean实例,并完成初始化、依赖注入和代理包装等操作。
四、总结
Spring框架中,解决循环依赖的方式主要是使用三级缓存。这种机制可以有效防止在创建Bean时出现无限递归调用的问题,同时也能够满足对Bean的延迟初始化和懒加载等需求。
具体来说,在Bean的创建过程中,如果发现Bean之间存在相互依赖的情况,则会将正在创建的Bean暂时存放到二级缓存(earlySingletonObjects)中,并在后续的处理中再完成它们的初始化工作。在创建过程中,如果需要为Bean添加切面或代理,则会将包装后的代理对象放入三级缓存(singletonFactories)中,以便后续的处理和获取。
在实际应用中,Spring使用BeanPostProcessor和AOP等技术来实现循环依赖的处理。其中,BeanPostProcessor是一个扩展点,允许用户在Bean创建前后进行自定义操作,而AOP则是一种面向切面编程的技术,可以将通用的功能分离出来并动态地加到目标对象上。
总体来说,Spring解决循环依赖的方式具有以下优点:
可以避免循环依赖引起的无限递归调用,减少了系统资源的消耗和时间的浪费。
支持Bean的延迟初始化和懒加载等需求,可以在需要时才真正地创建Bean实例,提高了系统的性能和响应速度。
采用了简单而灵活的缓存机制,支持多种类型的对象和依赖关系,方便用户进行自定义配置和扩展。
集成了BeanPostProcessor和AOP等技术,可以针对不同的场景和需求进行定制化的处理,具有很强的可扩展性和适应性。
但是,Spring也存在一些缺点和局限性。例如,如果应用程序中存在大量的循环依赖或复杂的依赖关系,则可能会导致缓存机制失效或出现死循环等问题。此外,三级缓存机制还可能导致内存泄漏或OOM等问题,需要特别注意。
综上所述,Spring解决循环依赖的方式虽然不是完美的,但已经被广泛应用于各种Java应用程序中,并取得了良好的效果和反馈。在使用时,用户应该结合具体的场景和需求,充分了解和掌握相关的技术和机制,以确保系统的稳定性和可靠性。




{kind=link}