Java中事务的理解
今天在做固资系统时遇到一个问题,就是无论如何事务提交都不生效,于是决定实施实验,探究下背后的原理。本文主要分为三部分,第一部分讲解事务机制生效的原理。第二部分讲为了使事务生效,我都尝试了哪些方法,并解释每种尝试有效或无效的原因。第三部分讲解一下为什么我们需要事务机制。
一、事务机制生效的原理
事务机制生效是建立在数据库的事务基础上的。也就是单纯的 java 语言层面的完成不了事务控制的。所以,要了解清楚事务执行的原理就要对于 mysql 的事务机制有了解。我们以 mysql 举例。开始讲具体事务隔离级别之前,我们先把存在的问题给予说明。
事务并发可能出现的问题
| 引发问题 | 现象 | 可能什么状况下发生 |
|---|---|---|
| 脏读(Dirty Read) | 一个事务读到了另一个未提交事务修改过的数据 | 读未提交事务隔离级别 |
| 不可重复读 | 一个事务只能读到另一个已经提交的事务修改过的数据,并且其他事务每对该数据进行一次修改并提交后,该事务都能查询得到最新值 | 读未提交事务隔离级别、读已提交事务隔离级别 |
| 幻读 | 一个事务先根据某种条件查询出一些记录,之后另一个事务又向表中插入了符合这些条件的记录,原先的事务按照该条件查询时,能把另一个事务插入的记录也读出来 | 读未提交事务隔离级别、读已提交事务隔离级别、可重复读事务隔离级别 |
mysql-中常见的事务隔离级别有几下四种">mysql 中常见的事务隔离级别有几下四种
1.读未提交
可避免脏读,会出现幻读,不可重复读 实现方式:就是不加锁的,相当于裸奔。多个事务同时盯上一个数据,然后各写各的,谁把谁覆盖不得而知,总之,谁写的快谁就会被覆盖,丢失信息(写的慢的后完成,结果得以保留)。任何事务对数据的修改都会第一时间暴露给其他事务,即使事务还没有提交。
2.读已提交
可以避免脏读,幻读,不可重复读仍不能避免 实现方式:读已提交是 Oracle 11g、PostgreSql 默认隔离级别,通常通过加锁的方式来防止并发写入(写写)。一个事物当在尝试更新对象时(写入),必须获得该对象的锁,同一时刻只能有一个事务特有该对象的锁,未获取锁的事务需要一直等待,直到持有锁的事务提交或终止。此方式相当于将并发的请求用加锁的方式串连起来,使得同一时刻只允许有一个事务进行写入,从而来避免事务竞争的情况。针对数据库系统多个事务并发读取(读读),并不会对资源加锁,在读已提交和快照隔离级别(即下面要要说的可重复读),写操作也不会阻塞读操作。
3.可重复读
可以避免脏读,和不可重复读,但是仍可能出现幻读;但是性能比较低 实现方式:可重复读是 mysql 默认的事务隔离级别,在多事务并发写入(写写)和多事务并发读取(读读)时,采用的是与读已提交相同的原理,即允许[读与读]并发而[写与写]互斥。在处理事务并发读写(读写),不同于读已提交,可重复读会保留操作资源的多个版本,并为每个事务记录更新数据时的事务 ID(事务 ID 在事务开始时通常由数据库系统分配,通常是单调递增的) 会带来的问题:丢失更新问题(Lost Update)。但可以用原子写或排它锁(FOR UPDATE)方式来避免。
4.串行化
各种问题,脏读,幻读,不可重复读都可以避免,通过加锁实现(读锁和写锁) 实现方式:通常采用两阶段锁(two-phase locking,2PL)的方式来实现。允许事务并发读取,即读与写互不干扰。但是如果对某一对象进入写入时,需要等待该对象上的所有读与写完成后,才能写入。如果要对写入的对象进行读取时,要等待写入事务提交或终止后,才能读取。 会带来的问题:因为两阶段锁做写入操作时,会对资源进行加锁,并且写操作还会阻塞读操作。所以串行化性能十分低下。还会产生写锁和写放大等现象,因为生产环境中一个写服务变慢时,可能会拖累整个应用的吞吐量,并逐步扩大,最终导致整个系统不可用。
二、探索过程
1.常规操作(最终结果事务不生效)
因为我完成的是系统与外部系统对接,同时,内部会写主表、关联表、日志三张表。外部类中的方法,主要是向第三方推送,所以,我把它单独封在了 infrastrucate 的 message 层里,返回值是 void,由于网络请求异常,系统服务运行异常等都可以被捕获并抛出异常,这是不需要处理的部分。当请求码异常的时候,直接返回到请求产生的层,再根据判断请求码从而 throw new Exception(),这个异常就可以在外部的 try catch 的 catch 部分被捕获到,用 IDE 来 debug 代码,执行流程所说一致。所以直接执行,但是很不幸,最终在请求第三方状态码异常的情形下,数据库层面依然写表成功,事务执行失败。看控制台的运行代码,能够看到“No transaction session”的字样,用这个搜索谷歌表明没有事务所以 mysql 并没有开启相应的事务操作。出现这种现象有两种可能,一种是事务没有开启,另外一种是开启了事务,但你哪个环节的代码把注解@Transaction 隐式对异常的捕获给吸收掉了。经过不断的尝试和调整,发现是@Transaction 注解自带了对 try catch 异常的捕获,倘若你再包一层 try catch 就会导致你自定义的 try catch 把异常捕获取,而@Transaction 注解隐式捕获异常的方式就没异常捕获了,所以,也就没法达到回滚的目的。
2.特定方法单独进行声明(最终结果事务生效)
就像其它语言中使用的方式一样,就是在方法内部,自己来进行 try catch 进行异常捕获,开启事务,如果出现异常就回滚。看下面一段示例代码:
Transaction tx=session.beginTransaction();
try {
... //你自己的业务逻辑
tx.commit();
} catch (Exception e) {
... //捕获异常处理机制
tx.rollback();//事務回滾
}
3.配合注解及自定义异常处理逻辑(最终结果事务生效)
我代码中最终使用的是这种方式,在方法顶部正常声明@Transaction,但是由于我是调用了相应 service 下的方法进行推送消息的动作,该方法内部如果我直接抛出异常,但却不想在该方法内部进行异常捕获处理,我可以直接给该方法加上 throws Exception,这样在调用方法的部分就可以直接处理异常。此时就面临着问题,如果你在有@Transaction 注解的方法内又使用了 try catch,就会导致@Transaction 捕获异常失败,怎么解决呢?
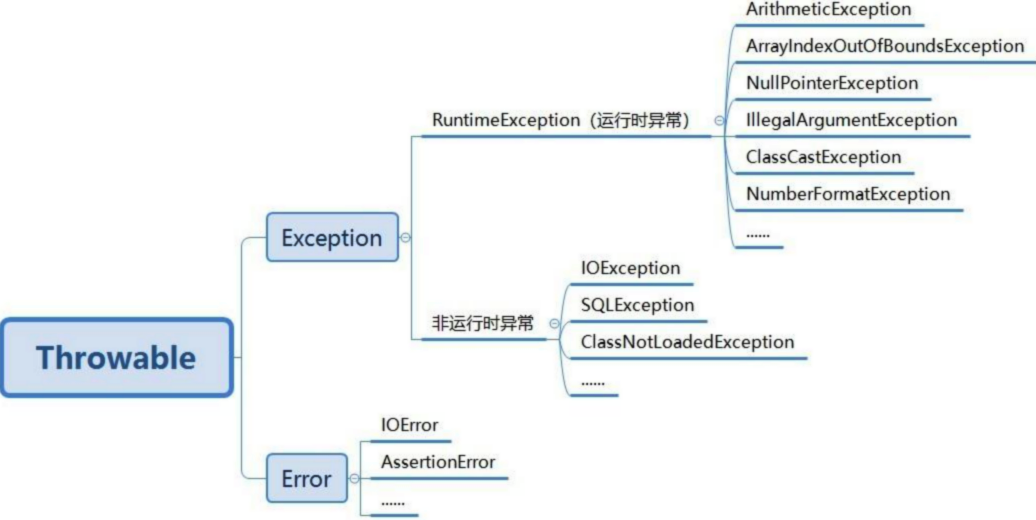
java中异常分类
通过不断比较发现,在 java springboot 系统中异常都是继承自 Throwable,Error 及 Exception 都是继承自该 Throwable,而 Exception 一支中又分为 checked 和 unchecked 两类,对于 unchecked 类的异常,系统会自己捕获并返回,且系统一定会终止执行,此类异常通常都是语言层面的错误,比如说数组下标指针越位,比如说值类型错误,它们又有个归纳的上级异常类,就是 RuntimeException,所以,我的解决方法就是自己捕获异常,同时在 catch 中抛出异常的类另是 RuntimeException,这样事务就可以正常执行。这里做一下扩展,因为 Error 类也是 RuntimeException 这种 unchecked 类异常的子类,可以把 RuntimeException 改成 throw new Error("")的结构或 Error 的子类。
这种方式比较优雅,建议使用。
4.指定为手动触发(最终结果事务生效)
在 try catch 的 catch 部分指定手动触发:
TransactionAspectSupport.currentTransactionStatus().setRollbackOnly()
但是据观察,这样会导致自增 id 不断累加占位不插库,同时,如果有 mysql 提交,会把所有累加的占位提交全部触发执行,没有经过后续的完全测试,但是不太建议用这种方式。
5.将 checked 类异常用 rollbackFor 关键字指定在@Transaction 注解中(最终结果事务生效)
@Transactional(rollbackFor={MyException.class, AnotherException.class})
public SomeResult doSomething(){
...
}
这种方式比较优雅,建议使用。
为什么需要事务机制
这个问题其实应该一开始就抛出来。但是最后来说,是觉得前面概念这些可能初次接触,觉得云里雾里的,你心中可能从有点糊涂那刻起就升出疑团,费了这么大劲,搞出这么多事务隔离级别,到底是为了解决啥问题,所以在这部分公布答案,如果做过开发,并且做的跟交易密切相关的业务,就更能理解我下面所说的问题。
- 数据库在写入一半数据时崩溃
- 订单数据保存一半后网络链接中断
- 多个客户端可能同时写入数据库
- 多个客户端间条件竞争可能会扰乱整个应用等
正因为有如上这些很让人“痛”的问题存在,所以数据库的事务隔离级别应运而生。
好了,今天关于事务隔离级别的文章至此结束,希望你能有所收获。




{kind=link}