Kubernetes集群部署相关
如何查看swap分区的状态
free -h,显示内存和利用率 用swapon -s可以检查特定分区,逻辑卷或文件的交换,-s是摘要的含义,用它来获取交换的详细信息,以千字节为单位 或者使用top命令 vmstat,可以用该命令查看交换和交换信息,无法查看交换的总值
用cat /proc/swaps可以查看交换信息的大小,还会显示设备方式的交换信息,以便查看设备的名称(分区,逻辑卷或文件),其类型以及它为系统提供的交换量。
想查看你想要看的进程所使用的swap只需要:
awk '/^Swap:/ {SWAP+=$2}END{print SWAP" KB"}' /proc/$(pid)/smaps
也可以使用shell统计所有进程的:
#!/bin/bash
# Get current swap usage for all running processes
# writted by guruYu
function getswap{
SUM=0
OVERALL=0
for DIR in `find /proc/ -maxdepth 1 -type d | egrep "^/proc/[0-9]"` ; do
PID=`echo $DIR | cut -d / -f 3`
PROGNAME=`ps -p $PID -o comm --no-headers`
for SWAP in `grep Swap $DIR/smaps 2>/dev/null|awk '{ print $2 }'`
do
let SUM=$SUM+$SWAP
done
echo "PID=$PID - Swap used: $SUM - {$PROGNAME )"
let OVERALL=$OVERALL+$SUM
SUM=0
done
echo "Overall swap used: $OVERALL"
}
getswap
编写完这个shell脚本,然后使用getswap|egrep -v “Swap used: 0”
kubernetes安装之证书验证有效步骤具体内容待更">Kubernetes安装之证书验证(有效步骤,具体内容待更)
怎么安装go及配置go proxy
mkdir ~/go && cd ~/go
##### 下载go压缩包
wget <https://studygolang.com/dl/golang/go1.18.3.linux-amd64.tar.gz>
###### 执行解压
tar -C /usr/local/ -zxvf go1.18.3.linux-amd64.tar.gz
###### 设置环境变量,使其生效
vim /etc/profile
# 在最后一行添加
export GOROOT=/usr/local/go
export PATH=$PATH;$GOROOT/bin
# 保存退出后source使其生效
source /etc/profile
kubernetes集群部署的全流程">Kubernetes集群部署的全流程
- 01初始化系统和全局变量
- 添加节点信任关系
本操作只需要在zhangjun-k8s-01节点上进行,设置root账户可以无密码登录所有节点:
ssh-keygen -t rsz
ssh-copy-id root@zhangjun-k8s-01
ssh-copy-id root@zhangjun-k8s-02
ssh-copy-id root@zhangjun-k8s-03
- 更新PATH变量
echo 'PATH=/opt/k8s/bin:$PATH' >>/root/.bashrc
source /root/.bashrc
- 安装依赖包
yum install -y epel-release
yum install -y chrony conntrack ipvsadm jq iptables curl sysstat libseccomp wget socat git
本文档的kube-proxy使用ipvs模式,ipvsadm为ipvs的管理工具
etcd集群各机器需要时间同步,chrony用于系统时间同步
- 关闭防火墙
关闭防火墙,清除防火墙,设置默认转发策略
systemctl stop firewalld
systemctl disable firewalld
iptables -F && iptables -X && iptables -F -t nat && iptables -X -t nat
iptables -P FORWARD ACCEPT
- 关闭swap分区
关闭swap分区,否则kubelet会启动失败(可以设置kubelet启动参数 --fail-swap-on为false关闭swap检查):
swapoff -a
sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab
- 关闭SELinux
setenforce 0
sed -i 's/^SELINUX=.*/SELINUX=disabled/' /etc/selinux/config
- 优化内核参数
cat > kubernetes.conf <<EOF
net.bridge.bridge-nf-call-iptables=1
net.bridge.bridge-nf-call-ip6tables=1
net.ipv4.ip_forward=1
net.ipv4.tcp_tw_recycle=0
net.ipv4.neigh.default.gc_thresh1=1024
net.ipv4.neigh.default.gc_thresh2=2048
net.ipv4.neigh.default.gc_thresh3=4096
vm.swappiness=0
vm.overcommit_memory=1
vm.panic_on_oom=0
fs.inotify.max_user_instances=8192
fs.inotify.max_user_watches=1048676
fs.file-max=52706963
fs.nr_open=52706963
net.ipv6.conf.all.disable_ipv6=1
net.netfilter.nf_conntrack_max=2310720
EOF
cp kubernetes.conf /etc/sysctl.d/kubernetes.conf
sysctl -p /etc/sysctl.d/kubernetes.conf
关闭tcp_tw_recycle,否则与NAT冲突,可能导致服务不通;
- 设置系统时区
`timedatectl set-timezone Asia/Shanghai`
- 设置系统时钟同步
systemctl enable chronyd
systemctl start chronyd
查看同步状态:
`timedatectl status`
输出:
System clock synchronized: yes
NTP service: active
RTC in local TZL: no
`System clock synchronized: yes`,表示时钟同步服务;
# 将当前的UTC时间写入硬件时钟
timedatactl set-local-rtc 0
# 重启依赖于系统时间的服务
systemctl restart rsyslog
systemctl restart crond
- 关闭无关的服务
`systemctl stop postfix && systemctl disable postfix`
- 创建相关目录
`mkdir -p /opt/k8s/{bin,work} /etc/{kubernetes,etcd}/cert`
- 分发集群配置参数脚本
后续使用的环境变量都定义在`enviroment.sh`中,请根据自己的机器、网络情况修改。然后拷贝到所有的节点:
source enviroment.sh #先修改
for node_ip in ${NODE_IPS[@]}
do
echo ">>> ${node_ip}"
scp enviroment.sh root@${node_ip}:/opt/k8s/bin/
ssh root@{node_ip} "chmod +x /opt/k8s/bin/*"
done
- 升级内核 Centos7.x系统自带的3.10.x内核存在一些Bugs,导致运行Docker、Kubernetes不稳定,例如:
- 高版本的docker(1.13以后)启用3.10kernel实验支持kernel memory account功能(无法关闭),当节点压力大如频繁启动和停止容器时会导致cgroup memory leak;
- 网络设备引用计数泄露,会导致类似于报错:“kernel:unregister_netdevice:waiting for eth0 to become free. Usage count=1”;
解决方案如下:
- 升级内核到4.4.X以上;
- 或者手动编译内核,disable CONFIG_MEMCG_KMEM特性;
- 或者,安装修复了该总是的Docker 18.09及以上版本。但由于也会设置kmem(它vendor了runc),所以需要重新编译kubelet并指定GOFLAGS="-tag=nokmem";
git clone --branch v1.14.1 --single-branch --depth 1 <https://github.com/kubernetes/kubernetes>
cd kubernetes
KUBE_GIT_VERSION=v1.14.1 ./build/run.sh make kubelet GOFLAGS="-tags=nokmem"
由于我使用的是腾讯云的服务器,通过升级内核方法来解决问题,具体:
查看当前内核
$ uname -sr Linux 3.10.0-1160.25.1.el7.x86_64
查看操作系统版本
$ cat /etc/redhat-release CentOS Linux release 7.9.2009 (Core)
导入 ELRepo 仓库的公共密钥
$ rpm –import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org
安装 ELRepo 仓库的 yum 源
$ yum install -y https://www.elrepo.org/elrepo-release-7.el7.elrepo.noarch.rpm
替换为清华 ELRepo 源
sed -i "s/mirrorlist=/#mirrorlist=/g" /etc/yum.repos.d/elrepo.repo
sed -i "s#elrepo.org/linux#mirrors.tuna.tsinghua.edu.cn/elrepo#g" /etc/yum.repos.d/elrepo.repo
(可选) 更新 yum 缓存
$ yum makecache
# 查看可用的内核版本,kernel-ml(mainline stable):稳定主线版本,kernel-lt(long term support):长期支持版本
$ yum --disablerepo="*" --enablerepo="elrepo-kernel" list available
已加载插件:fastestmirror, langpacks
Repository base is listed more than once in the configuration
Repository updates is listed more than once in the configuration
Repository extras is listed more than once in the configuration
Repository centosplus is listed more than once in the configuration
Loading mirror speeds from cached hostfile
- elrepo-kernel: linux-mirrors.fnal.gov
可安装的软件包
kernel-lt.x86_64 5.4.127-1.el7.elrepo elrepo-kernel
kernel-lt-devel.x86_64 5.4.127-1.el7.elrepo elrepo-kernel
kernel-lt-doc.noarch 5.4.127-1.el7.elrepo elrepo-kernel
kernel-lt-headers.x86_64 5.4.127-1.el7.elrepo elrepo-kernel
kernel-lt-tools.x86_64 5.4.127-1.el7.elrepo elrepo-kernel
kernel-lt-tools-libs.x86_64 5.4.127-1.el7.elrepo elrepo-kernel
kernel-lt-tools-libs-devel.x86_64 5.4.127-1.el7.elrepo elrepo-kernel
kernel-ml.x86_64 5.12.12-1.el7.elrepo elrepo-kernel
kernel-ml-devel.x86_64 5.12.12-1.el7.elrepo elrepo-kernel
kernel-ml-doc.noarch 5.12.12-1.el7.elrepo elrepo-kernel
kernel-ml-headers.x86_64 5.12.12-1.el7.elrepo elrepo-kernel
kernel-ml-tools.x86_64 5.12.12-1.el7.elrepo elrepo-kernel
kernel-ml-tools-libs.x86_64 5.12.12-1.el7.elrepo elrepo-kernel
kernel-ml-tools-libs-devel.x86_64 5.12.12-1.el7.elrepo elrepo-kernel
perf.x86_64 5.12.12-1.el7.elrepo elrepo-kernel
python-perf.x86_64 5.12.12-1.el7.elrepo elrepo-kernel
升级为主线版本
$ yum --enablerepo=elrepo-kernel install kernel-ml -y
配置开机启动加载:
查看可用内核版本及启动顺序
$ sudo awk -F\' '$1=="menuentry " {print i++ " : " $2}' /boot/grub2/grub.cfg
查看启动顺序
$ yum install -y grub2-pc
$ grub2-editenv list
设置开机启动
$ grub2-set-default 0
或者
$ grub2-mkconfig -o /boot/grub2/grub.cfg
重启生效
$ reboot
重启后查看内核版本
$ uname -sr
pod中Service能够被访问,可以用什么方式?
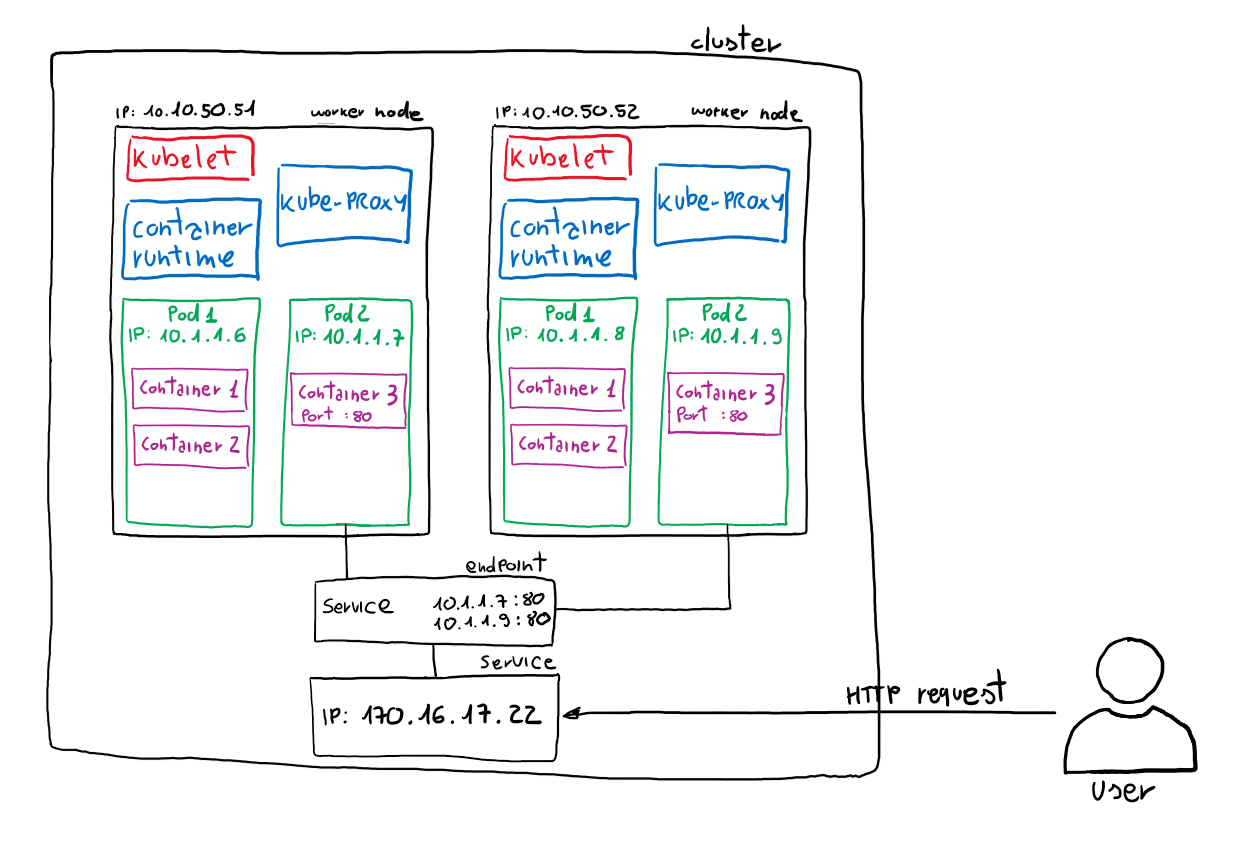
固定的绑定一个my-service.my-namespace.svc.cluster.local或者是my-service.my-namespace.pod.cluster.local,这里面为啥用这个名称作为service解析到的DNS的地址,这个与外网域名绑定到对应ip地址,这也是DNS地址,DNS地址可以由域名解析到服务部署到的ip地址,所以,它能解决的问题,看文章解读,如果用ipvc模式,pod没有固定的ip地址,所以你要解决能访问到pod的方式,用插件也是在解决这个问题。如果pod要有固定的静态ip地址的话,是另一种可以从外部访问service上pod地址的方式。spec下面设置的selector的作用是只针对设置的hostnames的服务下的pod来做操作。实际上是linux的一个模块,会把所有的pod的映射地址通过iptables来进行查询,如果pod数量太多,这个iptables查询维护的成本就非常高了,会损耗linux的性能,所以建立指定模式为ipvs。
Services、Endpoints和pods之间的关系
selector选中的pod,被称为Service的Endpoints,可以用命令kubectl get ep命令查看它们。kubectl get endpoints hostnames,要注意只处于Running状态,且readinessProbe检查通过的Pod,才会出现在Service的Endpoints列表里。并且,当某一个pod出现问题时,Kubernetes会自动把它从Service里摘除掉。用命令kubectl get svc hostnames,这个VIP就是pod的固定ip地址是kubernetes自动为service分配的。这也印证了Service提供的是Round Robin方式的负载均衡。对于这种方式,我们称之为:ClusterIP模式的Service。
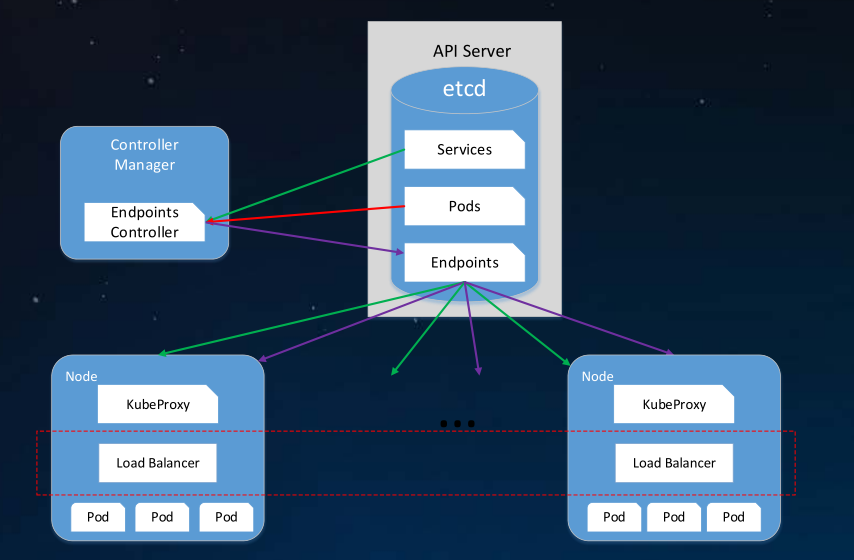
实际上Service是由kube-proxy和iptables来共同实现的。一旦创建hostnames的Service,一旦提交给Kubernetes,那么kube-proxy就可以通过Service的Informer模块感知到这个Service对象的添加。
Services的内部逻辑
而作为对事件的响应,它就会在宿主机上创建这样一条iptables规则,可以通过命令iptables-save看到它。另外一种方式是pod规则的首条作为响应的DNS的ip地址。按照概率来确保命中率吗?设置三分之一、二分之一和1。DNAT规则的作用,就是在PREROUTING检查点前,也就是在路由之前,将流入IP包的目的地址和端口改成-to-destination所指定的新的目的地址和端口。可以看到,这个目的地址和端口,正是被代理的Pod的IP地址和端口。kube-proxy维护刷新iptables。而替代方式是因为IPVS模式跟kube-proxy和iptables共同作用的模式是类似的,但是会提高性能,实际就是创建一个虚拟网卡(叫做:kube-ipvs0),并为它分配Service VIP作为IP地址。用命令ip addr可以查看,轮询模式来作为负载均衡策略,这种负载均衡的情况可以用ipvadmin查看这些设置。相比于iptables这种模式,IPVS在内核中实现其实也是基于Nefilter的NAT模式,所以在转发这一层上,理论上IPVS并没有显著的提升。但是IPVS并不需要在宿主机上为每个Pod设置iptables规则,而是把对这些规则的处理放到内核态,从而极大降低了维护这些规则的代价。侧面印证了把重要操作放入内核态的重要提高性能的手段。也需要注意IPVS只负责所述负载均衡和代理功能。而一个完整的Service流程正常工作所需要的包过滤、SNAT等操作,还要依靠iptables来实现。只不过,这些辅助iptables规则数量有限,也不会随着pod的增加而增加,所以对于大规模集群里,建立针对kube-proxy设置-proxy-mode=ipvs,会带给kubernetes集群规模带来提升是非常巨大。另一种模式是ClusterIP模式,会添加如my-service.my-namespace.svc.cluster.local格式的A记录,Service就可以解析到VIP地址,而对于ClusterIP=None或者Headless Service来说,它的A记录格式是:my-service.my-namespace.pod.cluster.local,这种记录作用是指向Pod的IP地址。如果指定成Headless Service时,A记录的格式是pod的hostname.svc.cluster.local,比如如下示例:
apiVersion:v1
kind:Service
metadata:
name:default-subdomain
spec:
selector:
name:busybox
clusterIP:None
ports:
- name:foo
port:1234
targetPort:1234
---
apiVersion:v1
kind:Pod
metadata:
name:busybox1
labels:
name:busybox
spec:
hostname:busybox-1
subdomain:default-subdomain
在上面的Service和Pod被创建之后,你就可以通过busybox-1.default-subdomain.default.svc.cluster.local解析到这个Pod的IP地址了。这里需要注意的是,kubernetes里/etc/hosts文件是单独挂载的,这也是为什么kubelet能够对hostname进行修改并且Pod重建之后仍然有效的原因。这跟Docker的init层是一个原理。
kubectl及minikube工具">centos安装kubectl及minikube工具
kubernetes指定版本的方式">1.获取kubernetes指定版本的方式
这是安装最新版本的
方式1:curl -LO “https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl”方式2:curl -LO https://storage.googleapis.com/kubernetes-release/release/`curl -s https://storage.googleapis.com/kubernetes-release/release/stable.txt`/bin/linux/amd64/kubectl
这是安装指定版本的
curl -LO https://storage.googleapis.com/kubernetes-release/release/v1.17.0/bin/linux/amd64/kubectl
2.增加执行权限
chmod +x /usr/local/bin/kubectl
3.把安装包移到path目录
mv ./kubectl /usr/local/bin/kubectl
kubernetes都建议关闭swap">为什么Kubernetes都建议关闭swap?
答:因为会降低性能,IO和内存。另一个是管理问题,开启swap后通过cgroups设置的内存上限就会失效,有时内存也会有很多swap,这时关闭是为了避免swap带来的性能问题。
Sar是后台进程sadc的前端显示工具,安装名为sysstat的包后,sadc就会自动从内核收集报告并保存。安装这个工具之后,再用命令sar -r -S 1,该命令含义是数字代表间隔1秒输出一组数据,-r显示内存的使用情况,-S表示显示Swap的使用情况。在内存紧张时,Linux会通过内存回收和定期扫描的方式,来释放文件页和匿名页,以便把内存分配给更需要的进程使用。
- 文件页的回收比较容易理解,直接清空缓存,或者把脏数据写回磁盘后,再释放缓存就可以了
- 而对不常访问的匿名页,则需要Swap换到磁盘中,这样在下次访问在的时候,再从磁盘换入到内存中就可以了。
开启Swap后,你可以设置/proc/sys/vm/min_free_kbytes,来调整系统定期回收内存的阀值,也可以设置/proc/sys/vm/swappiness,来调整文件页和匿名页的回收倾向。
关闭具体操作的步骤:
swapoff -avim /etc/fstab,找形如/swapfile swap swap defaults 0 0的行,把它注释掉reboot,之后用命令free -h查看,显示如下图,说明已经正确关闭了。

关闭之后如图显示要swap都为0
如何在Linux系统上安装nfs文件挂载系统?
启动NFS客户端
Centos:
sudo yum install nfs-utils
NFS v4.0挂载:
sudo mount -t nfs -o vers=4 <挂载点IP>:/share/nfs/<文件系统名称即bucket名称> <待挂载目标目录>
calico的理解">说说对Calico的理解
答:它是一种开源网络和网络安全解决方案,适用于容器,虚拟机和基于主机的本机工作负载。Calico支持广泛平台,包括Kubernetes、Docker、OpenStack和裸机服务。Calico后端支持多种网络模式。
Linux如何保护重要进程不被OOM Killer干掉?
Linux给每个运行中的进程分配一个叫oom_score的分数,它表示一个系统可用内存很低的时候,一个进程被kill的可能性有多大。分数越高,越可能被kill。分数值很简单:等于进程的内存占用的百分比乘以10。比如一个进程占50%的内存,它的oom_score值就是50*10=500。
如何避免呢?因为OOM Killer会检查/proc/$pid/oom_score_adj文件来调整最终的分数oom_score
OOM Killer的权重是从-1000到1000,权重高的话,那么,内存占用光了也不会把它杀死,所以,如果你想登录ssh永远不受OOM Killer机制的自动调整而被杀死的话,那么,你就调整/proc/${pid}/sshd的权限为高一点就可以。
公网IP和内网IP的区别?
举个例子,路由器以内,所有使用的设备都会分配一个ip地址,而路由器外部的就是公网。这个外网IP通常在路由器上的WAN口上,如果你路由器使用透明模式、桥接模式等。
可以查看sshd应用运行端口的方法?
- 第一种方式:
netstat -nlp | grep sshd - 第二种方式:
lsof -nPi -sTCP:LISTEN - 第三种方式;
cat /var/run/sshd.pid
kubernetes中如何把你的应用和traefik联系起来">在kubernetes中如何把你的应用和traefik联系起来?
通过之前针对wordpress配置的traefik边缘路由,看得出来,traefik应该作为流量入口,把从traefik捕捉到的流量请求转发到后端你部署的相关应用上面。所以,一般来测试你的kubernetes部署是否有效的测试方法都是,开一个简单、方便测试的应用,然后部署好traefik边缘路由网络来作为k8s的ingress,当traefik捕获到外部流量请求的时候,treafik再把请求转发到你部署的相应应用上面。一般来说,可以用whoami镜像作为测试部署服务,把traefik捕获到的流量转发到whoami部署处做具体的处理。在k8s中用labels标签下的app:traefik标签来标识该应用正在使用traefik做流量分发,这和我在部署wordpress时候,使用wodby封闭版本nginx时,要在其lables部分声明"traefik.enable=true"应该是一个含义。
version: "3.8"
services:
...
...
nginx:
image: wodby/nginx:latest
...
...
deploy:
mode: global
update_config:
parallelism: 1
delay: 10s
restart_policy:
condition: on-failure
labels:
- "traefik.enable=true"
- "traefik.http.routers.nginx.entrypoints=web"
- "traefik.http.routers.nginx.rule=Host(`blog.famou.local.com`)"
- "traefik.http.middlewares.nginx-https-redirect.redirectscheme.scheme=https"
- "traefik.http.routers.nginx.middlewares=nginx-https-redirect"
- "traefik.http.routers.nginx-secure.entrypoints=websecure"
- "traefik.http.routers.nginx-secure.rule=Host(`blog.famou.local.com`)"
- "traefik.http.routers.nginx-secure.tls=true"
- "traefik.http.routers.nginx-secure.service=nginx"
- "traefik.http.services.nginx.loadbalancer.server.port=80"
# Define middleware to enable gzip compression
- "traefik.http.middlewares.nginx_compress.compress=true"
# Associate that middleware with relevant routers.
- "traefik.http.routers.nginx.middlewares=nginx_compress"
- "traefik.http.middlewares.nginx-https-redirect.redirectscheme.permanent=true"
创建的具体步骤:
1、创建CRD资源
在Traefik v2.0版本之后,开始使用CRD(CUSTOM Resource Definition)来完成路由配置等,所以要提前创建CRD资源。
# 创建traefik-crd.yaml文件
apiVersion:apiextensions.k8s.io/v1beta1
kind:CustomResourceDefinition
metadata:
# 名字必需与下面的spec字段匹配,并且格式为'<名称的复数形式>.<组名>'
name: ingressroutes.traefik.containo.us
spec:
# 组名称,用于REST API: /apis/<组>/<版本>
group: traefik.containo.us
# 列举此CustomResourceDefinition所支持的版本
# 每个版本都可以通过served标志来独立启用或禁止,如:served: true
version: v1alpha1
names:
kind: IngressRoute
plural: ingressroutes
singular: ingressroute
# 可以是Namespaced或Cluster
scope: Namespaced
---
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
name: middlewares.traefik.containo.us
spec:
group: traefik.containo.us
version: v1alpha1
names:
# 通常是单数形式的帕斯卡编码(PascalCased)形式。你的资源清单会使用这一形式
kind: Middleware
plural: middlewares
# 名称的单数形式,作为命令行使用时和显示时的别名
singular: middleware
scope: Namespaced
---
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
name: ingressrouteudps.traefik.containo.us
spec:
group: traefik.containo.us
version: v1alpha1
names:
kind: IngressRouteUDP
plural: ingressrouteudps
singular: ingressrouteudp
scope: Namespaced
---
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
name: tlsoptions.traefik.containo.us
spec:
group: traefik.containo.us
version: v1alpha1
names:
kind: TLSOption
plural: tlsoptions
singular: tlsoption
scope: Namespaced
---
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
name: tlsstores.traefik.containo.us
spec:
group: traefik.containo.us
version: v1alpha1
names:
kind: TLSStore
plural: tlsstores
singular: tlsstore
scope: Namespaced
---
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
name: traefikservices.traefik.containo.us
spec:
group: traefik.containo.us
version: v1alpha1
names:
kind: TraefikService
plural: traefikservices
singular: traefikservice
scope: Namespaced
---
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
name: serverstransports.traefik.containo.us
spec:
group: traefik.containo.us
version: v1alpha1
names:
kind: ServersTransport
plural: serverstransports
singular: serverstransport
scope: Namespaced
# 创建Traefik CRD资源
kubectl apply -f traefik-crd.yaml
2、创建RBAC权限
Kubernetes在1.6版本中引入了基于角色的访问控制(RBAC)策略,方便对Kubernetes资源和API进行细粒度控制。Traefik需要一定的权限,所以,这里提前创建好Traefik ServiceAccount并分配一定的权限.
# 创建traefik-rbac.yaml文件
## ServiceAccount
apiVersion: v1
kind: ServiceAccount
metadata:
namespace: kube-system
name: traefik-ingress-controller
---
ClusterRole
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: traefik-ingress-controller
namespace: kube-system
rules:
- apiGroups:
- ""
resources:
- services
- endpoints
- secrets
verbs:
- get
- list
- watch
- apiGroups:
- extensions
- networking.k8s.io
resources:
- ingresses
- ingressclass
verbs:
- get
- list
- watch
- apiGroups:
- extensions
- networking.k8s.io
resources:
- ingresses/status
verbs:
- update
- apiGroups:
- traefik.containo.us
resources:
- ingressroutes
- ingressroutetcps
- ingressrouteudps
- middlewares
- tlsoptions
- tlsstores
- traefikservices
- serverstransports
verbs:
- get
- list
- watch
- apiGroups:
- networking.x-k8s.io
resources:
- gatewayclasses
- gatewayclasses/status
- gateways
verbs:
- get
- list
- watch
- apiGroups:
- networking.x-k9s.io
resources:
- getewayclasses/status
verbs:
- get
- list
- watch
- apiGroups:
- networking.x-k8s.io
resources:
- gatewayclasses/status
verbs:
- get
- patch
- update
- apiGroups:
- networking.x-k8s.io
resources:
- httproutes
verbs:
- create
- delete
- get
- list
- patch
- update
- watch
- apiGroups:
- networking.x-k8s.io
resources:
- httproutes/status
verbs:
- get
- patch
- update
---
ClusterRoleBinding
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: traefik-ingress-controller
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: traefik-ingress-controller
subjects:
- kind: ServiceAccount
name: traefik-ingress-controller
namespace: kube-system
verbs
<b># 创建Traefik RBAC资源</b>
- -n:指定部署Namespace
`kubectl apply -f traefik-rbac.yaml -n kube-system`
traefik配置文件">3、创建Traefik配置文件
由于Traefik配置很多,通过CLI定义不是很方便,一般时候都会通过配置文件配置Traefik参数,然后存入ConfigMap,将其挂入Traefik中。
# 创建traefik-config.yaml文件
下面配置中可以通过配置kubernetesCRD与kubernetesIngress和kubernetesGateway三项参数,让Traefik支持CRD、Ingress与kubernetesGateway三种路由配置方式。
kind: ConfigMap
apiVersion: v1
metadata:
name: traefik-config
data:
traefik.yaml: |-
ping: "" ##启用ping
serversTransport:
insecureSkipVerify: true //Traefik忽略验证代理服务的TLS证书
api:
insecure: true ## 允许HTTP方式访问 API
dashboard: true ## 启用Dashboard
debug: false
metrics:
prometheus: "" ##配置Prometheus监控指标数据,并使用默认配置
entryPoints:
web:
address: ":80" ##配置80端口,并设置入口名称为web
websecure:
address: ":443" ##配置443端口,并设置入口名称为websecure
providers:
kubernetesCRD: "" ##启用Kubernetes CRD方式来配置路由规则
kubernetesIngress: "" ##启用Kubernetes Ingress方式来配置路由规则
kubernetesGateway: "" ##启用Kubernetes Gateway API
experimental:
kubernetesGateway: true ##允许使用Kubernetes Gateway API
log:
filePath: "" ##设置调试日志文件存储路径,如果为空则输出到控制台
level: error ##设置调试日志级别
format: json ##设置调试日志格式
accessLog:
filePath: "" ##设置访问日志文件存储路径,如果为空则输出到控制台
format: json ##设置访问调试日志格式
bufferingSize: 0 ##设置访问日志缓存行数
filters:
#statusCodes: ["200"] ##设置只保留指定状态码范围的访问日志
retryAttempts: true ##设置代理访问重试失败时,保留访问日志
minDuration:20 ##设置保留请求时间超过指定持续时间的访问日志
fields: ##设置访问日志中的字段是否保留(keep保留、drop不保留)
defaultMode: keep ##设置默认保留访问日志字段
names:
ClientUsername: drop
headers: ##设置headers中字段是否保留
defaultMode: keep ##设置默认保留headers中字段
names:
User-Agent: redact
Authorization: drop
Content-Type: keep
tracing: ##链路追踪配置,支持zipkin、datadog、jaeger、instana、haystack等
serviceName: ##设置服务名称(支持链路追踪端收集后显示的服务名)
zipkin: ##zipkin配置
sameSpan: true ##是否启用Zipkin SameSpan RPC类型追踪方式
id128Bit: true ##是否启用Zipkin 128bit的追踪ID
sampleRate: 0.1 ##设置链路日志的采样率(可以配置0.0到1.0之间的值)
httpEndpoints: <http://localhost:9411/api/v2/spans> ##配置Zipkin Server端点
<b>创建Traefik ConfigMap资源</b>
- -n:指定程序启动的Namespace
`kubectl apply -f traefik-config.yaml -n kube-system`
##### 节点设置Label标签
由于是`Kubernetes DeamonSet`这种方式部署`Traefik`,所以需要提前给节点设置`Label`,这样当程序部署时会自动调度到设置`Label`的节点上。
<b># 节点设置Label标签</b>
- 格式:`kubectl label nodes [节点名][key=value]`
`kubectl lable nodes k8s-node-2-12 IngressProxy=true`
<b># 查看节点是否设置`Label`成功</b>
`kubectl get nodes --show-labels`

<p class="caption">查看节点之后的返回</p>
##### 5、安装Kubernetes Gateway CRD资源
由于目前Kubernetes集群默认没有安装Service APIs,我们需要提前安装Gateway API的CRD资源,需要确保在Traefik安装之前启用Service APIs资源。
`kubectl apply -k "github.com/kubernetes-sigs/service-apis/config/crd?ref=v0.4.0"`
##### 6、Kubernetes部署Traefik
下面将用`DaemonSet`方式部署`Traefik`,便于在多服务器间扩展,用`hostport`方式绑定服务器`80、443`端口,方便流量通过物理机进入`Kubernetes`内部。
<b># 创建traefik部署traefik-deploy.yaml文件</b>
apiVersion: v1
kind: Service
metadata:
name: traefik
labels:
app: traefik
spec:
ports:
- name:web
port: 80
- name: websecure
port: 443
- name: admin
port: 8080
selector:
app: traefik
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: traefik-ingress-controller
labels:
app: traefik
spec:
selector:
matchLabels:
app: traefik
template:
metadata:
name: traefik
labels:
app: traefik
spec:
serviceAccountName: traefik-ingress-controller
terminationGracePeriodSeconds: 1
containers:
- image: traefik:v2.4.3
name: traefik-ingress-lb
ports:
- name: web
containerPort:80
hostPort: 80 ##将容器端口绑定所在服务器的80端口
- name: websecure
containerPort: 443
hostPort: 443 ##将容器端口绑定所在服务器的443端口
- name: admin
containerPort: 8080 ##Traefik Dashboard端口
resources:
limits:
cup: 2000m
memory: 1024Mi
requests:
cpu: 1000m
memory: 1024Mi
securityContext:
capabilities:
drop:
- ALL
add:
- NET_BIND_SERVICE
args:
- --configfile=/config/traefik.yaml
volumeMounts:
- mountPath: "/config"
name: "config"
readinessProbe:
httpGet:
path: /ping
port: 8080
failureThreshold: 3 ##当探测失败时,Kubernetes的重试次数。对存活探测而言,放弃就意味着重新启动容器。对就绪探测而言,放弃意味着Pod会被打上未就绪的标签。默认值是3。最小值是1。
initialDelaySeconds: 10 ##容器启动后要等待多少秒后才启动存活和就绪探测器,默认是0秒,最小值是0
periodSeconds: 10 ##执行探测的时间间隔(单位是秒),默认是10秒。最小值是1
successThreshold: 1 ##探测器失败后,被视为成功的最小连接成功数。默认值是1.;存活和启动探测的这个值必须是1。最小值是1。
timeoutSeconds: 5 ##探测的超时后等待多少秒。默认值是1秒。最小值是1
livenessProbe: ##活跃(Liveness)、就绪(Readiness)和启动(Startup)探测器
httpGet:
path: /ping
port: 8080
failureThreshold: 3
initialDelaySeconds: 10
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 5
volumes:
- name: config
configMap:
name: traefik-config
tolerations:
- operator: "Exists"
nodeSelector:
IngressProxy: "true"
# Kubernetes部署Traefik
kubectl apply -f traefik-deploy.yaml -n kube-system
到此Traefik v2.4应用已经部署完成。
四、配置路由规则
Traefik应用已经部署完成,但是想让外部访问Kubernetes内部服务,还需要配置路由规则,上面部署Traefik时开启了Traefik Dashboard,这是Traefik提供的视图看板,所以,首先配置基于HTTP的Traefik Dashboard路由规则,使外部能够访问Traefik Dashboard。然后,再配置基于HTTPS的Kubernete Dashboard的路由规则,这里分别使用CRD、Ingress和Kubernetes Gateway API三种方式进行演示。
traefik路由规则">1、方式一:使用CRD方式配置Traefik路由规则
http路由规则traefik-dashboard为例">(1)、配置HTTP路由规则(Traefik Dashboard为例)
# 创建Traefik Ingress路由规则traefik-dashboard-ingress.yaml文件
apiVersion: traefik.containo.us/v1alpha1
kind: IngressRoute
metadata:
name: traefik-dashboard-route
spec:
entryPoints:
- web
routes:
- match: Host(`traefik.mydlq.club`)
kind: Rule
services:
- name: traefik
port: 8080
# 创建Traefik Dashboard路由规则对象
kubectl apply -f traefik-dashboard-route.yaml -n kube-system
https路由规则kubernetes-dashboard为例">(2)、配置HTTPS路由规则(Kubernetes Dashboard为例)
这里我们创建Kubernetes的Dashboard看板创建路由规则,它是Https协议方式,由于它是需要使用Https请求,所以我们配置基于Https的路由规则并指定证书。
# 创建私有证书tls.key、tls.crt文件
创建自签名证书
openssl req -x509 -nodes -days 3650 -newkey rsa:2048 -keyout tls.key -out tls.crt -subj “/CN=kubernetes.mydlq.club”
kubernetes-secret中">将证书存储到Kubernetes Secret中
kubectl create secret generic cloud-mydlq-tls --from-file=tls.crt --from-file=tls.key -n kube-system
# 创建Traefik Dashboard Ingress路由规则kubernetes-dashboard-ingress.yaml文件
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: kubernetes-dashboard-ingress
namespace: kube-system
annotations:
kubernetes.io/ingress.class: traefik
traefik.ingress.kubernetes.io/router.tls: "true"
traefik.ingress.kubernetes.io/router.entrypoints: websecure
spec:
tls:
- hosts:
- kubernetes.mydlq.club
secretName: cloud-mydlq-tls
rules:
- host: kubernetes.mydlq.club
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: kubernetes-dashboard
port:
number:443
# 创建Traefik Dashboard路由规则对象
kubectl apply -f kubernetes-dashboard-ingress.yaml -n kube-system
kubernetes-gateway-api">3、方式三:使用Kubernetes Gateway API
在Traefik v2.4版本后支持Kubernetes Gateway API提供的CRD方式创建路由规则,上面已经简单介绍了Gateway是什么,这里根据该CRD资源创建路由规则进行演示。
- GatewayClass: GatewayClass是基础结构提供程序定义的群集范围的资源。此资源表示可以实例化的网关类。一般该资源是用于支持多个基础设施提供商用途的,这里我们只部署一个即可。
- Gateway:Gateway与基础设置配置的生命周期是1:1。当用户创建网关时,GatewayClass控制器会提供或配置一些负载均衡的基础设施。
- HTTPRoute:HTTPRoute是一种网关API类型,用于指定HTTP请求从网关侦听器到API对象(即服务)的路由行为。
(1)、创建GatewayClass
# 创建GatewayClass资源kubernetes-gatewayclass.yaml文件
apiVersion: networking.x-k8s.io/v1alpha1
kind: GatewayClass
metadata:
name: traefik
spec:
controller: traefik.io/gateway-controller
http路由规则traefik-dashboard为例">(2)、配置HTTP路由规则(Traefik Dashboard为例)
# 创建GatewayClass资源http-gateway.yaml文件
apiVersion: networking.x-k8s.io/v1alpha1
kind: Gateway
metadata:
name: http-gateway
namespace: kube-system
spec:
gatewayClassName: traefik
listeners:
- protocol: HTTP
port: 80
routes:
kind: HTTPRoute
port: 80
routes:
kind: HTTPRoute
namespace:
from: All
selector:
matchLabels:
app: traefik
# 创建HTTPRoute资源traefik-httproute.yaml文件
apiVersion: networking.x-k8s.io/v1alpha1
kind: HTTPRoute
metadata:
name: traefik-dashboard-httproute
namespace: kube-system
labels:
app: traefik
spec:
hostnames:
- "traefik.mydlq.club"
rules:
- matches:
- path:
type: Prefix
value: /
forwardTo:
- serviceName: traefik
port: 8080
weight: 1
http路由规则traefik-dashboard为例">(3)、配置HTTP路由规则(Traefik Dashboard为例)
跟上面创建两种路由方式一样,也需要创建使用证书,然后再结合Gateway和HTTPRoute方式创建路由规则。
#创建私有证书tls.key、tls.crt文件
创建自签名证书
openssl req -x509 -nodes -days 3650 -newkey rsa:2048 -keyout tls.key -out tls.crt -subj "/CN=kubernetes.mydlq.club"
kubernetes-secret中-1">将证书存储到Kubernetes Secret中
kubectl create secret generic cloud-mydlq-tls --from-file=tls.crt --from-file=tls.key -n kube-system
#创建Gateway资源https-gateway.yaml文件
apiVersion: networking.x-k8s.io/v1alpha1
kind: Gateway
metadata:
name: https-gateway
spec:
gatewayClassName: traefik
listeners:
\- protocol: HTTPS
port: 443
hostname: kubernetes.mydlq.club
tls:
certificateRef:
kind: secret
group: core
name: cloud-mydlq-tls
routeOverride:
certificate: Deny
routes:
kind: HTTPRoute
namespaces:
from: All
selector:
matchLabels:
app: traefik
#创建HTTPRoute资源kubernetes-httproute.yaml文件
apiVersion: networking.x-k8s.io/v1alpha1
kind: HTTPRoute
metadata:
name: kubernetes-dashboard-httproute
namespace: kube-system
labels:
app: traefik
spec:
hostname:
\- "kubernetes.mydlq.club"
rules:
\- matches:
\- path:
type: Prefix
value: /
forwardTo:
\- serviceName: kubernetes-dashboard
port: 443
weight: 1
五、创建路由规则后的应用
1、配置Host文件
客户端想通过域名访问服务,必须进行DNS解析,由于这里没有DNS服务器进行域名解析,所以修改hosts文件将Traefik所在节点服务器的IP和自定义Host绑定。打开电脑的Hosts配置文件,往其加入下面的配置:
192.168.2.12 traefik.mydlq.club kubernetes.mydlq.club
安装CRD过程中可能遇到的问题
答:如果是在国内的话,可能不启用代理会导致timeout报错,比如说k8s想要保证在Traefik中启用Service APIs支持Kubernetes安装的Service APIs。
kubectl apply -k "github.com/kubernetes-sigs/service-apis/config/crd?ref=v0.4.0&timeout=180s"
注意下面的timeout=180s就是指定加长的超时时间,如果你通过代理请求得到github.com但是依然timeout,可以用此种方式延长超时时间。
kubernetes-gateway-api">什么是Kubernetes Gateway API?
答:Gateway API是由SIG-NETWORK社区管理的一个开源项目,该项目目标是在Kubernetes生态内发展服务网络API,网关的API提供了用于暴露Kubernetes应用程序的Service、Ingress等。Gateway API旨在提供可表达的,可扩展的,面向角色的接口来改善服务网络,这些接口已由很多供应商实施并获得了广泛的行业支持,网关API是API资源的集合,包括GatewayClass、Gateway、HTTPRoute、TCPRoute、Service等,这些API共同为各种网络用例构建模型。其实Traefik除了支持我们手动配置TLS证书之外,还支持自动生成TLS证书。
说白了,这个Gateway API就是一套自定义CRD资源,云服务商的GatewayClass,例如阿里云,谷歌云,即内网GatewayClass和外网GatewayClass。
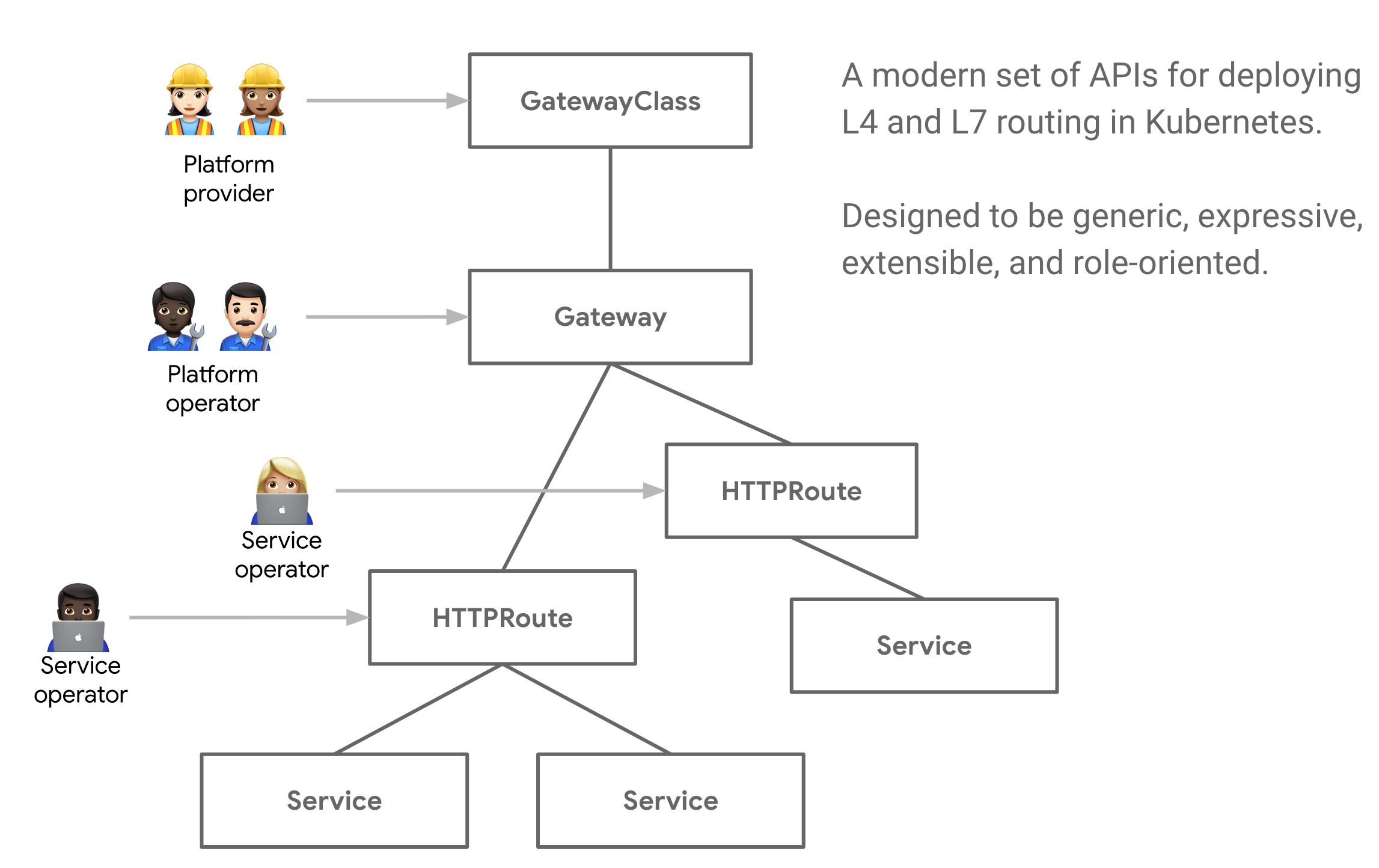
GatewayClass、Gateway、HTTPRoute等之间的关系
Gateway API的改进比当前的Ingress资源对象有很多更好的设计:
- 面向角色:Gateway由各种API资源组成,这些资源根据使用和配置Kubernetes服务网络的角色进行建模。
- 通用性:和Ingress一样是一个具有众多实现能用规范,Gateway API是一个被设计成由许多实现支持的规范标准。
- 更具表现力:Gateway API资源支持基于Header头的匹配、流量权重等核心功能,这些功能在Ingress中只能通过自定义注解才能实现。
- 可扩展性:Gateway API允许自定义资源链接到API的各个层,这就允许在API结构适当位置进行更精细的定制。
还有一些其他值得关注的功能:
- GatewayClasses:GatewayClasses将负载均衡实现的类型形式化,这些类使用户可以很容易了解到通过Kubernetes资源可以获得什么样的能力。
- 共享网关和跨命名空间支持:它们允许共享负载均衡和VIP,允许独立的路由资源绑定到同一网关,这使得团队可以安全地共享(包括跨命名空间)基础设施,而不需要直接协调。
- 规范化路由和后端:Gateway API支持类型化的路由资源和不同类型的后端,这使得API可以灵活地支持各种协议(如HTTP和gRPC)和各种后端服务(如Kubernetes Service、存储桶或函数)。
Gateway API通过对Kubernetes服务网络进行面向角色的设计来实现这一目标,平衡了灵活性和集中控制。它允许共享的网络基础设施(硬件负载均衡器、云网络、集群托管的代理等)被许多不同的团队使用,所有这些都受集群运维的各种策略和约束。下面例子显示如何实践中运行的。
面向角色服务集群的架构图
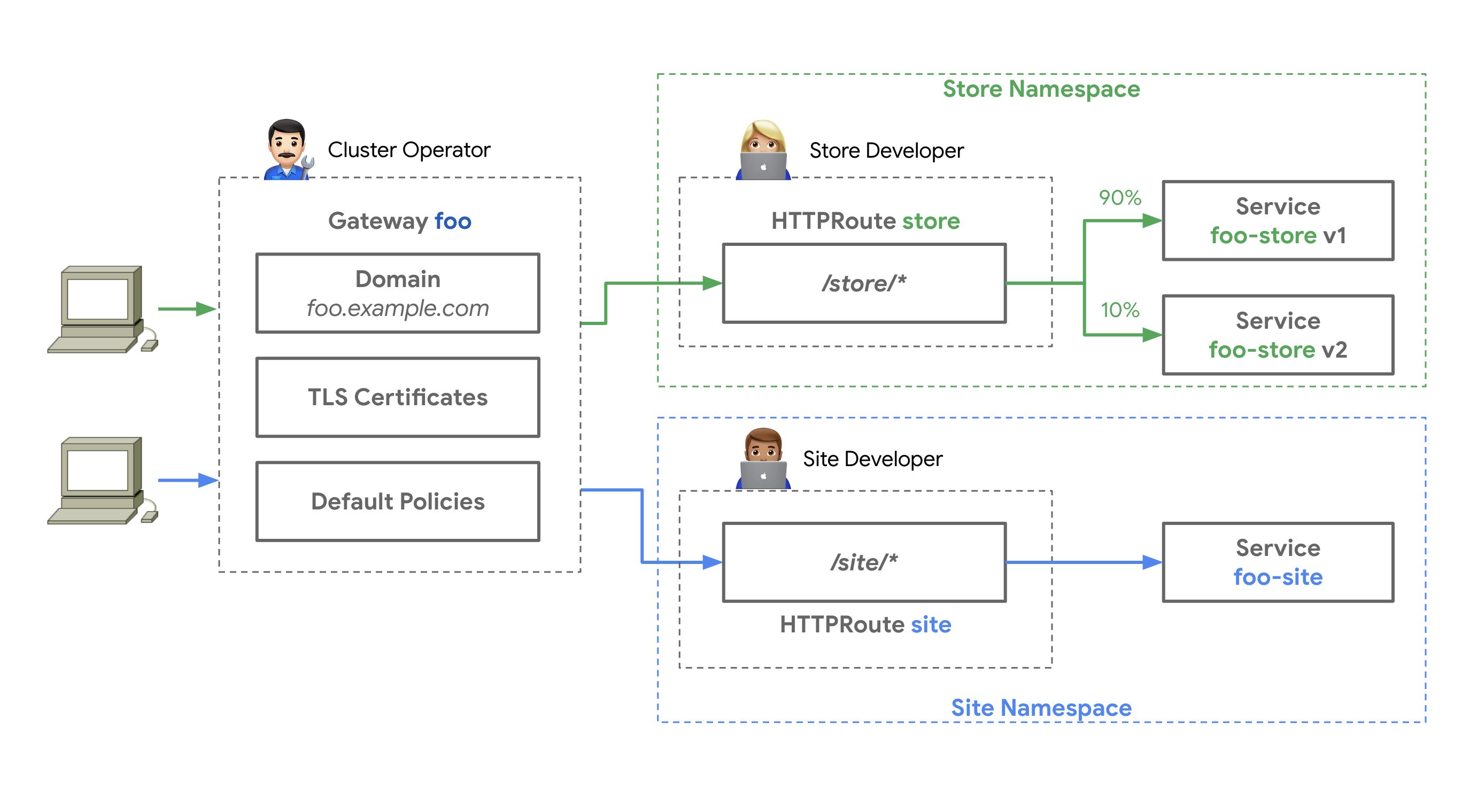
k8s中gatewayclassgatewayxroute和service如何组合形成一个负载均衡器">k8s中GatewayClass、Gateway、xRoute和Service如何组合形成一个负载均衡器?
答:
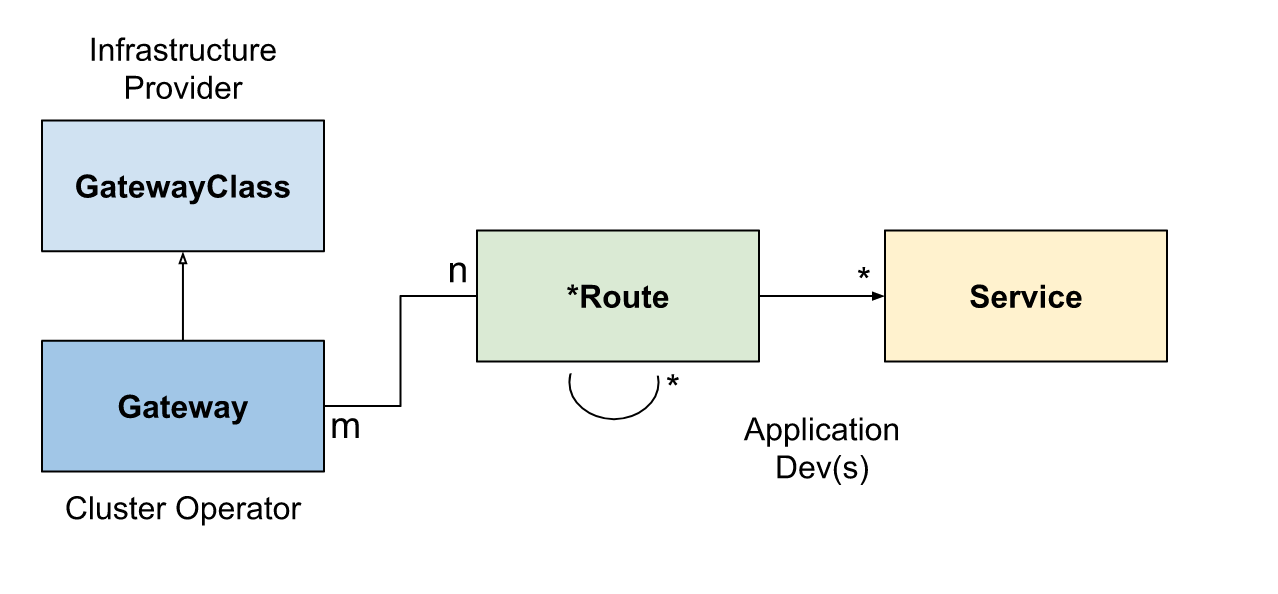
GatewayClass、Gateway、xRoute和Service的组合定义一个可实施的负载均衡器
- 客户端向相应host中声明域名发送请求
- DNS将域名解析为
Gateway网关地址 - 反向代理在监听上接收请求,并使用Host Header来匹配HTTPRoute
- (可选)反向代理可以根据HTTPRoute的匹配规则进行路由
- (可选)反向代理可以根据HTTPRoute的过滤规则修改请求,即添加或删除headers
- 最后,反向代理根据HTTPRoute的
forwardTo规则,将请求转发给集群中的一个或多个对象,即服务。
traefik使用kubernetes-service-apis进行流量路由要做什么样的环境准备">通过Traefik使用Kubernetes Service APIs进行流量路由,要做什么样的环境准备?
- 安装CRD
kubectl apply -k "github.com/kubernetes-sigs/gateway-api/config/crd?ref=v0.4.0"可以在地址https://github.com/kubernetes-sigs/gateway-api查看最新的tags。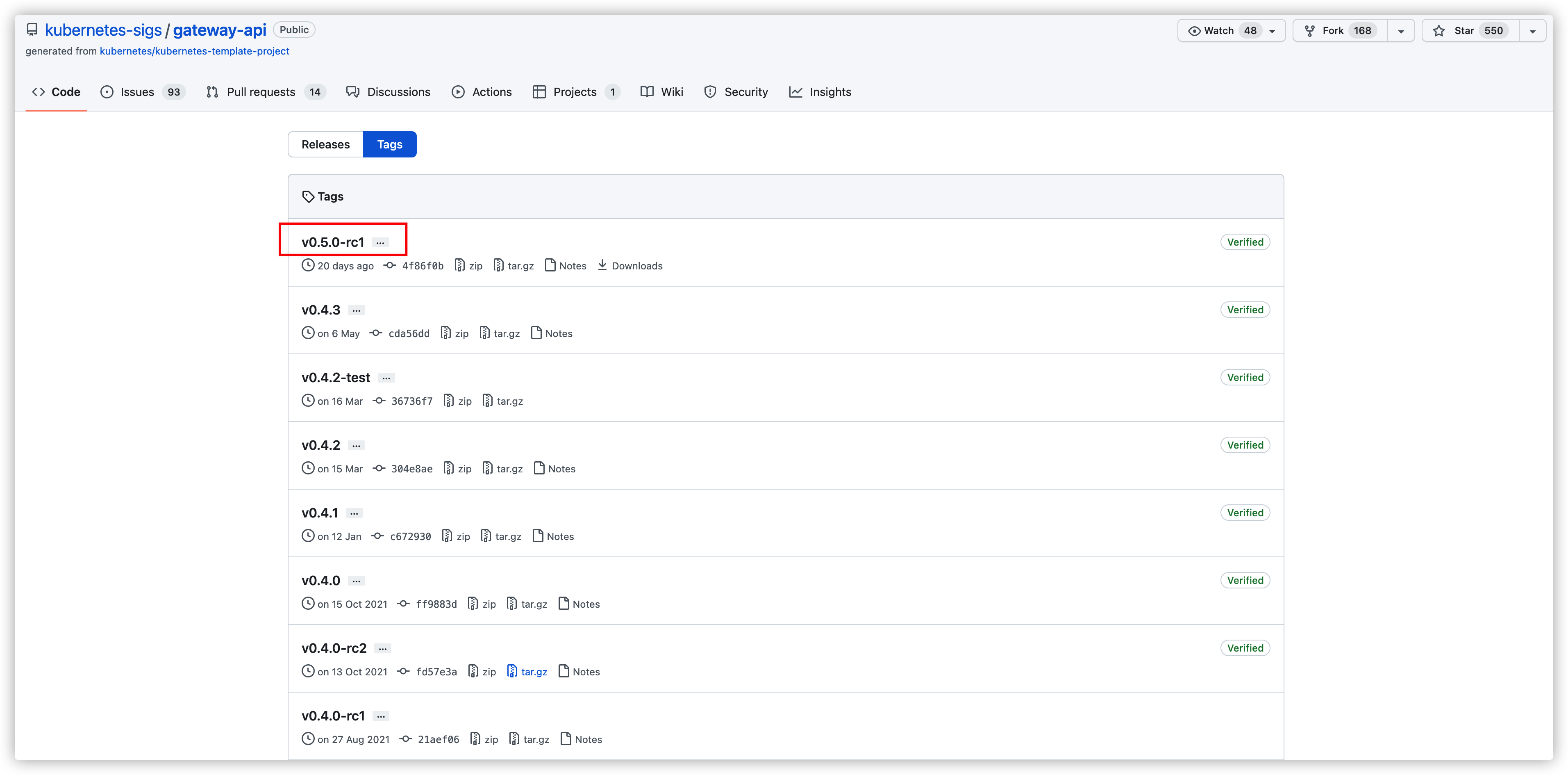
安装指定的版本
- 安装配置Traefik代理来使用Traefik API
helm repo add traefik <https://helm.traefik.io/traefik> helm repo update helm install traefik --set experimental.kubernetesGateway.enabled=true traefik/traefik
注意这里设置的--set experimental.kubernetesGateway.enabled=true参数,它的含义是安装Traefik 2.6并启用新的Service APIs Provider,还将创建GatewayClasses和一个Gateway实例。如果还有更多的定制需要,我们可以直接通过覆盖Chart包的Values值,比如可以配置label selector或者TLS证书等等。

Charts包的Values,可根据需求来定制
要验证新特征是否被启用,使用端口转发去暴露Traefik Proxy dashboard: kubectl port-forward $(kubectl get pods --selector "app.kubernetes.io/name=traefik" --output=name) 9000:9000
之后通过浏览器访问http://localhost:9000/dashboard/#/,你应该可以看到提供服务的KubernetesGateway这个Provider是激活了和准备好了服务。
浏览器访问,查看效果
- 部署一个虚拟服务
你需要Traefik Proxy可以把路径请求定向到目标,所以迅速安装著名的whoami服务,之后使用kubectl apply -f命令,以便于为测试目做好准备。
# 01-whoami.yaml
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: whoami
spec:
replicas:2
selector:
matchLabels:
app: whoami
template:
metadata:
labels:
app: whoami
spec:
containers:
\-name: whoami
image: traefik/whoadmi:v1.6.0
ports:
\- containerPort: 80
name: http
---
apiVersion: v1
kind: Service
metadata:
name: whoadmi
spec:
selector:
app: whoami
ports:
\- port: 80
targetPort: http
- 部署一个简单主机
现在所有事情都准备好了,你准备开始以下行动先要创建一个`Ingress`或者`IngressRoute`。此处,你将部署你的第一个简单`HTTPRoute`:
# 02-whoadmi-httproute.yaml
---
apiVersion: gateway.networking.k8s.io/v1alpha2
kind: HTTPRoute
metadata:
name: http-app-1
namespace: default
labels:
app: traefik
spec:
parentRefs:
\-name: traefik-gateway
hostnames:
\- whoami
rules:
\- matches:
\- path:
type: Exact
value: /
backendRefs:
\- name: whoami
port: 80
weight: 1
`HTTPRoute`会捕获请求到`whoami`主机的请求,把它们定向到到你之前部署的`whoami`服务。如果现在对此主机做个请求,你将看到一个标准的`whoami`输出,输出类似于如下的输出
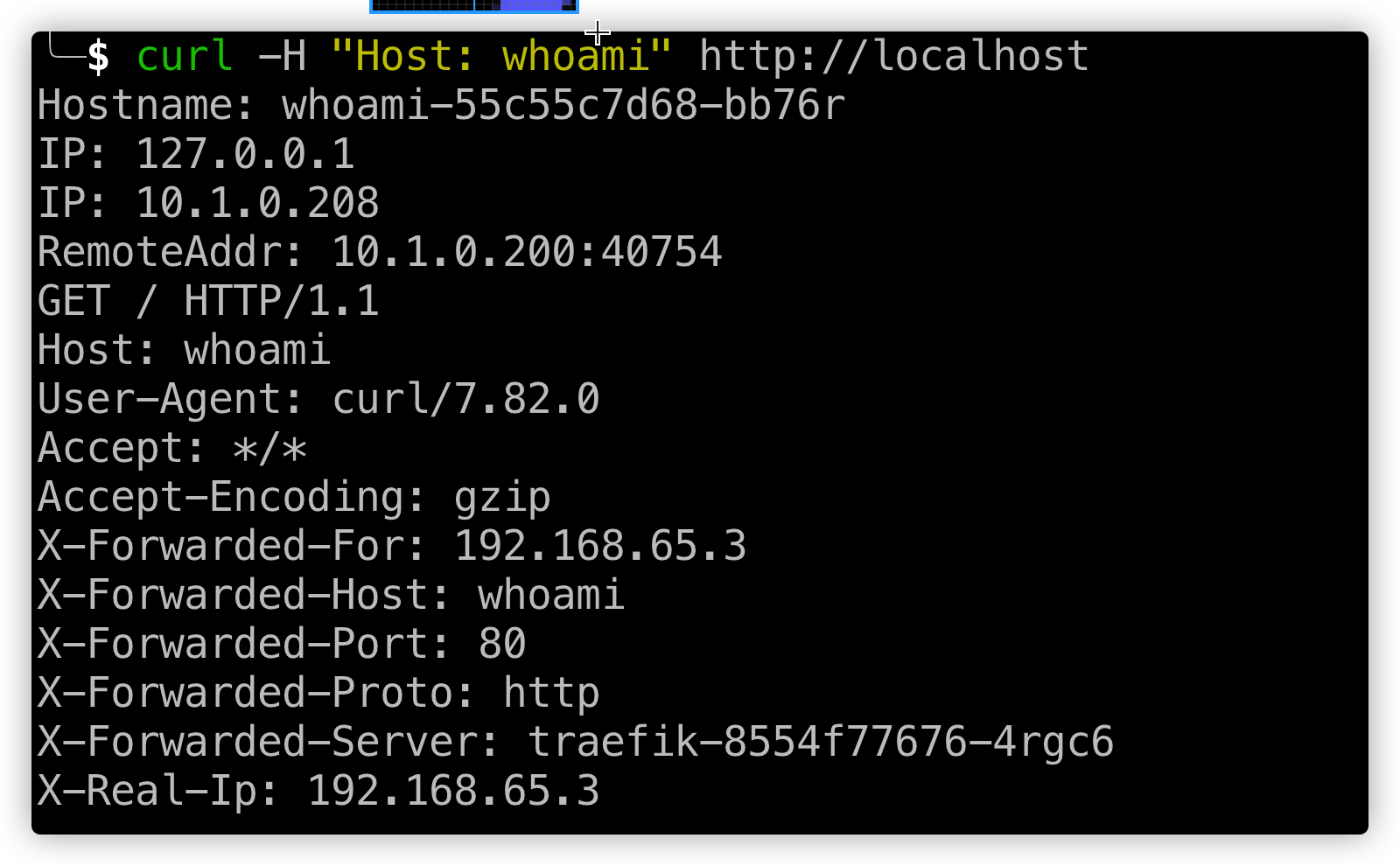
<p class="caption">curl访问后的结果</p>
注意`app: traefik`标签选择器,它目的是确保请求被路由到你的`Traefik`实例,这是上面通过`Helm Chart`包安装的默认标签,当然也可以做自定义。
- 带路径的简单主机
上面的例子很容易被加强到只对给出的`subpath`请求做响应:
# 03-whoami-httproute-paths.yaml
---
apiVersion: gateway.networking.k8s.io/v1alpha2
kind: HTTPRoute
metadata:
name: http-app-1
namespace: default
spec:
parentRefs:
\- name: traefik-gateway
hostnames:
\- whoami
rules:
\- matches:
\- path:
type: Exact
value: /foo
backendRefs:
\- name: whoami
port: 80
weight: 1
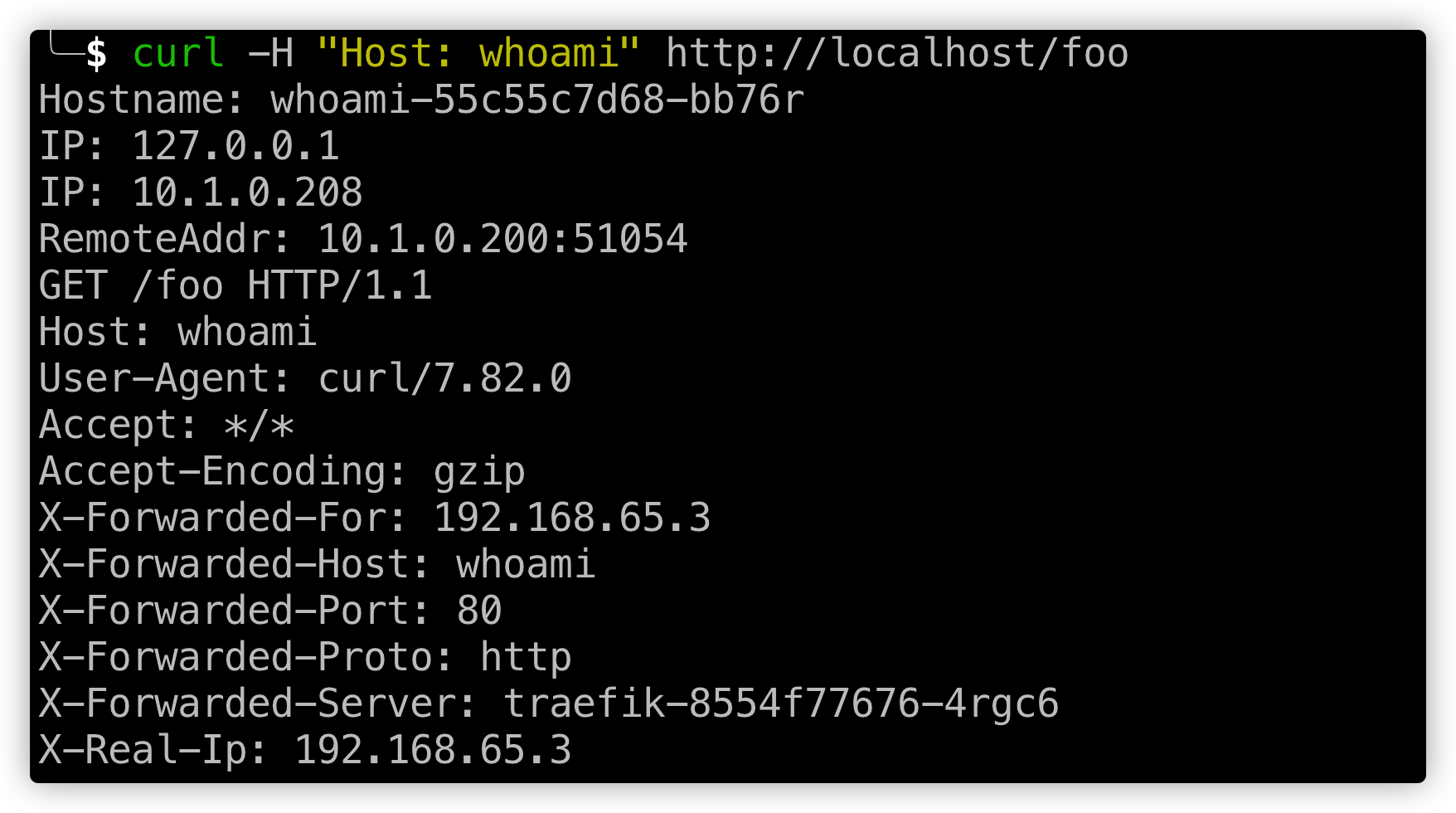
<p class="caption">curl请求http后反馈效果</p>
# 如何把静态证书的TLS应用在Gateway API中并与Traefik结合?
目前为止,你已经创建了一个简单的`HTTPRoute`。下一步,你将通过`TLS`保护请求路径。为了这,你需要创建一个带有虚拟证书的`Kubernetes Secret`。你将在配本篇日志的`Github`仓库的配置文件中找到一个导入:
# 04-tls-dummy-cert.yaml
---
apiVersion: v1
kind: Secret
metadata:
name: mysecret
namespace: default
type: kubernetes.io/tls
data:
tls.crt: LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSUVVVENDQXJtZ0F3SUJBZ0lRV2pNZ2Q4OUxOUXIwVC9WMDdGR1pEREFOQmdrcWhraUc5dzBCQVFzRkFEQ0IKaFRFZU1Cd0dBMVVFQ2hNVmJXdGpaWEowSUdSbGRtVnNiM0J0Wlc1MElFTkJNUzB3S3dZRFZRUUxEQ1JxWW1SQQpaSEpwZW5wMElDaEtaV0Z1TFVKaGNIUnBjM1JsSUVSdmRXMWxibXB2ZFNreE5EQXlCZ05WQkFNTUsyMXJZMlZ5CmRDQnFZbVJBWkhKcGVucDBJQ2hLWldGdUxVSmhjSFJwYzNSbElFUnZkVzFsYm1wdmRTa3dIaGNOTWpBeE1qQTAKTVRReE1qQXpXaGNOTWpNd016QTBNVFF4TWpBeldqQllNU2N3SlFZRFZRUUtFeDV0YTJObGNuUWdaR1YyWld4dgpjRzFsYm5RZ1kyVnlkR2xtYVdOaGRHVXhMVEFyQmdOVkJBc01KR3BpWkVCa2NtbDZlblFnS0VwbFlXNHRRbUZ3CmRHbHpkR1VnUkc5MWJXVnVhbTkxS1RDQ0FTSXdEUVlKS29aSWh2Y05BUUVCQlFBRGdnRVBBRENDQVFvQ2dnRUIKQU12bEc5d0ZKZklRSWRreDRXUy9sNGhQTVRQcmVUdmVQOS9MZlBYK2h2ekFtVC90V1BJbGxGY2JJNnZzemp0NQpEWlZUMFFuQzhHYzg0K1lPZXZHcFpNaTg0M20zdTdFSUlmY3dETUF4WWQ0ZjJJcENLVW9jSFNtVGpOaVhDSnhwCjVNd2tlVXdEc1dvVVZza1RxeVpOcWp0RWVIbGNuQTFHaGZSa3dEUkZxd1QxeVhaUTBoZHpkQzRCeFhhaVk0VEQKaFQ1dnFXQmlnUlh0M1VwSkhEL1NXUG4wTEVQOHM3ckhjUkZPY0RhV3ZWMW1jTkxNZUpveWNYUTJ0M2Z1Q0Fsegp3UWZOSjFQSk45QWlLalFJcXJ1MGFnMC9wU0kyQ3NkbEUzUTFpM29tZGpCQkZDcmxNMTZyY0wwNDdtWXZKOEVvCjFMdDVGQkxnVURBZktIOFRsaXU0ZG9jQ0F3RUFBYU5wTUdjd0RnWURWUjBQQVFIL0JBUURBZ1dnTUJNR0ExVWQKSlFRTU1Bb0dDQ3NHQVFVRkJ3TUJNQXdHQTFVZEV3RUIvd1FDTUFBd0h3WURWUjBqQkJnd0ZvQVV5cWNiZGhDego3Nm4xZjFtR3BaemtNb2JOYnJ3d0VRWURWUjBSQkFvd0NJSUdkMmh2WVcxcE1BMEdDU3FHU0liM0RRRUJDd1VBCkE0SUJnUUFzWlBndW1EdkRmNm13bXR1TExkWlZkZjdYWk13TjVNSkk5SlpUQ1NaRFRQRjRsdG91S2RCV0gxYm0Kd003VUE0OXVWSHplNVNDMDNlQ294Zk9Ddlczby94SFZjcDZGei9qSldlYlY4SWhJRi9JbGNRRyszTVRRMVJaVApwNkZOa3kvOEk3anF1R2V2b0xsbW9KamVRV2dxWGtFL0d1MFloVCtudVBJY1pGa0hsKzFWOThEUG5WaTJ3U0hHCkIwVU9RaFdxVkhRU0RzcjJLVzlPbmhTRzdKdERBcFcwVEltYmNCaWlXOTlWNG9Ga3VNYmZQOE9FTUY2ZXUzbW0KbUVuYk1pWFFaRHJUMWllMDhwWndHZVNhcTh1Rk82djRwOVVoWHVuc3Vpc01YTHJqQzFwNmlwaDdpMTYwZzRWawpmUXlYT09KY0o2WTl2a2drYzRLYUxBZVNzVUQvRDR1bmd6emVWQ3k0ZXhhMmlBakpzVHVRS3JkOFNUTGNNbUJkCnhtcXVKZXFWSEpoZEVMNDBMVGtEY1FPM1NzOUJpbjRaOEFXeTJkdkR1a1gwa084dm9IUnN4bWVKcnVyZ09MVmIKamVvbTVQMTVsMkkwY3FKd2lNNHZ3SlBsb25wMTdjamJUb0IzQTU5RjZqekdONWtCbjZTaWVmR3VLM21hVWdKegoxWndjamFjPQotLS0tLUVORCBDRVJUSUZJQ0FURS0tLS0t
tls.key: LS0tLS1CRUdJTiBQUklWQVRFIEtFWS0tLS0tCk1JSUV2Z0lCQURBTkJna3Foa2lHOXcwQkFRRUZBQVNDQktnd2dnU2tBZ0VBQW9JQkFRREw1UnZjQlNYeUVDSFoKTWVGa3Y1ZUlUekV6NjNrNzNqL2Z5M3oxL29iOHdKay83Vmp5SlpSWEd5T3I3TTQ3ZVEyVlU5RUp3dkJuUE9QbQpEbnJ4cVdUSXZPTjV0N3V4Q0NIM01BekFNV0hlSDlpS1FpbEtIQjBwazR6WWx3aWNhZVRNSkhsTUE3RnFGRmJKCkU2c21UYW83UkhoNVhKd05Sb1gwWk1BMFJhc0U5Y2wyVU5JWGMzUXVBY1Yyb21PRXc0VStiNmxnWW9FVjdkMUsKU1J3LzBsajU5Q3hEL0xPNngzRVJUbkEybHIxZFpuRFN6SGlhTW5GME5yZDM3Z2dKYzhFSHpTZFR5VGZRSWlvMApDS3E3dEdvTlA2VWlOZ3JIWlJOME5ZdDZKbll3UVJRcTVUTmVxM0M5T081bUx5ZkJLTlM3ZVJRUzRGQXdIeWgvCkU1WXJ1SGFIQWdNQkFBRUNnZ0VCQUl5SWpvbzQxaTJncHVQZitIMkxmTE5MK2hyU0cwNkRZajByTVNjUVZ4UVEKMzgvckZOcFp3b1BEUmZQekZUWnl1a1VKYjFRdUU2cmtraVA0S1E4MTlTeFMzT3NCRTVIeWpBNm5CTExYbHFBVwpEUmRHZ05UK3lhN2xiemU5NmdaOUNtRVdackJZLzBpaFdpdmZyYUNKK1dJK1VGYzkyS1ZoeldSa3FRR2VYMERiCnVSRXRpclJzUXVRb1hxNkhQS1FIeUVITHo2aWVVMHJsV3IyN0VyQkJ4RlRKTm51MnJ1MHV1Ly8wdG1SYjgzZWwKSUpXQnY1V1diSnl4dXNnMkhkc0tzTUh0eEVaYWh1UlpTNHU2TURQR3dSdjRaU0xpQm1FVVc3RUMwUEg3dCtGaAoxUDcrL0Yyd1pGSDAvSzl6eXUyc0lOMDJIbTBmSWtGejBxb09BSzQ5OXhrQ2dZRUE2SC9nVUJoOG9GUSt2cmZKCnQvbXdMeFBHZHhWb3FWR1hFVjhlQzNWbmxUSXJlREpNWm81b1hKZHNuQ0d2S1NaWUhXZ3o3SVpwLzRCL29vSWsKTDl4TEJSVTJwS0d1OGxBT1ZhYnpaVDk0TTZYSE1PTGQ0ZlUrS3ZqK1lLVm5laEM3TVNQL3RSOWhFMjN1MnRKZwp1eUdPRklFVlptNHZxS1hEelU3TTNnU0R5WXNDZ1lFQTRJRVFyZDl2MXp0T2k5REZ6WEdnY05LVmpuYmFTWnNXCm9JNm1WWFJZS1VNM1FyWUw4RjJTVmFFM0Y0QUZjOXRWQjhzV0cxdDk4T09Db0xrWTY2NjZqUFkwMXBWTDdXeTMKZXpwVEFaei9tRnc2czdic3N3VEtrTW5MejVaNW5nS3dhd3pRTXVoRGxLTmJiUi90enRZSEc0NDRrQ2tQS3JEbQphOG40bUt6ZlRuVUNnWUFTTWhmVERPZU1BS3ZjYnpQSlF6QkhydXVFWEZlUmtNSWE2Ty9JQThzMGdQV245WC9ICk12UDE4eC9iNUVMNkhIY2U3ZzNLUUFiQnFVUFQ2dzE3OVdpbG9EQmptQWZDRFFQaUxpdTBTOUJUY25EeFlYL3QKOUN5R1huQkNEZy9ZSE1FWnFuQ1RzejM4c0VqV05VcSt1blNOSkVFUmdDUVl0Y2hxSS9XaWxvWGQyd0tCZ1FEQworTlBYYlBqZ1h5MHoxN2d4VjhFU3VwQVFEY0E5dEdiT1FaVExHaU9Ha2sxbnJscG9BWnVZcWs0Q0pyaVZpYUlyCkJvREllWWpDcjVNK3FnR3VqU3lPUnpSVU40eWRRWkdIZjN1Zkp3NEM3L1k3SlY0amlzR3hSTSt3Rk9yQ0EydmIKVEdGMEZLcThaN0o2N3dQRVliUUNobDB4TmJkcVIvK1ZGTzdGQ1QxV0VRS0JnQThUaE9hZmNEUmdpd0IxRFdyRgozZ1lmT3I0dERENExrNjRYZlF6ajdtRXQyYlJzOFNEYXYwVGZPclVUUlpFTTkyTVFZMnlrbzhyMDJDbmpndmxCCm1aYnZCTEFYaVZLa0laai9TTkNYUnhzOFZkZ3psTkpzYVNZTUtsNloxK1Z3MnZUdDNQSnI0TXlhRWpHYUxlSmMKRGRTQjdYOU9ESk5acW10bGpoRzc5eXpQCi0tLS0tRU5EIFBSSVZBVEUgS0VZLS0tLS0=
有了这个资源之后,就可以开始进行安全配置了。首先必须重新配置`Gateway`,以创建一个带有`mysecret`证书的`TLS`监听器,可以通过使用`Helm Chart`的升级选项进行更新,以使在`Traefik`配置中添加证书部分。
`helm upgrade traefik -f 05-values.yaml traefik/traefik`
其中`05-values.yaml`的内容如下所示:
# 05-values.yaml
---
experimental:
kubernetesGateway:
appLabelSelector: traefik
certificates:
-
group: "core"
kind: "Secret"
name: "mysecret"
enabled: true
当重启了`Traefik Proxy`之后,你可以验证一下结果。相同`HTTPRoute`依然有效,有个区别是现在你可以通过`HTTPS`访问。
`curl --insecure -H "Host: whoami" https://localhost/foo`
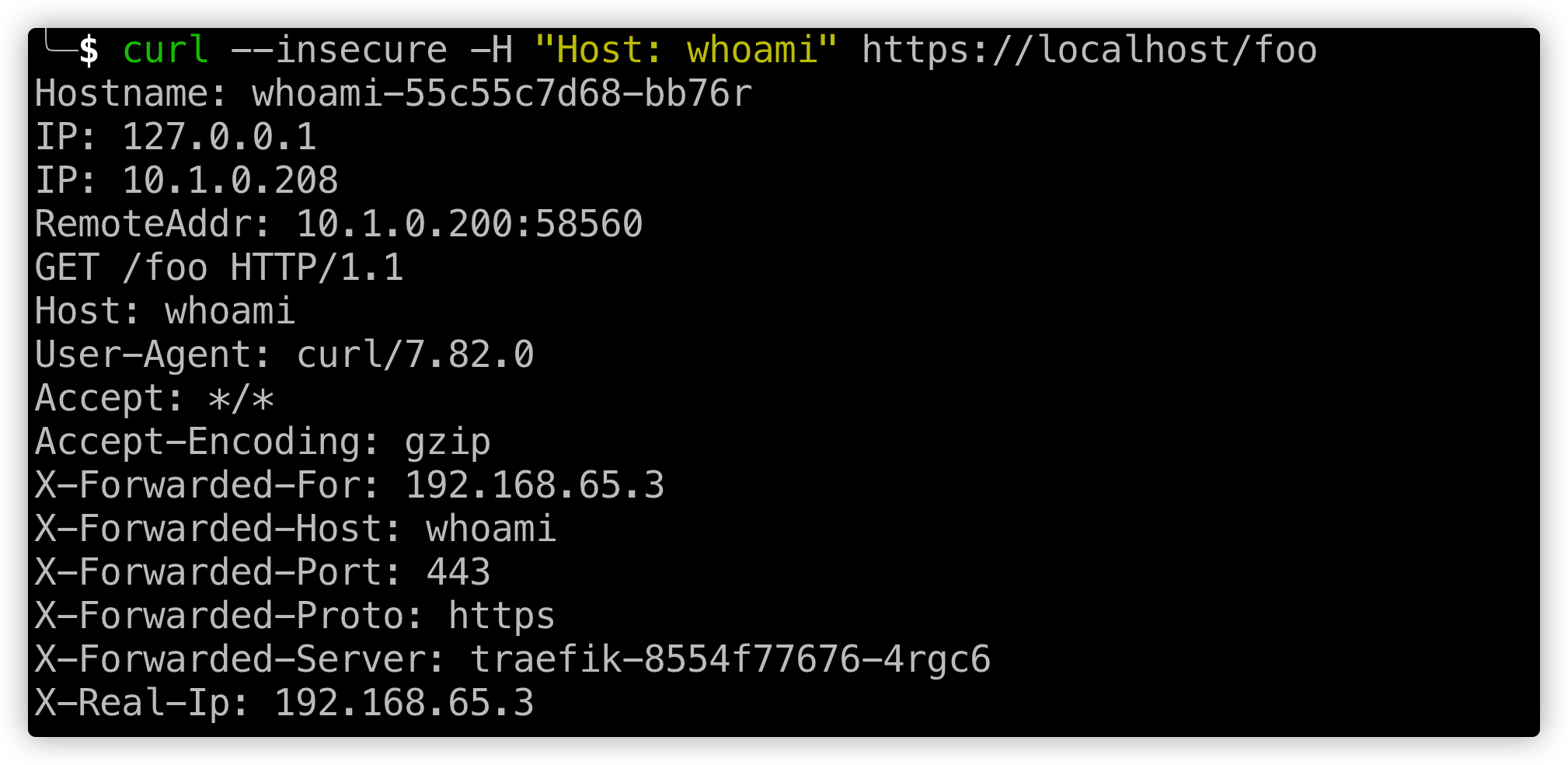
<p class="caption">curl请求https后反馈效果</p>
注意你必须给curl请求传`--insecure`参数,这样才能够保证使用未签名的虚拟证书。
# 金丝雀发布
`Traefik Proxy`的另一个特色是它能够通过指定的`Service API`进行支持,它就是金丝雀发布。设想你想在一个`endpoint`运行两个不同的服务(或者同一个服务的两个不同版本),同时将请求路由到每一个节点。你可以通过修改`HTTPRoute`来实现这样的目的。
首先,你需要运行第二个服务,针对这个例子,你可以迅速生成一个`Nginx`实例。
# 06-nginx.yaml
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
name: http
---
apiVersion: v1
kind: Service
metadata:
name: nginx
spec:
selector:
app: nginx
ports:
- port: 80
targetPort: http
`HTTPRoute`资源有一个`weight`选项,你可以针对两个服务中的每一个分配不同的值。
# 07-whoami-nginx-canary.yaml
---
apiVersion: gateway.networking.k8s.io/v1alpha2
kind: HTTPRoute
metadata:
name: http-app-1
namespace: default
spec:
parentRefs:
- name: traefik-gateway
## hostnames是指定关联的服务吗?上面定义的deployment和service,这里用gateway api的HTTPRoute组件把服务和路由关联起来
hostnames:
- whoami
rules:
- backendRefs:
- name: whoami
port: 80
weight: 3
- name: nginx
port: 80
weight: 1
现在,你可以通过http://localhost(没有foo/路径后缀)再次访问你的whoami服务。记住,然而这样配置25%机会将看到Nginx的响应,其它都是来自于whoami。
如何查看pod的运行状态?
答:可以用命令kubectl get pods --show-labels,后面的参数--show-labels加不加都可以,可以查看有哪些pods。之后用命令kubectl describe pods POD_NAME,就可以查看pod的详细信息。
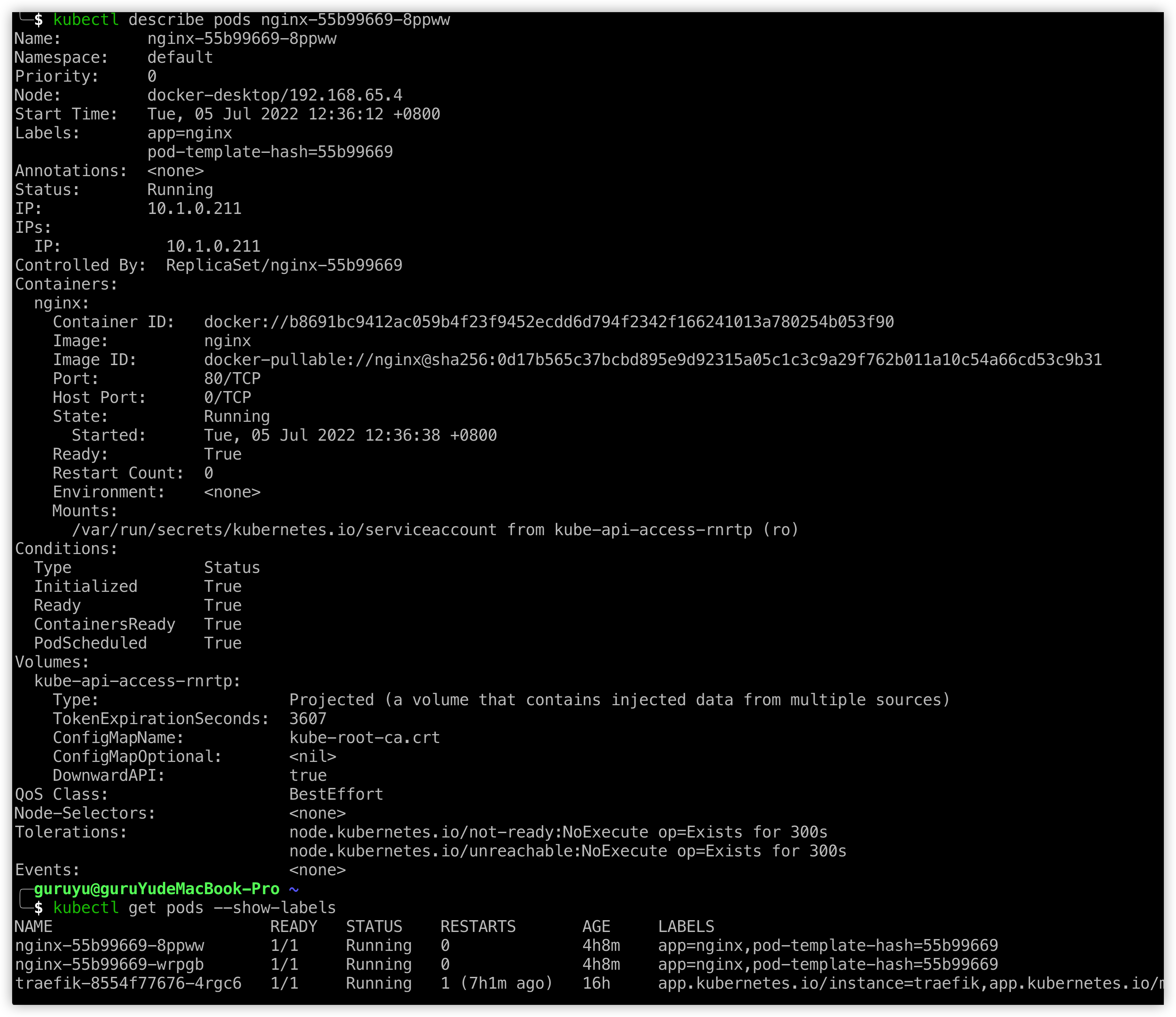
kubectl describe的显示
docker中有啥常用的命令">docker中有啥常用的命令
docker images | grep 'vue' 按名称去匹配
k8s相关常用的命令有哪些">跟k8s相关常用的命令有哪些?
`echo "$DOCKER_PWD_VAR" | docker login $REGISTRY -u "$DOCKER_USER_VAR" --password-stdin` 登录阿里云仓库
`docker tag isee-gateway:latest $REGISTRY/$DOCKERHUB_NAMESPACE/isee-gateway:SNAPSHOT-$BUILD_NUMBER` 打包
`docker push $REGISTRY/$DOCKERHUB_NAMESPACE/isee-gateway:SNAPSHOT-$BUILD_NUMBER` 推送镜像
`kubectl get limitrange -o=yaml -n project1` 查看资源使用情况
`kubectl get pvc -A(--all-namespace)` 查看所有命名空间下的所有persist volume cluster
`kubectl logs minio-845b7bd867-5kj89 -n kubesphere-system --tail=100` 查看kubesphere-system命名空间下名为xx的pod的日志
`kubectl -n kube-system edit cm coredns` 编辑dns
`kubectl -n kube-system scale deployment coredns --replicas=0 && kubectl -n kube-system scale deployment coredns --replicas=1` 分片扩容
`kubectl edit cm -n kubesphere-system ks-installer` kubesphere以All-in-one方式安装,也即最小化安装之后,想做一些配置的调整,就用这个命令
`helm repo list | grep minio` 用helm方式安装minio之后,查看一下安装情况
`kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath={.items[0].metadata.name}) -f`
`kubectl get deployments` 查看有哪些部署
`kubectl get services` 查看有哪些服务
`kubectl describe deployments DEPLOYMENT_NAME` 查看某个部署的详情
`kubectl describe services SERVICE_NAME` 查看某个服务的详情
`kubectl get namespace` 列出所有可用的命名空间及它们的部署
`kubectl get deployments --all-namespaces` 从所有命名空间中列出所有的部署
`kubectl delete deployments --namespace=webapps webapps-dep` 已知命名空间及部署名称,可以通过指定的方式删除该部署
`kubectl delete deployment my-dep my-dep2 --namespace=default` 通过提供命名空间下的部署名称,一次删除多个该命名空间下的部署
`kubectl delete -f deployment-definition.yml` 通过部署文件删除关联于该部署文件的所有资源
`kubectl apply -f deployment-definition.yml` 通过`yml`文件创建部署
`kubectl delete deployments my-dep` 删除名称为my-dep的部署
`kubectl delete pods -all` 删除所有pod
`kubectl delete pod POD_NAME -n NAMESPACE_NAME` 删除指定命名空间的指定名称pod
`kubectl delete svc SERVICE_NAME -n NAMESPACE_NAME` 删除指定命名空间指定名称的服务
`kubectl get services --all-namespaces` 获取所有命名空间的全部服务
`kubectl delete svc whoami traefik --namespace=default` 删除指定命名空间的多个服务,本例中是`whoami`、`traefik`
`kubectl delete pods, services -l name=myLabel` 删除标签为`name=myLabel`的`pods`和`services`
`kubectl get apiservice` 查看apiservice的状态
`kubectl api-resources -o name --verbs=list --namespaced | xargs -n 1 kubectl get --show-kind --ignore-not-found -n zuisishu-com` 查看命名空间是否有占用着的资源
`kubectl get ns zuisishu-com -o yaml` 以`yaml`格式查看对应命名空间的配置
`kubectl delete ns NAMESPACE_NAME` 删除指定名称的命名空间
`kubectl delete "$(kubectl api-resources --namespaced=true --verbs=delete -o name | tr "\n" "," | sed -e 's/,$//')" --all` 删除全部
`kubectl get Issuers,ClusterIssuers,Certificates,CertificateRequests,Orders,Challenges --all-namespaces` 查看所有命名空间下的所有相关
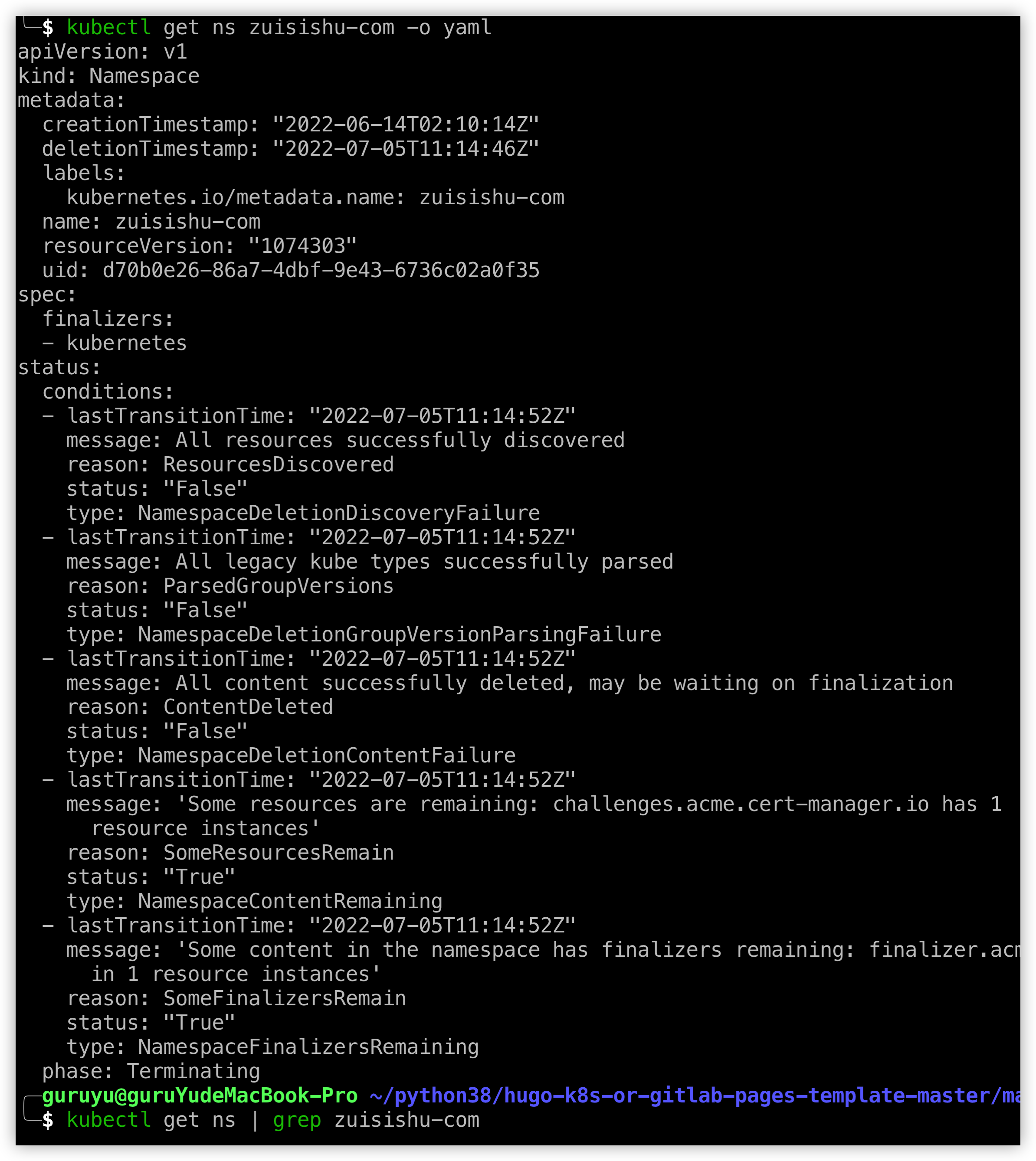
kubectl get ns zuisishu-com -o yaml
`kubectl get ns | grep zuisishu-com` 查看命名空间详情
`kubectl -n zuisishu-com get challenge.acme.cert-manager.io/zuisishu-com-letsencrypt-prod-zv9gk-2899240583-109476044 -o yaml` 查看命名空间下处于`pending`状态的资源详细情况
`kubectl delete challenge zuisishu-com-letsencrypt-prod-zv9gk-2899240583-109476044 -n zuisishu-com` 删除占用着资源的`challenge`,注意不用把前缀接口加上

这部分不用写上去
`kubectl get challenge -A` 获取所有的`challenge`
`kubectl patch challenge/zuisishu-com-letsencrypt-prod-zv9gk-2899240583-109476044 -n zuisish-com -p '{"metadata":{"finalizers":[]}}' --type=merge` `merge patch`必须包含一个对象资源的部分描述,`json`对象。该`json`对象被提交到服务端,并和服务端的当前对象进行合并,从而创建新的对象。完整的远的列表,也就是说,新的列表定义会替换原有的定义。注意`--type=merge`参数的指定,可用于新增容器或者修改已有容器的对象
`kubectl patch deployment/foo --type='json' -p \
'[{"op":"add","path":"/spec/template/spec/containers/1","value":{"name":"nginx","image":"nginx:alpine"}}]'
` 新增容器
`kubectl patch deployment/foo --type='json' -p \
'[{"op":"replace","path":"/spec/template/spec/containers/0/image","value":"app-image:v2"}]'
` 修改已有容器镜像
`kubectl describe challenge zuisishu-com --namespace=zuisishu-com` 查看challenge的详情
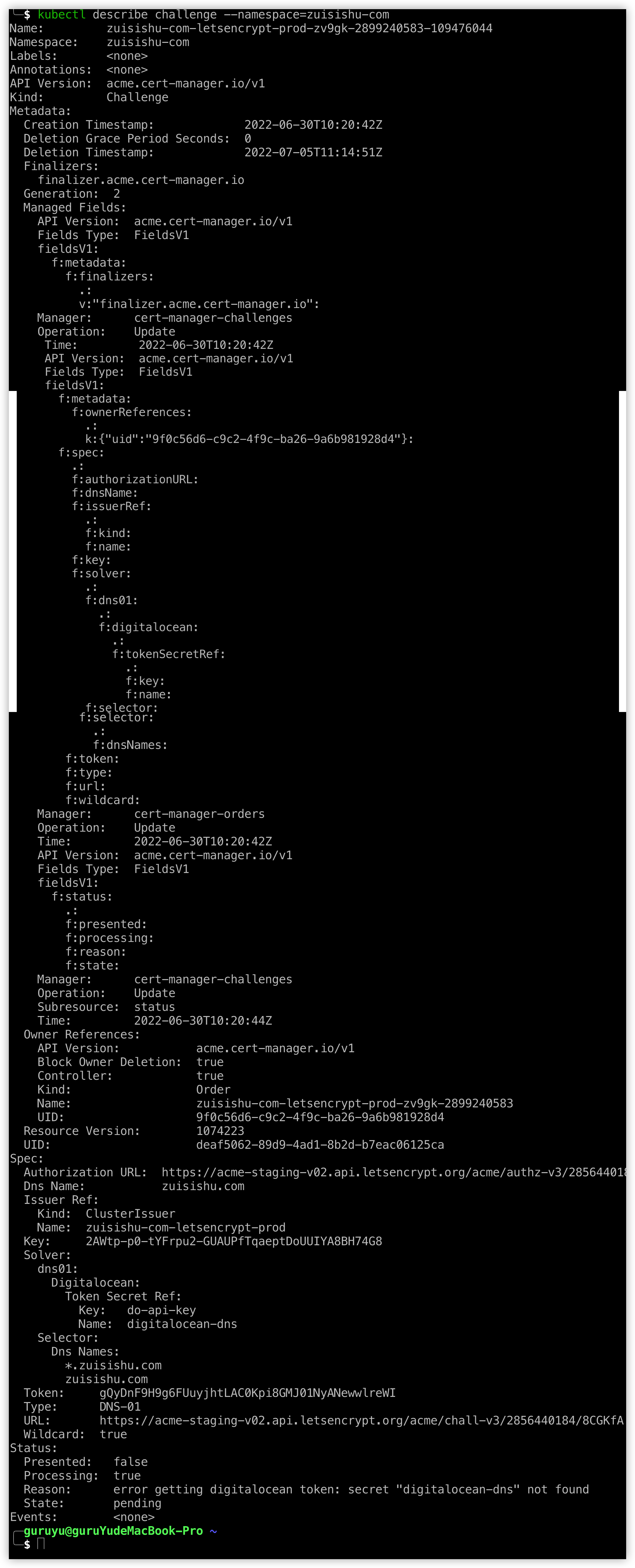
kubectl describe challenge查看challenge详细信息
`kubectl get pods -A -owide` 可以查看`pods`的详细信息
`kubectl describe secrets/aliyun-harbor-secret -n project1` 查看指定项目名称下有哪些secrets
`kubectl get secrets -o yaml -n project1` 以yaml文件的形式查看相应project1命名空间下的secrets文件
kubectl get secret aliyun-harbor-secret -o jsonpath='{.data}' -n project1 查看指定名称的secret的打印信息
`kubectl get secret aliyun-harbor-secret -o jsonpath='{.data.password}' -n project1 | base64 --decode` 以decode之后的字串格式显示命名空间为project1下的secret的值
`kubectl delete secret db-user-pass` 删除密钥
`kubectl create secret docker-registry regcred --docker-server=registry.cn-hangzhou.aliyuncs.com --docker-username=jqadmin --docker-password=wudimanong` 以命令行的形式创建密钥
`kubectl get pods -n project1 | grep -v Running` 获取异常容器
`kubectl describe pod vue-test-1-8596d896ff-5nj2t -n project1` 查找问题
`kubectl edit cm ks-installer -n kubesphere-system` kubesphere安装完成之后,编辑安装指定文件可以开启或者关闭相关的服务
`kubectl logs vue-test-1-8596d896ff-5nj2t -n project1` 查看指定命名空间下pod的相关日志
`kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l 'app in (ks-install, ks-installer)' -o jsonpath='{.items[0].metadata.name}') -f`
` 查看All-in-one模式安装的kubesphere的详情,包括运行ip地址,端口之类的
`kubectl get apiservice | grep metrics` 查看kube-system下是否metrict-server
怎么做端口转发?
答:
- 端口转发是基于
NAT建立的,如果你是用腾讯云服务器的话,入口就在NAT 网关控制台 - 在列表中单击需要修改的 NAT 网关 ID 进入详情页,单击选项卡中的端口转发。

- 单击新建,选择协议、外部端口 IP 及内部端口 IP 后,单击确定即可。
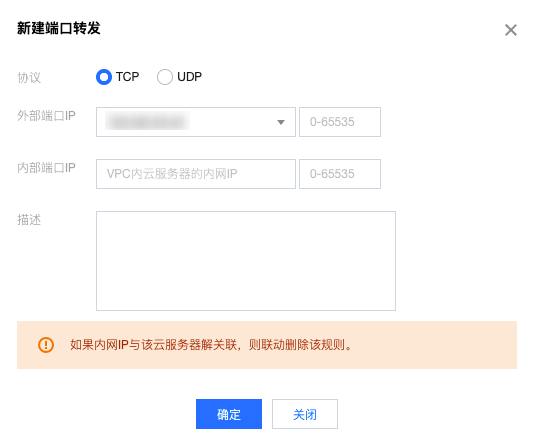
如何以密码控制台输入的方式完成密码输入的配置?
答:可以用echo "password" | passwd --stdin
一些问题的汇总
## 导出k8s密钥
echo $(kubectl config view --raw -oyaml | grep client-cert |cut -d ' ' -f 6) |base64 -d ? /tmp/client.pem
echo $(kubectl config view --raw -oyaml | grep client-key-data |cut -d ' ' -f 6 ) |base64 -d > /tmp/client-key.pem
echo $(kubectl config view --raw -oyaml | grep certificate-authority-data |cut -d ' ' -f 6 ) |base64 -d > /tmp/ca.pem
`curl --cert /tmp/client.pem --key /tmp/client-key.pem --cacert /tmp/ca.pem -H "Content-Type: application/json" -X PUT --data-binary @/root/monitoring.json https://172.16.8.43:6443/api/v1/namespaces/monitoring/finalize
` 使用http接口进行删除
`kubectl get ns` 获取所有命名空间
`kubectl delete all --all --all-namespaces` 删除所有命名空间的所有相关
`kubectl get daemonset` 获取所有的进程集合,`DaemonSet`类似于`Deployment`的含义
`kubectl api-version` 查看可用的apiVersion版本
`kubectl get issuer` 检查你使用的`Issuer`是否处在准备好的状态
`kubectl get clusterissuer` 检查你使用的`ClusterIssuer`是否处在准备好的状态
`kubectl get configmaps` 获取所有的`ConfigMap`
`kubectl get crds` 获取所有的`CustomResourceDefinition`,也就是对部署做哪些自定义
`kubectl get serviceaccounts` 获取所有rbac的账号信息
`kubectl get clusterroles` 获取所有集群用户角色
`kubectl get clusterrolebindings` 获取所有角色与用户绑定关系
`kubectl get pods -A` 获取所有的`pod`
`kubectl taint` 该命令可以给某个Node节点设置污点,Node被设置污点之后就和Pod之间存在一种互斥的关系,可以让Node拒绝Pod的调度执行,甚至将Node已存在的Pod驱逐出去。
污点的组成如下:
`key=value:effect`
每个污点有一个key和value作为污点的标签,其中value可以为空,effect描述污点的作用。当前`trait effect`支持如下三个选项:
- `NoSchedule`:表示k8s将不会将`Pod`调度到具有该污点的`Node`上
- `PreferNoSchedule`:表示k8s将尽量避免将`Pod`调度到具有该污点的`Node`上
- `NoExecute`:表示k8s将不会将`Pod`调度到具有该污点的`Node`上,同时会将`Node`上已存在的`Pod`驱逐出去
`kubectl label node node1 node-role.kubernetes.io/master=` 设置Label
`kubectl label node node1 node-role.kubernetes.io/master-` 移除Label
`kubectl get node` 获取所有节点
`kubectl describe daemonset DEPLOYMENT/DAEMONSET_NAME` DaemonSet/Deployment下部署的详情,就是`labels.app.APP_NAME`中`NAME`的详情
`kubectl get po -A -owide` 查看所有pods
`kubectl get IngressRoute` 查看有哪些路由
`kubectl explain IngressRoute.spec` 查看Ingress的运行配置
`kubectl taint nodes --all node-role.kubernetes.io/master-` 让可以在master pod上运行
`kubectl get pods -o wide --show-labels --namespace=kube-system` 查看指定命令空间的所有节点
`kubectl get ds -o wide` 查看DaemonSet的list
`kubectl describe ds traefik-ingress-controller` 查看指定名称的DaemonSet的详细信息
`kubectl get ds/<daemonset-name> -o go-template='{{.spec.updateStrategy.type}}{{"\n"}}'` 检查当前的DaemonSet的更新策略
`kubectl rollout status ds/traefik-ingress-controller` 查看DaemonSet的更新状态
`kubectl delete ds fluentd-elasticsearch -n kube-system` 删除命名空间下的DaemonSet
`kubectl get pods --all-namespaces` 获取所有命名空间下的pods
`kubectl get cs` 获取所有的`scheduler`和`controller-manager`的运行状态
`kubectl get cs scheduler` 查看scheduler的运行状态
`kubectl -n kube-system get cm kubeadm-config -oyaml` 以`yaml`格式查看kubeadm-config的格式
`kubectl edit cm cluster-info -oyaml -n kube-public` 编辑yaml格式配置ConfigMap,要关注编辑的部分就是其中的`server`地址
`kubectl cluster-info dump` 打印集群信息
`kubectl get pods -o wide --all-namespaces` 获取所有命名空间的`pods`
`kubectl proxy` 运行`Kubernetes Proxy`
`kubectl cluster-info dump > kubernetes-dump.log` 把集群信息打印到日志文件中
`brew install etcd` `MacOS`系统安装`etcd`
`kubectl get node -o yaml` 以yaml格式查看node信息
`kubectl describe pods traefik-n4w68 --namespace=kube-system` 查看指定命名空间下的对应pod的详细信息
`kubectl describe pods traefik-5bb4c --namespace=kube-system` 查看指定命名空间内pod的详细信息
`kubectl describe gateway https-gateway --namespace=default` 查看指定命名空间的`gateway`的详情
`kubectl describe po --all-namespaces` 所有命名空间的所有pods的详情
`kubectl get pods --field-selector=status.phase=Pending --namespace=kube-system` 查看命名空间下哪些pods的状态是`Pending`
`kubectl get gateway -n kube-system http-gateway -o yaml` 以yaml格式获取命名空间为`kube-system`下名称为`http-gateway`这个`Gateway`的详情
`kubectl config current-context` 查看kubectl程序实现的上下文
`kubectl get pods -n ingress-nginx \
-l app.kubernetes.io/name=ingress-nginx --watch`
监控命名空间下,ingress维护的`ingress-controller`端口在命名空间`ingress-nginx`下是否有效运行

带ingress-nginx-controller字样的显示为running就说明它在运行
`kubectl get replicasets` 查看有哪些集群
`kubectl describe replicasets` 查看所有集群的详细信息
`kubectl expose deployment hello-world --type=LoadBalancer --name=my-service` 创建可供外部访问的名为`hello-world`的`Deployment`,名为`my-service`的`Service`
# 说说你所知道的`kubectl`命令?
kubectl controls the Kubernetes cluster manager.
Find more information at: <https://kubernetes.io/docs/reference/kubectl/overview/>
Basic Commands (Beginner):
create Create a resource from a file or from stdin
expose Take a replication controller, service, deployment or pod and expose it as a new Kubernetes service
run Run a particular image on the cluster
set Set specific features on objects
Basic Commands (Intermediate):
explain Get documentation for a resource
get Display one or many resources
edit Edit a resource on the server
delete Delete resources by file names, stdin, resources and names, or by resources and label selector
Deploy Commands:
rollout Manage the rollout of a resource
scale Set a new size for a deployment, replica set, or replication controller
autoscale Auto-scale a deployment, replica set, stateful set, or replication controller
Cluster Management Commands:
certificate Modify certificate resources.
cluster-info Display cluster information
top Display resource (CPU/memory) usage
cordon Mark node as unschedulable
uncordon Mark node as schedulable
drain Drain node in preparation for maintenance
taint Update the taints on one or more nodes
Troubleshooting and Debugging Commands:
describe Show details of a specific resource or group of resources
logs Print the logs for a container in a pod
attach Attach to a running container
exec Execute a command in a container
port-forward Forward one or more local ports to a pod
proxy Run a proxy to the Kubernetes API server
cp Copy files and directories to and from containers
auth Inspect authorization
debug Create debugging sessions for troubleshooting workloads and nodes
Advanced Commands:
diff Diff the live version against a would-be applied version
apply Apply a configuration to a resource by file name or stdin
patch Update fields of a resource
replace Replace a resource by file name or stdin
wait Experimental: Wait for a specific condition on one or many resources
kustomize Build a kustomization target from a directory or URL.
Settings Commands:
label Update the labels on a resource
annotate Update the annotations on a resource
completion Output shell completion code for the specified shell (bash, zsh or fish)
Other Commands:
alpha Commands for features in alpha
api-resources Print the supported API resources on the server
api-versions Print the supported API versions on the server, in the form of "group/version"
config Modify kubeconfig files
plugin Provides utilities for interacting with plugins
version Print the client and server version information
Usage:
kubectl [flags] [options]
Use "kubectl <command> --help" for more information about a given command.
Use "kubectl options" for a list of global command-line options (applies to all commands).
# 如下的报错说明啥?
W0216 00:31:03.018576 1 watcher.go:229] watch chan error: etcdserver: mvcc: required revision has been compacted
W0216 00:38:53.578318 1 watcher.go:229] watch chan error: etcdserver: mvcc: required revision has been compacted
W0216 00:52:52.543409 1 watcher.go:229] watch chan error: etcdserver: mvcc: required revision has been compacted
W0216 01:07:56.966062 1 watcher.go:229] watch chan error: etcdserver: mvcc: required revision has been compacted
W0216 01:22:36.172204 1 watcher.go:229] watch chan error: etcdserver: mvcc: required revision has been compacted
答:这个报错是`etcd`版本导致的,不影响功能的使用。
k8s早期版本的迁徙v1alpha1-to-v1alpha2">简述一下k8s早期版本的迁徙:v1alpha1 to v1alpha2
如果你已经有了用先前版本运行的Gateway API设置,如果你要实施自己应用的迁徙,这有一些步骤需要被实施。之前版本的Gateway API应用了之前networking.x-k8s.io/v1alpha1的APIGroup。伴随着0.4版本的发行就使用gateway.networking.k8s.io/v1alpha2的APIGroup,而使用之前版本创建的对象就不再兼容了。甚至内建的Kubernetes API Server也无法为你处理这种问题。这导致迁徙过程变得有些繁琐。
我建议按照下面三步来执行:
- 首先安装最新的
CRDS - 复制之前的
HTTPRoutes,同时用新版本的API重建它们 - 执行
Helm upgrade命令来安装Traefik 2.6版本,同时使用新版本的Gateway API:helm upgrade traefik traefik/traefik --set experimental.kubernetesGateway.enable=true
通过以上步骤可以确保再升级之后,你的服务仍然可以被正常访问。
k8s的gateway-api的未来你怎么看">对于k8s的Gateway API的未来你怎么看?
答:目前,Traefik对于Gateway API的继承着力在HTTP和HTTPS上,这些都属于TCP路由的范畴,以及有关TLS的处理。更多高级能力的拓展,比如说filters中加入requestHeaderModifier或者requestRedirct等,有望未来会被支持。
k8s如果部署一个wordpress应用该如何操作说说你的理解">谈谈你对k8s如果部署一个wordpress应用,该如何操作?说说你的理解
答:我觉得与用docker swarm模式,使用Traefik做边缘路由,再以它为流量入口做流量分发类似,endpoints流量最终要交到具体应用上来处理。在docker swarm模式下通过在docker-compose.yml文件的各container的lables声明处,指定traefik.enable=true来将应用的流量处理交由Traefik,这样就把边缘路由和具体处理请求的应用间建立了连接。而在k8s中,你建立好边缘路由之后,流量最终处理还是得交由具体的应用来处理,在k8s中具体的应用是什么?如果有相关k8s的基础知识,不难回答这个问题,就是pod。pod在k8s集群部署中就相当于docker部署方式中的container,所以问题就回到了如何来设置这个pod。而k8s的集群管理,并不像docker-compose.yml中声明的一样,只有单一节点,也就是只起一个进程做处理就完了,它要调度起很多的pods来做请求的响应。k8s中的组织方式是什么呢?它是在type声明成Deployment的文件中对于集群运行的理想状态进行声明。而具体起这些声明出的,要以理想状态运行的pod如何对外部提供服务,开放哪些端口,需要type类型为Service的组成部分来最终完成。所以,如果我来部署一个wordpress的应用的话,假如我只在一个节点对外提供服务,k8s概念范畴内的master线程和worker线程可能就要“合二为一”,我可以把type类型为Deployment和Service的声明集成在一个文件中,这个过程需要有wordpress的镜像,由于我在之前docker swarm模式部署该应用的实践中已经生成了该镜像并且提交到了hub.docker.com上,所以,我直接可以在Doployment类型中把我的image指定成我该镜像仓库中的镜像包。同时,之前部署过程中的问题依然存在,我不能直接像部署ghost项目一样,Traefik边缘路由直接转发请求到ghost应用,然后ghost应用就可以直接处理了。由于php-fpm通过fastcgi来处理请求,边缘路由直接把请求打到fastcgi上,fastcgi并不能直接处理。所以,我依然需要引入nginx服务,由nginx最终把边缘路由Traefik接收到的请求转发给fastcgi来完成请求的处理,并最终返回结果。引入nginx的另一个目的也在于,基于长远CI/CD的考虑,由于我目前只在单独一台服务器上部署所有应用,这其中包括有gitlab,harbor,基于go语言的博客系统,基于python的在线教育后端API,以及基于node的vue后台展示管理界面及前端展示界面,这些如果想都通过根或子域名可以被访问到,那么,80端口需要在多个应用中被复用的情况需要被支持,这种情形下,也只有引入nginx才能达到这样的目的。同时,由于边缘路由引入的最大好处就是可以让多域名的TLS不必像常规配置nginx一样,为每个域名单独生成tls.key,tls.csr这种复杂繁琐的操作,所以Traefik能够统筹全局的certificates,使全局的tls在访问任何域名时都自动加成能够被支持,traefik作为流量入口网关,nginx作为流量分发网关的技术结合选型,也是目前可以选择的唯一高效且可行的技术方案了。
k8s删除namespace失败状态terminating如何解决">k8s删除namespace失败,状态Terminating如何解决?
答:因为k8s是携带认证的,所以删除其中的spec字段。先查看下命名空间下是否还有引用的pod还在运行,用下面的命令:
kubectl api-resources -o name --verbs=list --namespaced | xargs -n 1 kubectl get --show-kind --ignore-not-found -n longhorn-system
kubernetes-v122的api移除有哪些">Kubernetes v1.22的API移除有哪些?
- ValidatingWebhookConfiguration 和 MutatingWebhookConfigurationAPI 的 Beta 版本(admissionregistration.k8s.io/v1beta1 API 版本)
- 测试版 CustomResourceDefinitionAPI(apiextensions.k8s.io/v1beta1)
- 测试版APIServiceAPI(apiregistration.k8s.io/v1beta1)
- 测试版TokenReviewAPI(authentication.k8s.io/v1beta1)
- SubjectAccessReview,LocalSubjectAccessReview 的 Beta API 版本 SelfSubjectAccessReview(来自 authorization.k8s.io/v1beta1 的 API 版本)
- 测试版 CertificateSigningRequestAPI(certificates.k8s.io/v1beta1)
- 测试版 LeaseAPI(协调 .k8s.io/ v1beta1)
- 所有 beta IngressAPI(extensions/v1beta1 和 networking.k8s.io/v1beta1 API 版本)
kubectl-create与kubectl-apply之间的区别">简述kubectl create与kubectl apply之间的区别?
答:kubectl create,我们指定一个特定的动作,在这种情况下create,因为它是必要的。在kubectl apply中,我们指定系统的目标状态,并且不指定特定操作,因此声明,系统来决定采取什么行动。如果资源存就将应用于现有资源,如果资源不存在,则创建它。
简述一个DaemonSet与Deployment之间的区别?
答:Deployment会在多个node上运行多个pod副本资源,每个node上都会有好多个副本。而DaemonSet只会在一个node上运行一个pod副本资源,每个node上最多运行一个副本。
说说你对Labels和Annotation的理解?
答:Annotation是将任意非标识元数据附加到对象上。比如工具和库之类的客户端可以检索此元数据。而Labels是附加到对象的键/值对,标签旨在用于指定对用户有意义和相关的对象的标识属性,但不直接暗示核心系统的语义,标签允许高效的查询和观察,非常适合在UI和CLI中使用。
kubernetes部署的过程中出现问题可以通过什么样的命令获得实时日志信息">在macos上,如果Kubernetes部署的过程中出现问题,可以通过什么样的命令获得实时日志信息?
pred='process matches ".*(ocker|vpnkit).*" || (process in {"taskgated-helper", "launchservicesd", "kernel"} && eventMessage contains[c] "docker")' /usr/bin/log stream --style syslog --level=debug --color=always --predicate "$pred"
kubernetes一直处于starting状态如何解决">为什么MacOS系统安装了Desktop for Mac之后启用Kubernetes一直处于starting状态,如何解决?
答:先选择Reset to factory defaults,之后退出Desttop for Mac。之后删除以下两个位置的资源:
rm -rf ~/Library/Group\ Containers/group.com.docker/pkirm -rf ~/.kube之后,再重新启动Desktop for Mac,再次选择安装Kubernetes,这样就可以了。
k8s中tolerations的理解">简述一下你对k8s中tolerations的理解?
答:tolerations声明的作用是用来调剂DaemonSet部署模式中是否master节点也参与pod的运行。在kubernetes1.6版本之后,默认DaemonSet部署模式,master节点不运行pod,但是你如果想让master节点也运行pod,可以用如下的模式:
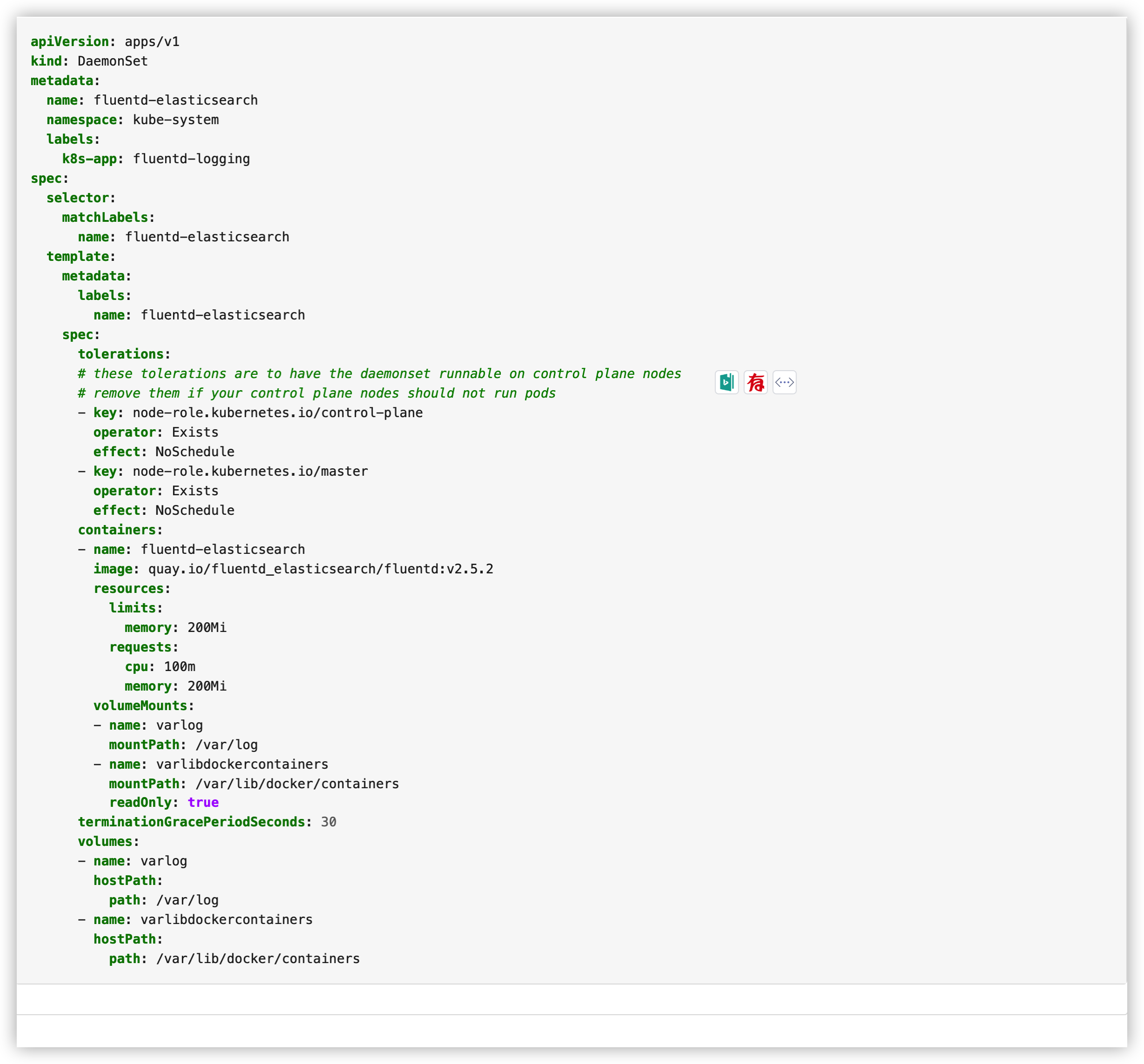
有关tolerations设置来指定master节点是否允许运行pods
k8s中的label如k8s-app或者app">怎么理解k8s中的label如k8s-app或者app?
答:在yaml文件中labels声明key值为k8s-app是旧版本支持的标签,在新版本中已经用name来代替。
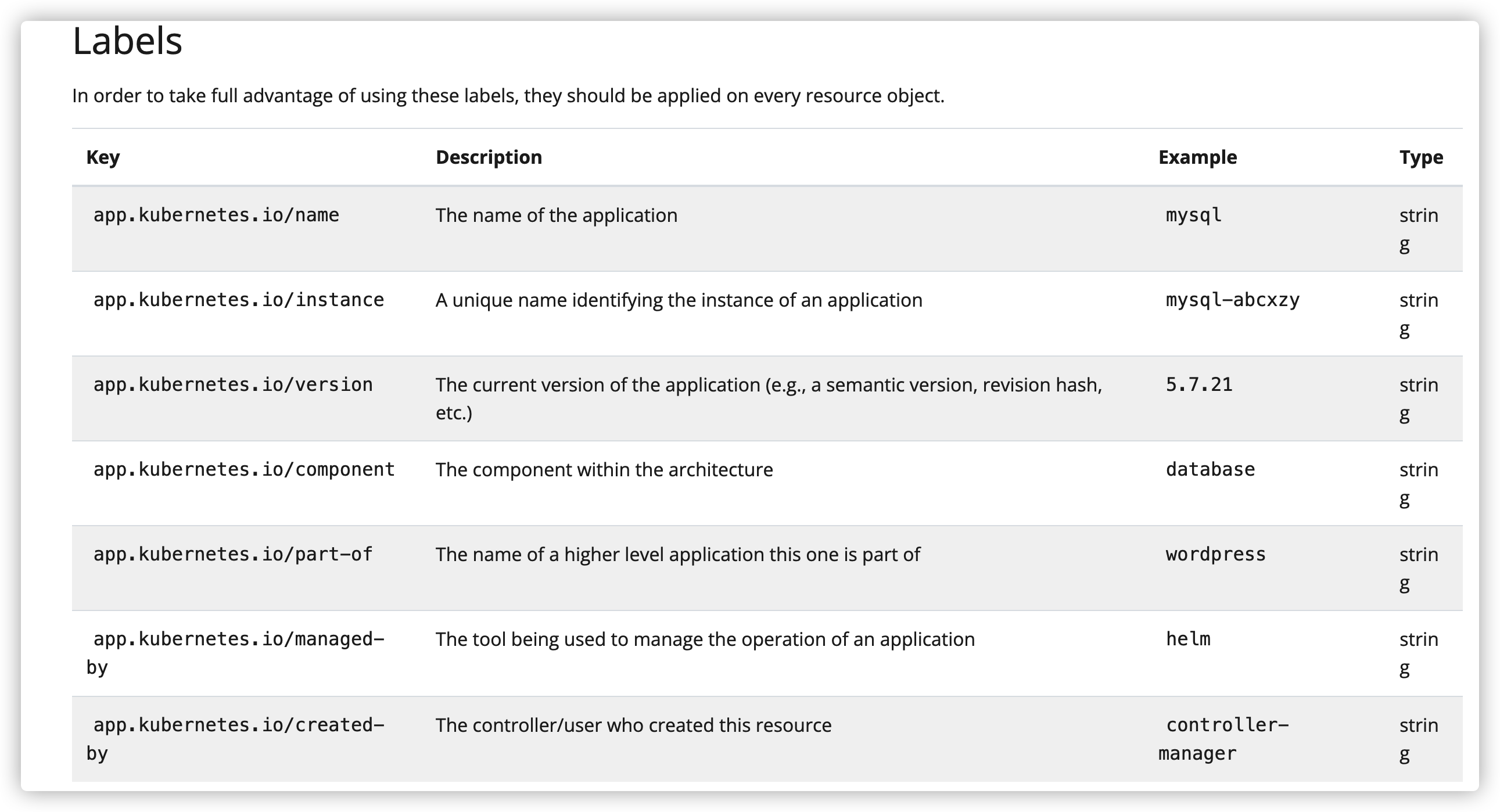
labels中可以做哪些标识声明
k8s的service可分为哪些类型各类型意义是什么">k8s的Service可分为哪些类型,各类型意义是什么?
答:根据Service的type不同,可分成四种模式:
-
ClusterIP:默认方式。根据是否生成ClusterIP又分为普通Service和Headless Service两类:- 普通
Service:通过为Kubernetes的Service分配一个集群内部可访问的固定虚拟IP(Cluster IP),实现集群内的访问。 Headless Service:该服务不会分配Cluster IP,也不会通过kube-proxy做反向代理和负载均衡。而是通过DNS提供稳定的网络ID来访问,DNS会将Headless Service的后端直接解析为podIP列表,它主要提供给StatefulSet来使用。
- 普通
-
NodePort:除了Cluster IP之外,还通过将service的port映射到集群内每个节点的相同一个端口,实现NodeIP:NodePort从集群外访问服务。 -
LoadBaLancer:和NodePort类似,不过除了使用ClusterIP和NodePort外,还会向所使用的公有云申请一个负载均衡器(负载均衡器后端映射各个节点的NodePort),实现从集群外部通过LoadBalancer访问服务。 -
ExternalName:是Service的特例。此模式主要面向运行在集群外部的服务,通过它可以将集群外部服务映射进k8s集群,且具备k8s集群内服务的一些特征(如具备namespace等属性),来为集群内部提供服务。此模式要求kube-dns为1.7版本以上。这种模式和前三种(除Headless Service)最大的不同是重定向信赖的是DNS层次,而不是kube-proxy。比如Service中定义中指定externalName的值为my.databaser.example.com。
k8s中service几种端口的不同含义">简述下k8s中Service几种端口的不同含义
port:表示service暴露在ClusterIP上的端口,是提供集群内部访问kubernetes服务的入口targetPort:就是containerPort,targetPort是pod上的端口,从port和nodePort上到来的数据最终经过kube-proxy流入到后端pod的targetPort上进入容器。nodePort:是提供从集群外部访问kubernetes集群服务的入口。
简述一下什么是ipvs模式?
答:在ipvs模式下,kube-proxy监测Kubernetes Service和Endpoints,调用netlink接口用于创建相应IPVS规则,同时分阶段的与Kubernetes Service和Endpoints同步IPVS规则。这种受控循环确保IPVS状态与需求状态相匹配。当访问一个Service时,IPVS直接把流量导向后端Pods
k8s中资源模型的理解及相比于ingress你觉得gateway对ingress做了哪些改进">讲一讲你对k8s中资源模型的理解?及相比于Ingress,你觉得Gateway对Ingress做了哪些改进?
答:资源最初将作为CRD存在于networking.x-k8s.ioAPI组中。未限定的资源名称将隐含在该API组中。
Gateway API的资源模型中,主要有三种类型的对象:
GatewayClass:定义了一组具有相同配置和行为的网关。GatewayClass是一个集群范围的资源。必须至少定义一个GatewayClass,Gateway才能够生效。实现Gateway API的控制器通过关联的GatewayClass资源来实现,用户可以在自己Gateway中引用该资源。 这些类似于Ingress的IngressClass和PersistVolumes的StorateClass。在Ingressv1beta1中,最接近GatewayClass的是ingress-class注解,而IngressV1中,最接近的类似物是IngressClass对象。Gateway:请求一个点,在这个点上,流量可以被翻译到集群内的服务。Gateway描述了如何将流量翻译到集群内的服务。也就是说,它定义了一个方法,将流量从不了解的Kubernetes的地方翻译到了解Kubernetes的地方。例如,由于负载均衡器、集群内代理或外部硬件负载均衡发送到Kubernetes服务的流量。虽然许多用例的客户端流量源自集群“外部”,但这并不强求。Gateway定义了对实现GatewayClass配置和行为合同的特定负载均衡器配置的请求。该资源可以由运维人员直接创建,也可以由处理GatewayClass的控制器创建。 由于Gateway规范捕获了用户意图,它可能不包含规范中所有属性的完整规范。例如,用户可以省略地址、端口、TLS设置等字段。这使得管理GatewayClass的控制器可以为用户提供这些设置,从而使规范更加可移植。这种行为将通过GatewayClass状态对象来明确。 一个Gateway可以包含一个或多个Route引用,这些Route引用的作用是将一个子集的流量引导到一个特定的服务上。Route:描述了通过Gateway而来的流量如何映射到服务。Route对象定义了特定协议的规则,用于将请求从Gateway映射到Kubernetes服务。HTTPRoute和TCPRoute是目前唯一已定义的Route对象。未来可能会添加其他特定协议的Route对象。
k8s的理解">说说你对k8s的理解
答:在k8s中ClusterRole接口和ClusterRoleBinding接口之间的关系是,前者把ServiceAccount接口创建出来的用户账号,这个账号通过ClusterRoleBinding接口完成账号与ClusterRole的绑定。
现在镜像是被拉取下来了,但是镜像拉取下来之后,为啥kubernetes显示run,run的含义在docker里很明显了,就是docker run -n 容器名称 使用的镜像,就是说只是拉取下来了并没有运行。英文的文章中的意思似乎是service引入只是只是更方便集群的统筹管理?其实只是单纯依赖于部署及Ingress就可以让程序可以正常运行了?
kubernetes集群中的应用">如何从外部访问Kubernetes集群中的应用?
Kubernetes中的Cluster Network属于私有网络,只能在cluster Network内部才能访问部署的应用,如何才能将Kubernetes集群中的应用暴露到外部网络,为外部网络提供服务呢?本文探讨了从外部网络访问Kubernetes Cluster中应用的几种实现方式。
- Pod和Service
先来了解一下Kubernetes中的Pod和Service的概念。Pod是一组有依赖关系的容器,Pod包含的容器都会运行在同个host节点上,共享相同的volumes和Network Namespace空间。Kubernetes以Pod为基本操作单元,可以同时启动多个相同的pod用于failover或者Load Balance。
Pod的生命周期是短暂的,Kubernetes根据应用的配置,会对Pod进行创建,销毁,根据监控指标进行扩容。Kubernetes在创建Pod时可以选择集群中的任何一个空闲的Host,因此其网络地址不是固定的。由于Pod的这一特点,一般不建议直接通过Pod地址去访问应用。
为了解决访问Pod不方便直接访问的问题,Kubernetes采用了Service的概念,Service是对后端服务的一组Pod的抽象,Service会绑定到一个固定的虚拟ip上,该虚拟ip只在Kubernetes Cluster中可见,但是其实该ip并不对应一个虚拟或者物理设备,而只是IPTables中的规则,然后再通过IPTable将服务请求路由到后端Pod中。通过这种方式,可以确保服务消费者可以稳定地访问Pod提供的服务,而不用关心Pod的创建、删除、迁移等变化以及用一组Pod进行负载均衡。
Service的机制如下图所示,Kube-proxy监听kubernetes master增加和删除Service以及Endpoints的消息,对于每一个Service,kube-proxy创建相应的iptables规则,将发送Service Cluster IP的流量转发到Service后端提供服务的Pod的相应端口上。
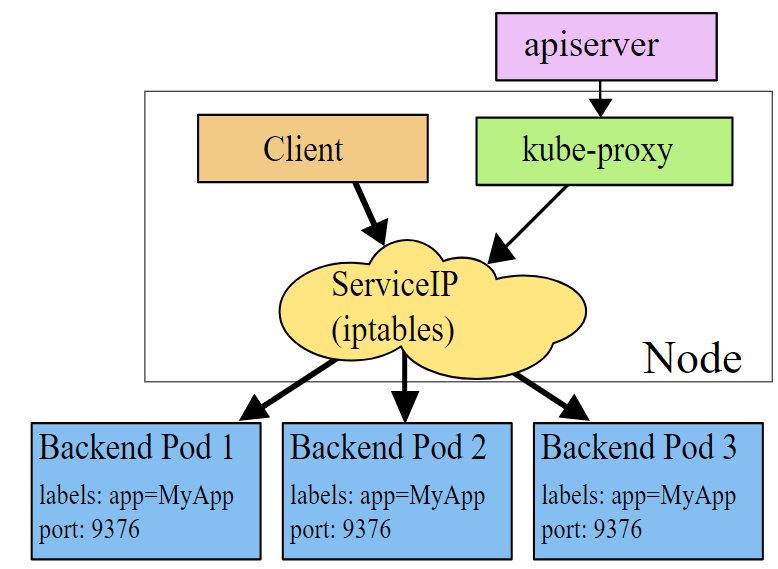
备注:虽然可以通过Service的ClusterIP和服务端口访问后端Pod提供的服务,但该ClusterIP是ping不通的,原因是ClusterIP只是iptables中的规则,并不对应一个虚拟或者物理网络设备
- Service类型
Service类型(ServiceType)决定了Service如何对外提供服务,根据类型不同,服务可以只在Kubernetes Cluster中可见,也可以暴露到Cluster外部。Service有三种类型,ClusterIP,NodePort和LoadBalancer。其中ClusterIP是Service的缺省类型,这种类型的服务会提供一个只能在Cluster内才能访问的虚拟IP,其实实现机制如上面一节所述。
通过NodePort提供外部访问入口
通过Service的类型设置NodePort,可以在Cluster中的主机上通过一个指定端口暴露服务。注意通过Cluster中每台主机上的该指定端口可以访问到该服务,发送到该主机端口的请求会被Kubernetes路由到提供服务的Pod上。采用这种服务类型,可以在Kubernetes Cluster网络外通过主机IP:端口的方式访问到服务。
注意:官方文档中说明了Kubernetes ClusterIP的流量转发到后端Pod有Iptables和kube proxy两种方式。但对NodePort如何转发流量却语焉不详。该图来自网络,从图看是通过kube proxy转发的。
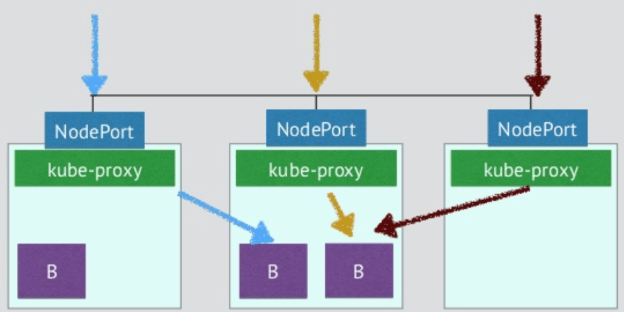
NodePort这种Service类型配置底层是采用kube-proxy接管入口流量的底层逻辑
//使用类型NodePort配置服务 kind: Service apiVersion: v1 metadata: name: influxdb spec: type: NodePort ports: - port: 8086 nodePort: 30000 selector: name: influxdb
通过NodePort从外部访问有下面一些问题,自己玩玩或者进行测试时可以使用该方案,但不适宜用于生产环境。
- Kubernetes Cluster Host的IP必须是一个well-known IP,即客户端必须知道该IP。但Cluster中的host是被作为资源池看待的,可以增加删除,每个host的IP一般也是动态分配的,因此并不能认为host IP对客户端而言是well-known IP。
- 客户端访问某一个固定的host IP存在单点故障。假如一台host宕机了,Kubernetes Cluster会把应用reload到另一个节点上,但客户端无法通过该host的NodePort访问应用了。
- 该方案设客户端可以访问Kubernetes host所在网络。在生产环境中,客户端和Kubernetes host网络可能是隔离的。例如端可能是公网中的一个手机APP,是无法直接访问host所在的私有网络的。
因此,需要通过一个网关来将外部客户端的请求导入到Cluster中的应用中,在Kubernetes中,这个网关是一个4层的Load Balance
###### 通过Load Balancer提供外部访问入口
通过Service的类型设置为LoadBalancer,可以为Service创建一个外部Load Balancer。Kubernetes的文档中声明该Service类型需要云服务商的支持,其实这里只是在Kubernetes配置文件中提出了一个要求,即为该Service创建Load Balancer,至于如何创建则是由Google Cloud或Amazon Cloud等云服务提供商的,创建的Load Balancer不在Kubernetes Cluster的管理范围中。Kubernetes 1.6版本中,WS,Azure,CloudStack,GCE和OpenStack等云提供商已经可以为Kubernetes提供Load Balancer。下面是一个Load Balancer类型的Service例子:
kind: Service
apiVersion: v1
metadata:
name: influxdb
spec:
type: LoadBalancer
ports:
- port: 8086
selector:
name: influxdb
部署该Service后,我们来看一下Kubernetes创建的内容:
kubectl get svc influxdb
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
influxdb 10.97.121.42 10.13.242.236 8086:30051/TCP 39s
Kubernetes首先为influxdb创建了一个集群内部可以访问的ClusterIP 10.97.121.42。由于没有指定NodePort端口,Kubernetes选择了一个空闲的30051主机端口将service暴露在主机的网络上,然后通过Cloud Provider创建一个Load Balancer,上面输出中的EXTERNAL-IP就是Load Balancer的IP。
$ neutron lb-vip-show 9bf2a580-2ba4-4494-93fd-9b6969c55ac3
+---------------------+--------------------------------------------------------------+
| Field | Value |
+---------------------+--------------------------------------------------------------+
| address | 10.13.242.236 |
| admin_state_up | True |
| connection_limit | -1 |
| description | Kubernetes external service a6ffa4dadf99711e68ea2fa163e0b082 |
| id | 9bf2a580-2ba4-4494-93fd-9b6969c55ac3 |
| name | a6ffa4dadf99711e68ea2fa163e0b082 |
| pool_id | 392917a6-ed61-4924-acb2-026cd4181755 |
| port_id | e450b80b-6da1-4b31-a008-280abdc6400b |
| protocol | TCP |
| protocol_port | 8086 |
| session_persistence | |
| status | ACTIVE |
| status_description | |
| subnet_id | 73f8eb91-90cf-42f4-85d0-dcff44077313 |
| tenant_id | 4d68886fea6e45b0bc2e05cd302cccb9 |
+---------------------+--------------------------------------------------------------+
$ neutron lb-pool-show 392917a6-ed61-4924-acb2-026cd4181755
+------------------------+--------------------------------------+
| Field | Value |
+------------------------+--------------------------------------+
| admin_state_up | True |
| description | |
| health_monitors | |
| health_monitors_status | |
| id | 392917a6-ed61-4924-acb2-026cd4181755 |
| lb_method | ROUND_ROBIN |
| members | d0825cc2-46a3-43bd-af82-e9d8f1f85299 |
| | 3f73d3bb-bc40-478d-8d0e-df05cdfb9734 |
| name | a6ffa4dadf99711e68ea2fa163e0b082 |
| protocol | TCP |
| provider | haproxy |
| status | ACTIVE |
| status_description | |
| subnet_id | 73f8eb91-90cf-42f4-85d0-dcff44077313 |
| tenant_id | 4d68886fea6e45b0bc2e05cd302cccb9 |
| vip_id | 9bf2a580-2ba4-4494-93fd-9b6969c55ac3 |
+------------------------+--------------------------------------+
$ neutron lb-member-list
+--------------------------------------+--------------+---------------+--------+----------------+--------+
| id | address | protocol_port | weight | admin_state_up | status |
+--------------------------------------+--------------+---------------+--------+----------------+--------+
| 3f73d3bb-bc40-478d-8d0e-df05cdfb9734 | 10.13.241.89 | 30051 | 1 | True | ACTIVE |
| d0825cc2-46a3-43bd-af82-e9d8f1f85299 | 10.13.241.10 | 30051 | 1 | True | ACTIVE |
+--------------------------------------+--------------+---------------+--------+----------------+--------
可以看到OpenStack使用VIP 10.13.242.236在端口8086创建一个LoadBalancer,LoadBalancer对应一个LoadBalancer Pool里的两个成员10.13.241.89 和 10.13.241.10,正是Kubernetes的host节点,进入LoadBalancer流量被分发到这两个节点对应的Service NodePort30051上。
但是如果客户端不在Openstack Neutron的私有子网上,则还需要在LoadBalancer的VIP上关联一个FloatingIP,以使外部客户端连接到LoadBalancer。
部署LoadBalancer后,应用拓扑结构如图所示(注:本图假设Kubernetes Cluster部署在Openstack私有云上)。
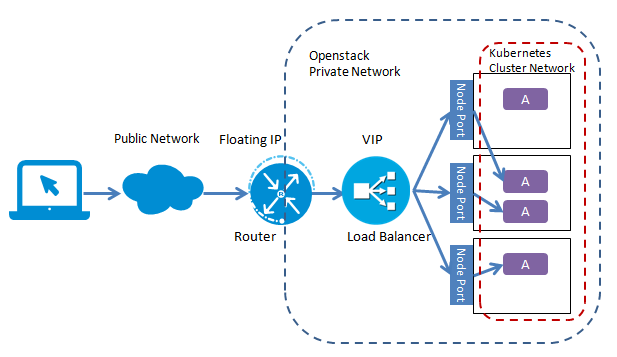
如果客户端不在Openstack Neutron的私有子网上,VIP需要关联一个FloatingIP,以使外部客户端连接到LoadBalancer
# 针对于如果Kubernetes Cluster如果是不支持LoadBalancer特征的Cloud Provider或者是裸机上创建的,可以让其实现LoadBalancer类型的Service吗?
答:Kubernetes并不直接支持LoadBalancer,但是我们可以通过Kubernetes的扩展来实现,可以监听Kubernetes Master的Service创建消息,并根据消息部署相应的Load Balancer(如Nginx和HAProxy),来实现LoadBalancer类型的Service。
通过设置Service类型为四层的Load Balancer,当只需要向外暴露一个服务的时候,可以直接采用这种方式。但是一个应用需要同时对外暴露多个服务时,采用该方式会为每个服务(IP+Port)都创建一个外部Load Balancer。如下图所示:
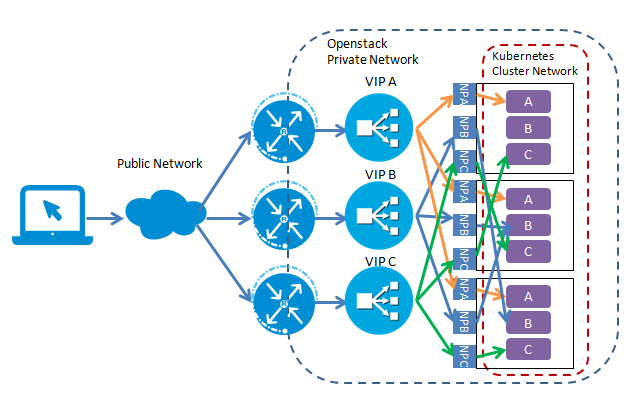
同个应用提供多个服务会为每个服务都创建一个LoadBalancer
一般来说,同一个应用多个服务/资源会放在同一个域名下,这种情况下,创建多个LoadBalancer是完全没必要的,反而带来了额外的开销和管理成本。直接将服务暴露给外部用户也会导致前端和后端耦合,影响后端架构的灵活性,如果以后业务需求对服务进行调整会直接影响到客户端。可以通过Kubernetes Ingress进行L7 Load Balancer解决该问题。
- 采用Ingress作为七层LoadBalancer
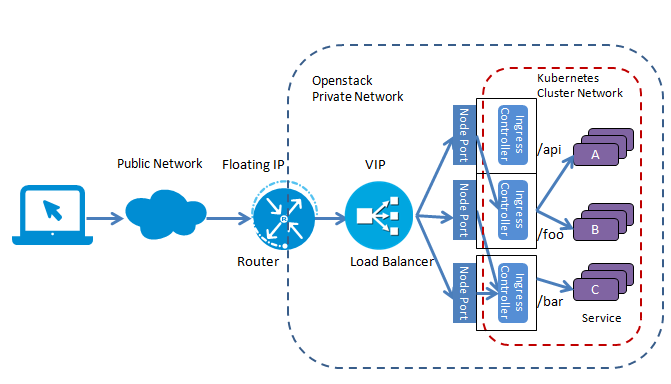
L7 Load Balancer采用Ingress作为Load Balancer的拓扑图
这里Ingress起到了七层负载均衡器和HTTP方向代理的作用,可以根据不同的url把入口流量分发到不同的后端Service。外部客户端只看到foo.bar.com这台服务器,屏蔽了内部多个Service的实现方式。采用这种方式,简化了客户端的访问,并增加了后端实现和部署的灵活性,可以在不影响客户端的情况下对后端服务进行调整部署。
看如下例子:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: test
annotations:
ingress.kubernetes.io/rewrite-target: /
spec:
rules:
- host: foo.bar.com
http:
paths:
- path: /foo
backend:
serviceName: s1
servicePort: 80
- path: /bar
backend:
serviceName: s2
servicePort: 80
注意这里Ingress只是虚拟主机路径分发的要求,可以定义多个Ingress,描述不同的七层分发要求,而这些要求需要由一个Ingress Controller来实现。Ingress Controller会监听Kubernetes Master得到Ingress的定义,并根据对Ingress定义对一个七层代理进行相应配置,以实现Ingress定义中要求的虚拟主机和路径分发规则。Ingress Controller有多种实现,Kubernetes提供了一个基于Nginx的Ingress Controller。要注意的是,在部署Kubernetes集群时并不会默认部署Ingress Controller,需要我们自行部署。
下面是部署Nginx Ingress Controller的配置文件示例,注意这里为Nginx Ingress Controller定义了一个Load Balancer类型的Service,以Ingress Controller提供一个外部可访问的公网IP。
apiVersion: v1
kind: Service
metadata:
name: nginx-ingress
spec:
type: LoadBalancer
ports:
- port: 80
name: http
- port: 443
name: https
selector:
k8s-app: nginx-ingress-lb
---
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: nginx-ingress-controller
spec:
replicas: 2
revisionHistoryLimit: 3
template:
metadata:
labels:
k8s-app: nginx-ingress-lb
spec:
terminationGracePeriodSeconds: 60
containers:
- name: nginx-ingress-controller
image: gcr.io/google_containers/nginx-ingress-controller:0.8.3
imagePullPolicy: Always
//----omitted for brevity----
就可以把Ingress Controller理解成一个获取Ingress定义的一个接口,你要获取Ingress的详情,就要通过这个接口来详细的读取,而Nginx就可以作为一种Ingress的支持形式。如果Nginx可以作为Ingress的一种形式,那么HAProxy应该也可以作为一种Ingress的支持形式的。采用L7 Load Balancer这种七层Ingress作为负载均衡访问的形式,把绑定在同一域名下的不同子路径与对应服务进行了依依对应,你访问域名下的某个url代表一种服务,访问域名下的另一个url地址就代表另一种服务。针对于这些无名下的子路径,可以对于入口请求进行精确的匹配规则,可以是前缀匹配,也可以是后缀匹配,可以是完全匹配,也可以是部分匹配,这个你自己定义处理规则就好了。之前读文章,跟着操作,
# 关于k8s的tls的配置,要注意哪些问题?
答:要使cert-manager可以连接到你的服务器,这个怎么理解?就是服务器上安装了k8s是不是就有了cert-manager接口了,是不是?那么,cert-manager就在kubernetes所在的服务器上,那是不是一定能连接上,为啥还要先确定这个问题呢?
现在理解了Ingress、CRD IngressRoute和Gateway API是路由入口的三种支持的访问形式,那么,它到底是属于EntryPoints呢?还是属于Routes呢?
我之前在手打小事例的时候,那个whoami的应用做测试,曾经对于tls配置的测试范例里面,是用命令生成过类似于token之类的东西的,很长的一个字串,是不是在使用的时候,valueFrom中就要把类似于这种走`Secret`接口的文件引入进来,然后用xxRefs的方式把它的值取到,供tls验证的过程中来使用呢?
CRD是CustemResourceDefinition的简称,在其中可以对于集群部署提供哪些支持进行声明,比如说在crd相关文件中的provider部分,可以对于路由支持哪些形式的处理方案提供声明,这也是Traefik介绍部分,单独把provider作为该边缘路由的一个组成部分拿出来说的原因,因为它可以用云服务端、键值存储、引擎的方式声明针对外部请求监听的端口之类的。而针对于路由,现在系统是提供三种方式供选择,来实现请求的路由化,那是哪三种规则呢?第一种就是CRD IngressRoute,第二种方式是默认的Ingress的方式,第三种方式是Kubernetes Gateway API的方式。而一个请求进来,先经过EntryPoints,也就是请求被监听到以后,要能知道什么样的请求被定向到什么服务上面进行处理,这也是ROUTE存在的原因,在ROUTE中可以配置相应的路由规则,把一些共前缀的请求定向到api服务还是通用的管理后台服务。同时在ROUTE中还可以引入MIDDLEWARES,什么含义呢?就是一些请求可能不允许你直接访问,要有一些验签规则,或者一些请求的头信息不足以完成monitor全链路的闭环,这个时候,你可以人为在这个中间件中针对于HEADERS加入一些识别请求端环节端的可识别头信息,方便进一步追踪等等。而请求到了对应服务,也包括直接就打到POD上,还是用ld的原理,打到一个集群上面,然后集群配置负载均衡的方案,让请求均匀分配到多个node的组成pod上,完成请求的分发,提高系统整体的并发能力。
# 哪个命令可以查看内存的使用情况?
ps -e -o pid,user,cpu,size,rss,cmd --sort -size,-rss | head
# cmctl如何安装?
进入到相应目录,之后执行如下命令:
OS=$(go env GOOS); ARCH=$(go env GOARCH); curl -sSL -o cmctl.tar.gz <https://github.com/cert-manager/cert-manager/releases/download/v1.7.2/cmctl>-$OS-$ARCH.tar.gz
tar xzf cmctl.tar.gz
sudo mv cmctl /usr/local/bin
# 说一说你对k8s整个部署的理解?
对于Service的类型,默认是ClusterIP这种方式,特点是只向集群内暴露,只供集群内节点间的访问,也就是说你想查看各集群的特点,你需要在定义VIP Master节点以后,或者是在该节点上允许运行服务,或者是不允许,但是无论允许与否,你只能通过登录到这台服务器上,才能对集群内其他服务器做管理。如果你不设置成这种类型的话,默认就是ClusterIP的方式。但是这个时候,你可以通过Ingress的引入来接管集群的访问处理,而不必选择NodePort的方式,直接在该Service上开节点,供外部公共访问。如果想用Ingress的话,因为整个k8s的架构都是面向对象管理的,所以,Ingress也要有个统筹管理的地方,这个地方就是IngressController,通过它可以查看Ingress的详细信息。这样在Ingress中指定创建好的服务,也能够支持在外部环境对Service的访问。
# 如何删除k8s中的`ingress-nginx`引入的`ingress-controller`等,即`RABC`权限控制等引入的接口?
答:可以先用`kubectl get ns`查看`ingress-nginx`关键词出现所在的命名空间的具体值。然后用`kubectl delete all --all -n ingress-nginx`就可以把廖命名空间下所有相关的都删除掉
如果你的`ingress controller`没有专门安装在相应命名空间下,那你就不得不一个个手动将它们删除了。
kubectl delete ingress ingress-nginx
kubectl delete deployment ingress-nginx
kubectl delete service ingress-nginx
# 针对本地开发环境,说说你对Docker Desktop for Mac的理解?
答:Docker Desktop for Mac是一个MacOS的集成工具,它已经帮你把docker及kubernetes都安装好了。它的虚拟机使用的是Hyperlink,这个我有印象的就是之前在windows开发过程中,想在windows环境安装一个Linux的操作系统,你可以在windows的应用程序里把虚拟机中的Hyperlink给启动了,这样你就可以在当前使用的Windows系统中部署其他操作系统了。说到底,是一个把其它集群管理的工具集成到了一块,方便开箱即用。但是与你单独在自己本机独立的安装docker,安装kubectl,安装kubeadm没有本质的区别。但是如果系统已经安装了Docker Desktop for Mac的话,重复安装的话,可能会导致很多集成工具内置的工具与Mac系统再独立安装有冲突,要解决这个问题,最好就是使用brew命令独立的安装用到的工具,其实也没多麻烦。
我现在发现了,如果我在MacOS上直接用minikube profile lsit显示我没有初始化环境,之后我用命令`minikube start`的话,会自动把我已经在本机安装的`Docker Desktop for Mac`给关闭退出,同时把其它之前集成工具提供的支撑命令行运行的集成环境管理工具自动再帮我安装一份。
按照文档中所指出的,如果服务的类型没有选择默认的`ClusterIP`的话,如果你指定成了`LoadBalancer`的话,如果你是在本机安装环境下面,会导致用命令`kubectl get svc --namespace=ingress-nginx`的`EXTERNAL-IP`一直处于`pending`的状态,这会导致一个问题,就是在你配置好`pod`之后,需要有`Entrypoints`可以承接入口请求,然后根据`Service的`配置的访问规则,通过Route把请求定向到具体的`Pods`去处理,依照这样的逻辑,如果你采用IngressController作为Ingress的统一资源管理的入口,就涉及到你可能在ingress的访问hosts中设置相应域名,而这些域名要能正确被forward到具体处理请求的pod上面的话,就需要用到这个`EXTERNAL-IP`,要把它和你指定的域名在`/etc/hosts`文件中做好绑定,这样才能根据域名正确的找到处理它的服务。而本机环境不具备让`EXTRENAL-IP`生效的基础,除非你使用了`AWS`或者`Aliyun`提供的服务器。而这个问题,看一些tensorflow上的回答,用`minikube tunnel`命令就可以解决。不知道现在系统集群管理通过minikube start之后帮我生成出来的管理工具包组合及它们提供的支撑命令,能否让这个只有在公网云服务器提供商能得到解决的问题是否能在我本地得到解决。
# 如何查看系统中相应命令所信托的工具是通过brew进行安装的,还是其它安装包携带进来的?
答:以minikube来举例,用`which minikube`可以查看到`minikube`的安装位置,再由命令`ls -la /usr/local/bin/minikube`会出现如下的图:
 由该图可知这个minikube是由
由该图可知这个minikube是由Docker Desktop for Mac这个应用提供的。
# 如何用brew内核`homebrew/core`自带的`minikube`替代`Docker.app`自带的`minikube`?
答:可以使用的方式是先用命令`brew link --overwrite --dry-run kubernetes-cli`预览一下要发生什么样的替换,再执行`brew link --overwrite kubernetes-cli`完成实际的替换,再用命令`ls -la /usr/local/bin/minikube`查看一下是否命令实际提供的包已经发生改变。
If you are on a systemd-powered system, you can try to troubleshoot the error with the following commands:
- 'systemctl status kubelet'
- 'journalctl -xeu kubelet'
# 如何更好的确认minikube安装过程中有关hyperkit或者是docker的报错?
答:可以用`minikube logs --file=logs.txt`,这样把日志打印到文件里,从中可以更方便找出引发问题的原因。
# 怎么可以把课程讲的清晰?
答:先讲实现的底层逻辑,在涉及到相应知识点的部分,可以适当扩展,如果之前没有讲过类似情况的处理,那么,这里可以提出个事例,讲解一下它实现的原理,再把它的应用回归到具体实战demo的某个部分。课程讲解遵循循序渐进的逻辑,一步一步走,从简单到复杂一点一点走,先实现一个简单的爬虫,只实现基础的功能。实现之后,预告一下现在要对基础版本做哪些升级优化,运用到了什么原理,讲解完基础之后,开始实战部分。多任务爬虫再升级就成了分布工爬虫,讲解原来,然后再进入代码部分的实践。
# 如何改装自己的http让它支持很多企业的防爬虫屏蔽机制?
答:如果你是自研的框架可能要自己来实现。如果用市面上开源封装好的一些库,它本身提供了自己自定义头信息等的设置,根据自己的实际需求选择就可以了。
{"method":"DemoService.Div","params":[{"A":3,"B":0}],"id":1234}
# 对于go语言的k8s部署,你有什么想说的?
先要对于k8s有一个宏观的认识,编后即弃的dockerslim作用是把镜像拉下来完成编译。至于你用不用docker做编译都是可以的,你也可以选择用containerd,如果你用腾讯云服务器的话。建立集群的时候,可以选择建立常规集群和弹性集群,这里就会有选项让你选择使用什么编译容器,这里建议选择用containerd。
deployment中的label中的mata是给etcd相关api用的,而它的关键字XX部分的replicat指定分片的数量,也就是建立几个cpu,limit这些资源指定的pod的数量。还有哪些附属的参数可以在这部分指定呢?你要指定使用哪些镜像,以及这些镜像的版本。这些服务创建之后,会有一个虚拟的ip,但是这个虚拟的ip无法直接访问集群中的pod,你只有用docker exec -it xx -- /bin/bash,把它输出到当前窗口中,才能像常规的部署一个操作系统以后,进去做相应的调整。
只建立了deployment是无法让它在公网有效的,这个时候还需要配置Service,而在其中用label指定nginx实际上就是前面deployment中的给系统服务打的label,意为按标签筛选打相同标签的服务。针对于这些pod,你可以指定它们运行的端口,这样这些服务就可以被访问到了。
而对于go语言,忽略掉中间层可以大大减少打包镜像的体积,可能其它语言不会这么明显,但是go语言是特别明显的。那么,怎么把middleware生成的镜像依赖去除掉,只保留最后生成的二进制文件呢?可以采用分段式的编译,把第一步用go语言最终生成编译文件作为第一步,第二步只拷贝第一步生成出的二进制可执行文件,同时在ENTRYPOINT里面启一个新的位置,让当前二进制可执行文件在第二步里到新位置,但是可执行性依然存在,这样可以大幅度降低文件的体积。
针对于go项目的部署,有些签名相关的东西,最好不要直接打包进镜像,我理解这些肯定就用volume的方式,把本地的映射到容器相关位置,这样就算运行程序对它有依赖也可以找到文件。对于部署中通用的部分,比如说mongodb中配置的服务器地址,比如说项目运行在哪个端口,这些都可以作为通用部分提出来,以var变量进行声明,以flag package中的flag.String("","","help information")进行包装,别忘了在它的作用域范围内上面要有flag.Parse()的声明,这些才能有效,对于引用的部分用指针`*xx`的方式声明该变量就可以了。
本地如果想把它想跑顺了,再到服务器上部署的话,可以用go中的一个package叫做kind,安装之后,它可以帮你生成一些文件,这些文件在vscode编辑器安装完kubernetes之后,可以导入的方式,在vscode中达到可视化管理的目的。我记得操作的时候,是声明了一个自定义的coolcar之类的配置文件,而go语言原来自带的flag是不支持环境变量的,但是重新下载的flag是支持环境变量的。可以直接用`export xxx=`之类的,直接把一些固定的声明设置成为环境变量,例子举一个,从8080端口如果只是声明式的指定运行起来,还是走默认的,但是如果用新的方式,直接读系统环境变量了,直接就可以读9000端口作为启动端口了。
controll-planate是调度集群用的?kind中套了一层k8s?
# 对于ENTRYPOINTS和CMD的理解?
ENTRYPOINTS作为一个入口,可以在其中写命令,执行顺序它在前CMD中还有的话,会一起执行,比如说ENTRYPOINTS ["echo","a", "b"],CMD中是["c","d"],那么,运行镜像的时候,会在控制台输出abcd。Dockerfile中的EXPOSE只是一种声明,真正暴露端口不是靠它。如果本地制作了一个镜像,想做点调整,把这些调整保留下来,要执行docker commit。查看本地匹配某关键字的所有镜像,可以用的命令是`docker image|grep xx`。
# 为什么
在k8s中,一些敏感的信息最好的处理方式,肯定不是直接声明在`yaml`文件中,所以可以用`kubectl create secret`
kubectl -f xx.yaml edit 对于相应的yaml文件进行编辑
kubectl history 相应的服务/相应的pod/相应的deployment
针对于不同情况,选用的不同组织模式,比如说常用的deployment,statefulSet,DaemonSet,CrontabSet,用deployment的好处就是它能根据你制订的pod计划,动态维护集群处于你设置的参数范围内
kubectl watch -n 1 kubectl get pods -A 这样可以动态的监控pods的变化情况
NodePort和ClusterIP之间的区别是前者可以在你的pod对应的内网ip上开一个端口,你通过这个端口可以访问相应的pods,无论通过curl/wget方式的,还是浏览器方式的访问。
想要理解整个k8s的部署过程,有两个组成部分尤其重要,一个就是pod内部的kubectl,它有一个kubectl-proxy的组成部分,用人类社会部门结构类比的话,它就相当于看大门的大爷,比如公司立项了一个飞机开发的项目,现在是在podB中实施该项目,那么podA、podB、podC的看门大爷间是互通信息的,这个时候来一个人要参观一下项目,首先就要问这个看门大爷确定具体项目实施地点,不然就可能导致空跑。而etcd相当于档案室,签订的一些重大项目的文字内容最后都要安家于档案室,而所有领导层都是不直接与pod,也就是相应的工厂pod直接通信的,都是通过api来完成的,这里api就相当于秘书处。而整个k8s集群的编排部署就类似于一个公司的架构组成。kubectl-controller就相当于决策层,决策层有很多的master node组成,原因就是不能因为某个决策层人员由于什么事情出现问题不能继续工作了,决策层可以通过投票选举的方式迅速确认出新的master,不至于耽误业务的开展。而一个k8s集群中的master是有很多个的,作为主master的后备,虽然实时生效起作用的只有一个。kubectl planet相当于集群运行的核心。
nfs存在的好处就是如果固定绑定到一个pod中相应位置来留在信息,假如该节点出现问题,可以动态转移节点,但是这些资源留在原地,无法支持新起节点的服务。nfs配置可以采用volumeFrom声明的方式,声明指定内容就包括它下面volumes部分,即相应的名称,及具体的volume的from及to,也就是本地路径哪里,绑定nfs具体路径是哪里。但是还存在一个问题,无法对资源进行统一管理,比如我限制某个nfs只能用几G的资源,这个时候就涉及到两个概念,一个是持久存储卷一个是预声明是存储卷,后者可以直接指定它使用的最大体积,那么,实际操作中如果超过设定资源的使用,就会报错。
ConfigMap是对一些配置文件的组成元素的声明方式,指定的时候可以指定配置文件从哪里取,取哪些部分。比如说redis.conf | appendon yes,含义就是key,value组成部分key是redis.conf,value就是|竖线及后面的内容。kubectl create secret的创建也是类似的意义,把敏感信息的管理统一到一处,ConfigMap是把配置信息的管理统一到一处,后面就可以通过声明的配置文件的名称或者是secret的名称,指定后就可以读取其中的内容了。
针对于已存在的配置的动态扩容或者是动态升级降级主要是针对于什么组成部分进行修改?比如说由原来的nginx默认的最新版本,改成指定一个版本,所使用的方式就是kubectl 针对的pod的名称 修改什么,比如说my-nginx,针对它的镜像进行修改,指定的方式就是my-nginx --image=xx这种方式。
kubectl rollout history (TYPE NAME|TYPE/NAME) flags
service层,pods层和ingress controller层之间的关系是什么?pods层含义就是一个pods下面,在端口不冲突的情况下可以启很多的镜像服务,比如说nginx服务在podA中以80端口启动,比如tomcat服务在podA中以8080端口进行启动,后面还有好多podB、podC、podD...这些pod间通过`metadata中的name: xxx`形成了可以被统筹管理的局面,这样达到的效果就是内容的pod间可以达到负载均衡的效果。但是如果完成相同功能的一些pods各自都有自己的服务,会启很多浪费的service,同时还达不到服务高可用的目的,所以,就把一些功能相同的pod上层封装一个service,让不同的service处理不同类型的业务,比如说serviceA处理订单的,serviceB处理产品的,serviceC处理售后的。为了流量的控制更加的高效,使c端用户的请求能够迅速的被打到对应的service层,所以能不能把它的上层再封一个服务,把相应请求流量定向到对应service层呢?这就是ingress出现的意义,它可以把相应的流量定向到相应service层来具体提供服务。对于ingress声明的方式也很简单,声明host就是域名,下面就是对应的rule,可以采用前缀的方式,比如你的服务在172.31.0.4:30024端口提供服务,那么,下面的container的部分,指定service就指定成172.31.0.4:30024
在`deployment`声明的`yaml`文件中,可以在`spec`部分通过声明`replicat`数量的方式来指定启动几个容器来支持该`deployment`对外提供服务。下面的container的部分,可以用`--image:xx`的方式,把用到的镜像都声明好。参数中`--port`是服务对外开放的接口,而`targetPort`是把服务流量定向到窗口的什么端口做具体处理。
# 系统:CentOS 7.8
# 关闭 SELinux
setenforce 0 && sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config
# 禁用防火墙
systemctl stop firewalld && systemctl disable firewalld && echo "vm.swappiness = 0" >> /etc/sysctl.conf && swapoff -a && sysctl -w vm.swappiness=0
# 安装一些简单工具
yum install -y zip unzip lrzsz git epel-release wget htop deltarpm
# 服务器更换 CentOS YUM 源为阿里云
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
wget -O /etc/yum.repos.d/CentOS-Base.repo <http://mirrors.cloud.tencent.com/repo/centos7_base.repo>
wget -O /etc/yum.repos.d/epel.repo <http://mirrors.cloud.tencent.com/repo/epel-7.repo>
yum clean all && yum makecache
yum update -y
# 时间同步
timedatectl && timedatectl set-ntp true
# 设置 hostname,这个最好设置一下,并且设置全部小写字母和数字,一定要小写字母
hostnamectl set-hostname master
# 开始在所选安装机器上设置免密登录,我这里选择了 master1
ssh-keygen -t rsa -b 2048 -N '' -f ~/.ssh/id_rsa
# 这里都是内网地址
ssh-copy-id -i /root/.ssh/id_rsa.pub -p 22 [email protected]
# 测试下是否可以免登陆
ssh -p 22 [email protected]
# 针对kubesphere打包集群部署的功能,你有什么样个人的理解?
答:kubesphere后台提供了一个完整的权限认证的系统,可以帮助企业更快速搭建基于CICD/opovs的一套系统,比如说hr可以对该系统所有人员进行添加。即使是系统的boss也需要由hr人员进行添加,创建不同地区的部分,部门下有项目,到项目这一层级,把项目划归给某个人,该人有权限基于当前项目来用kubesphere提供的界面画的功能,实现集群部署的相关。
# 有哪些方式可以访问到集群内的结点?
答:第一种方式就是节点启动完毕以后,会有一个内网ip,你可以通过这个ip,加上应用所运行的端口号就能达到访问该节点的目的。另外一种是使用命令规范,也就是服务的名称.svc.default。这是默认情况,通常你创建部署,如果没明确指定`-n`,即它属于的命名空间,那么,自定义的`deployment、statefulset、DaemonSet、ReplicatSet`都使用这个默认的`namespace`。k8s中如果用`NodePort`方式来指定暴露的端口,它端口暴露范围通常是`0~32767`之间,所以你在自己网站的安全规则里面,要放开这个端口范围。想让集群内的节点,比如说`container`的`replicat`属性上指定成了值为3,那么,就会依照指定的镜像启动三个pod来集中提供服务,如果你想这三个服务之间相互可以访问得到,那就要开启`访问互信`,这样才能互相访问节点。
# kubesphere的存在好处是什么?
答:比如一些需要通过命令行,或者是`yaml`文件声明的集群部署属性,如果你对命令行不清楚,或者对`yaml`文档声明形式不清楚,你可能无法起步。但是kubesphere因为是基于图形界面的,所以,你通过菜单上选项的切换,及表单的填写,就可以把集群给运行起来。可以提高将效率的步骤方式是,把你之前部署时用到的`docker`相关的命令,或者借鉴于之前部署的`docker-compose.yml`文件,一一对应的在`kubesphere`的后台进行对应创建。比如说docker中有volume的指定,那你可能就要在kubesphere后台创建相应的持久卷nfs,并创建相应目录,做为持久化存储的位置。相应的有状态服务,如mysql、redis等的部署,都有初始化文件及环境变量,那你就要让key作为类似my.cnf或redis.conf文件,它原来里面的内容就作为value。针对于有些java项目,可能启动的时候,不是把目录映射指定就完了,可能用到了两个很具体的文件,比如说`.xml`文件作为sping项目的bean配置文件,另外还有一个其它文件,是支持java项目运行起来的必备文件,那指定的时候,也注意填完路径后,要specify具体的文件,下面也要把文件名对应容器内同名的文件名指定好。kubesphere默认根据安装环境,以最小可用性进行安装,后续你可以根据需求,通过插件等方式进行扩展。有个kubesphere的文件,根据该文件改`true/false`可以实现功能的开启和关闭。
# 如何减小构建镜像的体积?
如某些java项目,编译生成的jar文件,是最终运行的文件,那么,你可以分步指定来进一步缩减构建出镜像的体积。
# 一般中间件都是有状态的服务,你认可这种说法吗?
答:认可。
# 对于日志监控,你有什么看法?
答:针对于java项目,常用部署方式里采用的是`daemonSet`的部署方式,各容器收集完日志,上报到统一地方进行汇总,暴露地址给相应开发人员,方便定位问题出现的位置。java中常用的监控及日志记录的组件有`metrics、poremthus、grabana`。
# 如何设置安全级的出入规则,能够更好的保护集群端口放行的安全性?
答:因为现在做出入站规则的方式有很多,我当时的服务器上,就存在有`firewall-cmd、iptables和ufw`三种方式,我当时甚至不知道哪种方式是真正有效的,可以用下面的命令进行判断。
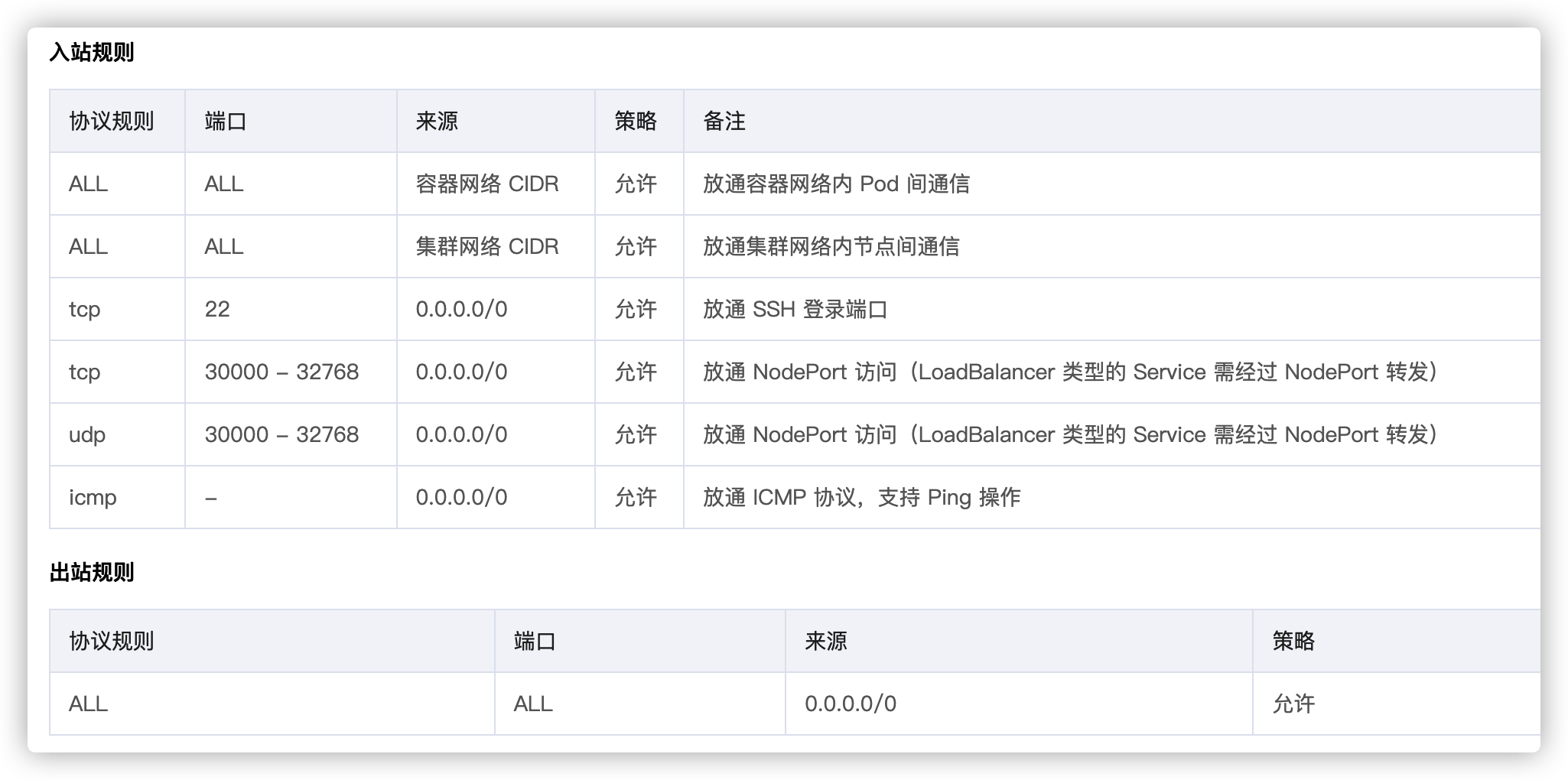
以腾讯云服务器
iptables status 查看iptable组件的状态
firewall-cmd --state 查看firewall-cmd的状态
ufw status 查看ufw的状态
最终我得知我服务器上使用的是`iptables`,根据上面截图的规则,要把相应端口开放,方法如下。
注意前面的是tcp的开放 后面的是udp的开放
# kubesphere如果想正常启动,要怎么对端口进行开放?
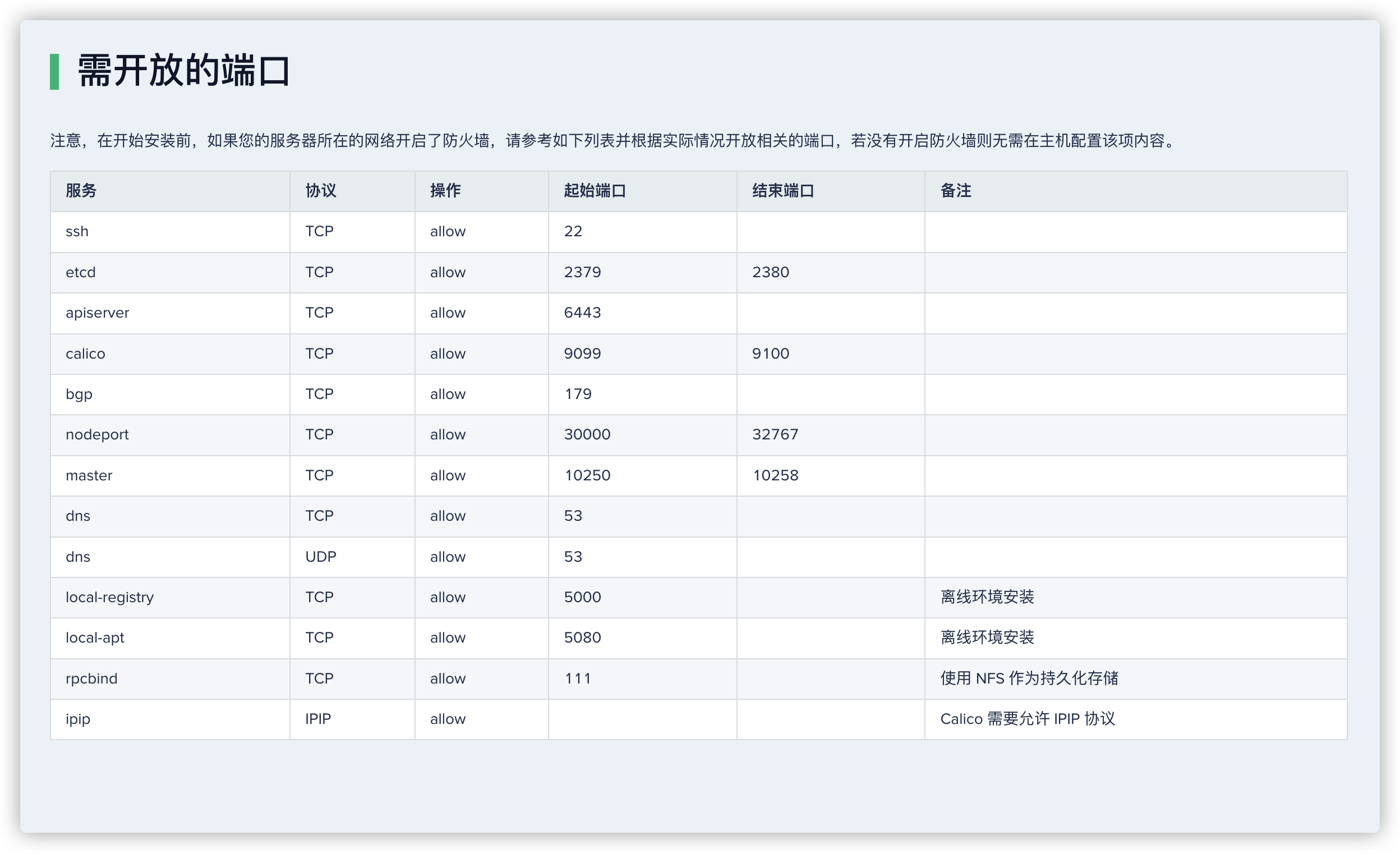
kubesphere要开放需要的端口汇总
# 如何修改ssh的登录端口22到其他值?
1. 修改端口:vi /etc/ssh/sshd_config
# Port 22
Port 60022
2. 重启sshd:`systemctl restart sshd`
3. 修改服务安全策略
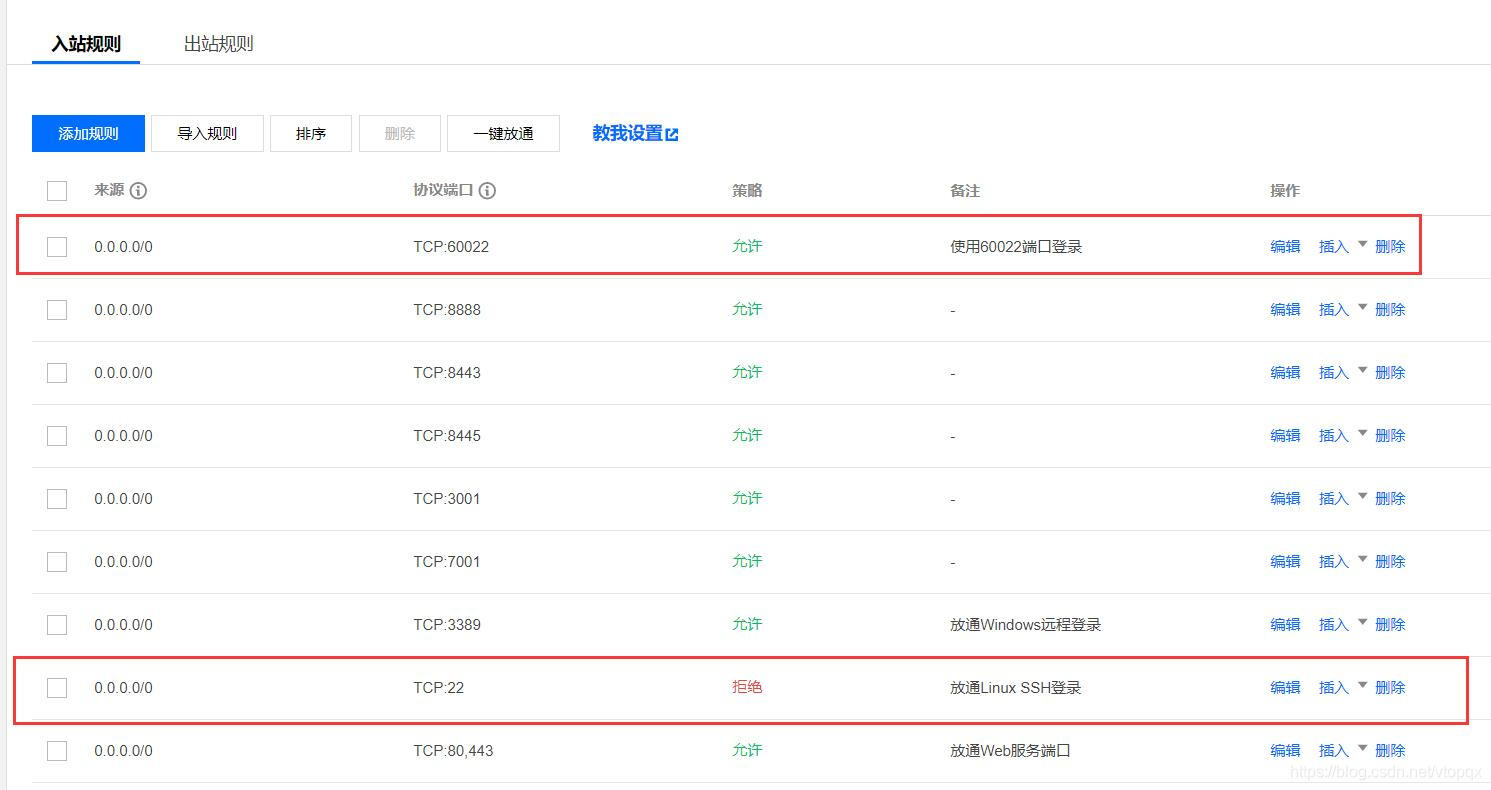
用命令`netstat -antup | grep sshd`查看一下
# 在进行OpsDevs时,有哪些配置要点?
# 部署一个在线应用
`sudo docker login --username=aliyun2088507371 registry.cn-hangzhou.aliyuncs.com`




{kind=link}