4天23000流量,成功开通中视频计划!视频剪辑挣钱不寒碜!附送puppeteer技术清单,助力全自动化视频剪辑!
你心理一定有疑惑,python爬虫怎样赚外快?说说我本人。 自己在量产短视频平台如抖音、快手、bilibili、youtube等平台的视频,与设想一致,由于独特的剪辑手法,所以视频在这些平台都很受欢迎,自己的西瓜视频也参与了中视频计划,用了不到四天的时间就突破了17000的播放量,进入了审核状态。首先让大家一起来欣赏一下这番操作下来的战果,基本用时5天达到初始账号超过了96%的同类创作者(这句是抖音创作者平台的统计数据)。
微信视频号数据,大概发了7天,30多个视频吧,周末的时候给推了流,数据就出来了
微信视频号数据,大概发了7天,30多个视频吧,周末的时候给推了流,数据就出来了
微信视频号给推流后的播放量,之前一直500左右
抖音同样,大概发了7天,30多个视频吧,周末的时候给推了流,之前一直跑500的初始流量左右,然后就爆到1000~2000区间了
抖音同样,大概发了7天,30多个视频吧,周末的时候给推了流,之前一直跑500的初始流量左右,然后就爆到1000~2000区间了
西瓜视频,2023年2月23号开始发,前面3天一天10~20个,后面几天一天20个,就过了中视频计划17000的门槛
2023年2月23号开始算,到27号下午收到满足17000审核门槛通知,90多个视频,用时4天多一点

这是西瓜视频后台对我的视频的数据统计,可见效果是相当不错的
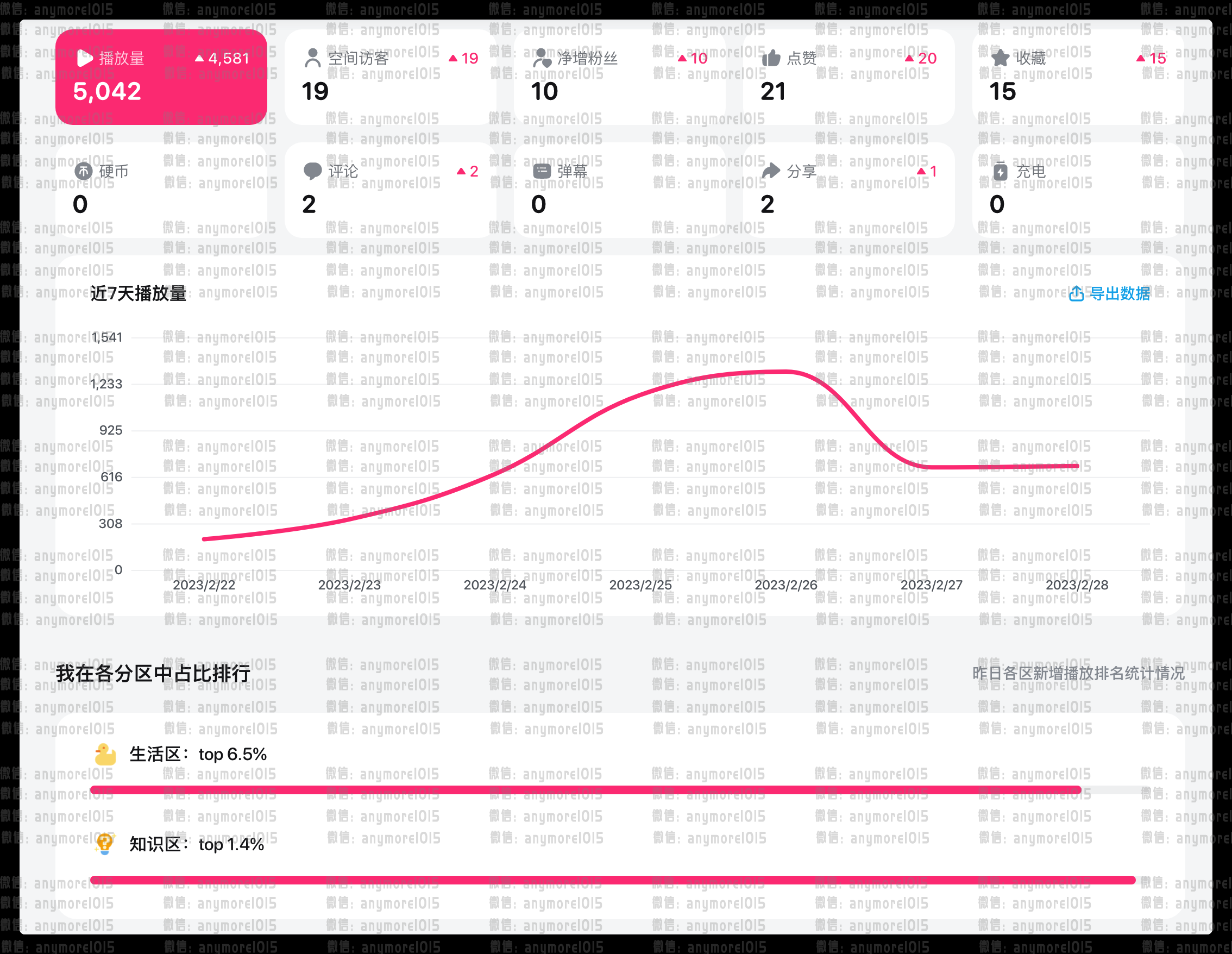
bilibili的后台数据
但同时也出现了一个问题,也就是类似于抖音这种平台上的机制,就是给账号打标签。看了很多抖音平台的操作经验分享,发现如果5s完播率能超过60%以上,播放率如果能超过10%,当然越高越好了,加上赞播比相对较高,其实就可以投抖+快速起号了,而我有几个视频,后台的统计数据就是这样,因此我就有了投抖加起号的想法。

举例我抖音后台某个视频的数据概况
而想投好抖加就要有相似达人和对标账号,由于相似达人这个数据,如果粉丝量没有到达1000,所以巨量数据无法开通,所以无论是抖音手机端还是pc端,现在都没有一个工具,可以让我有效寻找相似达人作为参考,这种处境之下,不得不做的一件事就是自己写个工具,来抓取我关注领域的自媒体账号,从中选出来粉丝量目前体量在10~30w之间,同时涨粉发生在最近一二周以内的。可想而知,如果这个工作要手动来做,那是何其庞大体量的一件事,恰好puppeteer的用武之地就来了,同时也是一个契机,让我对puppeteer进一步熟悉,也为自己开发称手的macos系统上运行的运营GUI工具有所助益。
提一嘴,关于开发跨平台客户端GUI工具,我其实心里盘算已久了,但是一直迟迟未动手。因为虽然自己也用javascript及基于它的框架如vue、react、avalon、jquery等写过不只一个项目了,熟悉程度还是有的,但是毕竟自己还是后端语言浸淫颇深,完全用javascript全栈的思路来搞一个带gui界面强大的运营工具,内心多少还是有点抵触的,毕竟它与开发一个带界面的web服务还不同。自己最初的设想是用python系的GUI架包pyqt5啥的来做这件事,但是进一步研究,发现如果基于node系来做GUI工具,明显的几点好处有:
-
- 可以加快对于javascript全栈项目的理解
毕竟今年自己要上的几个系统,都不可能缺少前端界面的,如果对于现在流行的前端框架不熟悉,那做界面的东西都很棘手,恰好借着这个机会,更深入理解一下javascript的生态。
-
- node系里有谷歌家基于自己chrome浏览器的爬虫及自动化测试工具puppeteer,这个就太强了,几乎是对其它或自动化或爬虫工具降维打击式的存在
这些好处的凸显,一方面得益于谷歌技术领域一以惯之的前沿及稳定及财大气粗,另一方面就举个例子来理解比较形象了:你把一个依赖当工具,开发称手利器,此时这个依赖于你而言是黑盒。和这个依赖的本家自己攒出人手,基于自己家的东西开发与你称手利器所在领域相抗衡的工具,你觉得谁会赢?况且这个本家还是google,我猜大概也是这个原因,所以之前很多基于python语言开发的浏览器爬虫工具,像phantomJs、selenium出镜率越来越低了。
-
- 基于node体系内强大的扩展 可以直接把web封出GUI,再编译成跨平台运行的版本,这对于一些付费工具的发行,可能效率上会有巨大的提升
还要说回我的意图,其实从我这几次分享文章的一些思路和经验,你应该也看得出,我是极其重视效率的。如果没有这个出发点,我可能也人肉一个一个来剪视频了,但那样,我是全然没办法在2天之内就生成出1000多条5分钟长度左右视频的,显而易见,人力在工具面前是何其渺小。而我终极的目标,肯定是想,把现在在我电脑上运行的一些脚本工具进行商业化。或者做成web版本,或者做成GUI版本,就算不以GUI发行,但是GUI的深入学习过程,举例,比如说像puppeteer这种自动化工具、jest这种单元测试工具,结合到一块使用,再配合上一些键盘按键模拟工具,如Robotjs等,像现在手动上传视频的一些操作,如果对这工具再近一步熟悉以后,就可以用工具来替代工作,这样就大大节省了人力!用省下来的时候,我出去玩、去刷剧、看风景它不香吗?虽然这个探索过程可能要稍微花一些精力,但是一旦排坑成功,基本就一劳永逸了,所以这个时间还是很值得花的。
上面这一席话,其实也算是给有缘看到的网友拓展一下思路。说回今天的正题,关于jest单元测试工具的使用,其实主要还是指它配套的一些生态内的工具,再结合着puppeteer的优点,可谓强强联合,有些事情可以做的更扎实、更艺术。愈发要表扬puppeteer了,之前由于采集国外某个站点,当时通过python的接口请求形式,配以executeJs这个扩展包,费了好大力气,追页面参数的链路,把该站点自己想要的文本内容都抓取了回来,当时也是有自动化测试工具、浏览器端爬虫工具思路涌上心头的,但是当时chromium这个chrome内核爬虫配套工具的版本问题搞的焦头烂额,后面实在无心情投入时间了,当时对于浏览器爬虫工具有了一定抵触情绪。后来呢,因为一个爬虫问题,得知有了谷歌推出的名为puppeteer这个工具,从此为我打开了一个新世界。也小试牛刀了几个项目,给自己站点填充数据。虽然相比于python系的爬虫生态,自己对它还略显生疏,但是面对一些需要登录,验证session的目标站点时候,puppeteer是真香!虽然效率相对低一些,但是电脑放那跑着也就无所谓了。
javascript语言的天然劣势网上的讨论就林林总总了,语言设计虽然没有golang之类的思想先进,有很多莫名其妙的槽点,但是毕竟前端领域无出其右,所以有些它的缺点你也要接受,况且es6内核升级以后,及typescript的横空出世,这些短板也在不断被弥补上,所以还是很值得投入时间在这一套栈体系上。
这里把自己在做抖音数据收集时候,一些问题的解决思路分享一下。
前者如果你用brew安装了node,再用npm或者yarn安装puppeteer时候,实际它是安装了工具内核及一个chrome浏览器的,如果你不想用它安装的浏览器(也确实没必要),可以使用系统自身的浏览器,这个时候就要判断一下系统,及指定chrome浏览器在你本地的安装位置,比如我的是mac,我是用下面方式指定的,然后把它作为浏览器的启动项:
#puppeteer安装命令
npm install -g puppeteer-core
const getDefaultOsPath = () => {
if (process.platform === 'win32') {
return 'C:\\Program Files (x86)\\Google\\Chrome\\Application\\chrome.exe'
} else {
return '/Applications/Google Chrome.app/Contents/MacOS/Google Chrome'
}
}
-
- 要以最小代价启动,如果以有界面方式来启动,默认会开一个tab,在这个tab之外再启一个来运行你的访问逻辑,可以用下面的方式,让它直接在默认的tab上执行访问逻辑
#这里global.__BROWSER__是全局对于浏览器的初始化
page = (await global.__BROWSER__.pages())[0]
-
- jest安装完毕之后,要初始化,初始化过程会有交互窗口,最终会生成jest.config.js文件,里面会默认有node引擎的版本,有覆盖测试数据目录,配置支持的文件扩展,针对于不同框架的预设集成配置等
#node引擎的版本
coverageProvider: "v8",
#覆盖测试数据目录,还可以指定测试报告输出地址
coverageDirectory: "coverage",
#针对于不同框架的预设集成配置,默认是bebel-jest,由于Babel对Typescript的支持是通过代码转换的方式实现的,而Jest运行时又不会对你的测试用例做类型检查,因此我建议用ts-jest
preset: 'ts-jest',
#配置支持的文件扩展
moduleFileExtensions: ['ts', 'tsx', 'js', 'jsx', 'json', 'node'],
#每次测试之后运行代码,或者环境变量
setupFilesAfterEnv
-
- jest、typescript安装完成之后,都要安装对应的包声明,都要做相应的初始化,在无论typescript的配置文件中,还是jest的配置文件中,甚至你还用一些包管理工具引入进来,它们配置文件都是各自为政的,可能相同的东西几个配置文件里都要copy一遍,但这又是没办法的事
#安装jest(这里可以自己指定版本)
#常规:npm i jest ts-jest @types/jest -D
#一个个安装:
npm i -D [email protected]
npm i -D [email protected]
npm i -D [email protected]
npm i -D @types/[email protected]
#初始化(上一步里那些配置项中的一些初始化阶段,交互完成就自动写到jest.config.js文件中了)
npx jest --init
#jsdom环境安装,jest28以上的版本,可能还要单独安装jsdom,但是当时翻了好多帖子,似乎有兼容性的问题,所以我安装的依然是27.x的版本
npm i jest-environment-jsdom eslint-plugin-jest eslint-import-resolver-typescript jest-canvas-mock -D
#28及以上需要自己安装jsdom
npm i jest-environment-jsdom eslint-plugin-jest eslint-import-resolver-typescript jest-canvas-mock -D
#也要对npx进行初始化,会在项目目录下生成tsconfig.json,npx原理是会自动查找当前依赖包中的可执行文件,如果找不到,会去PATH里找,如果再找不到会帮你安装,大大方便了node_modules目录下可执行文件等的调用难度,这个可以自己以后慢慢体会
npx tsc --init
-
- 想一次运行多个浏览器容器,可以用遍历的方式来实现,也可以用别人开发好的包,比如
puppeteer-cluster。浏览器如果每次都全新启动,势必带来资源的浪费,所以pc端使用的时候,可以把缓存之类的加载进来,可大大加快chrome的启动速度
- 想一次运行多个浏览器容器,可以用遍历的方式来实现,也可以用别人开发好的包,比如
# 使用puppeteer-cluster的demo
const { Cluster } = require('puppeteer-cluster');
(async () => {
const cluster = await Cluster.launch({
concurrency: Cluster.CONCURRENCY_CONTEXT,
maxConcurrency: 2,
});
await cluster.task(async ({ page, data: url }) => {
await page.goto(url);
const screen = await page.screenshot();
// Store screenshot, do something else
});
cluster.queue('http://www.google.com/');
cluster.queue('http://www.wikipedia.org/');
// many more pages
await cluster.idle();
await cluster.close();
})();
# 浏览器存储用户缓存等复用信息的目录,就包括你登录成功吐到客户端的cookies等
userDataDir: '/Users/guruyu/Library/Application Support/Google/Chrome/Default',
-
- 比较不幸的消息是,在研究这个的过程中,发现playwright可能是更好用的工具
各种帖子都看,所以又知道了现在也很火的,可以与puppeteer分庭抗礼甚至又超越趋势的playwright,这个的好处就是直接官方就支持了python操作,要相对于node系,我肯定是python更熟悉的,而python之前如果你不懂node相关,你用puppeteer只能用非官方版本,而非官方版本还是个async的版本,并且有各种奇奇怪怪的bug,所以我又在纠结了,要node技术栈坚持到底,还是继续用我更熟悉的python呢?
好了,今天的文章就分享到这里。结尾打个广告,有批量生产视频需求的胖友可以联系我,之前批次生产的都是6分钟左右的视频,进行了版本优化之后,现在随便什么长度的视频都可以量产,我自己最近又量产了一批15~60分钟长度的视频,也是为了契合一些中、长视频平台用户的诉求,内容也会陆续发到我的上述平台上,如果有兴趣也可以围观一下,希望小伙伴们多多支持,能帮转发一下就更感激不尽了!同时寻找一名技术合作伙伴,最好能够擅长前端技术栈,另外我在寻找的,其它类型的合作伙伴已经发在这里了,点击查看。




{kind=link}