详解java之JVM内存机制
jvm 如何做优化呢?
为什么要学习 jvm 优化呢?其实 jvm 优化不是对 java 系统优化提升性能最明显的方式。可以从很多侧面来对 java 虚拟机的性能进行优化。着手于哪几面呢?
什么是虚拟
在深入探究 java 虚拟机之前,让我们重学一下 Virtual Machine(VM,虚拟机)
一个虚拟机是真实计算机的虚拟代理。我们可以把虚拟机叫做访问机,把运行它的物理机叫做主机。
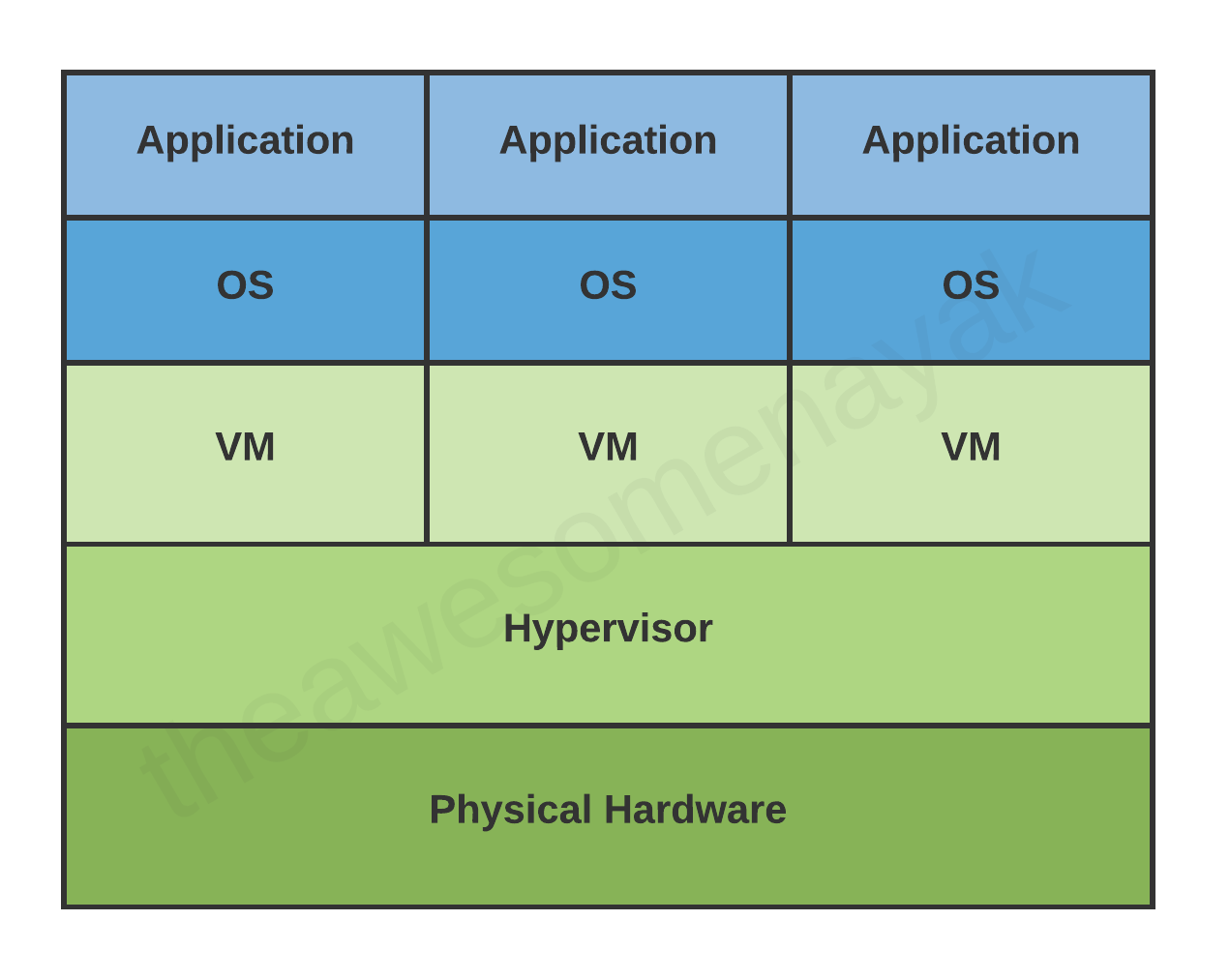 一个单独的物理机上可以运行多个虚拟机,每个虚拟机都有它操作系统和应用。这些虚拟机是彼此关联的。
一个单独的物理机上可以运行多个虚拟机,每个虚拟机都有它操作系统和应用。这些虚拟机是彼此关联的。
java-虚拟机">什么是 JAVA 虚拟机
像 C 和 C++这些编程语言,代码是首先被编译进指定平台的机器码,所以这些语言又被称为编译语言(compiled languages)。另一方面,像 JavaScript 和 Python,计算机直接执行指令而不需要编译它们。这些语言被称为解析型语言( interpreted languages)。 而 Java 使用两种技术的结合。Java 代码首先被编译成 byte code 型的.class 文件。.class 文件然后在相应平台被 java 虚拟机编译。相同的.class 文件可以任意平台和操作系统的任意版本的 JVM 运行。 与虚拟机概念一样,JVM 在主机上创建一个关联空间。无论机器的平台及操作系统,这开辟出来的空间都可以被用来执行 Java 程序。
java-虚拟机的结构">Java 虚拟机的结构
JVM 包含精确的三部分:
1.Class Loader
2.Runtime Memory/Data Area
3.Execute Engine
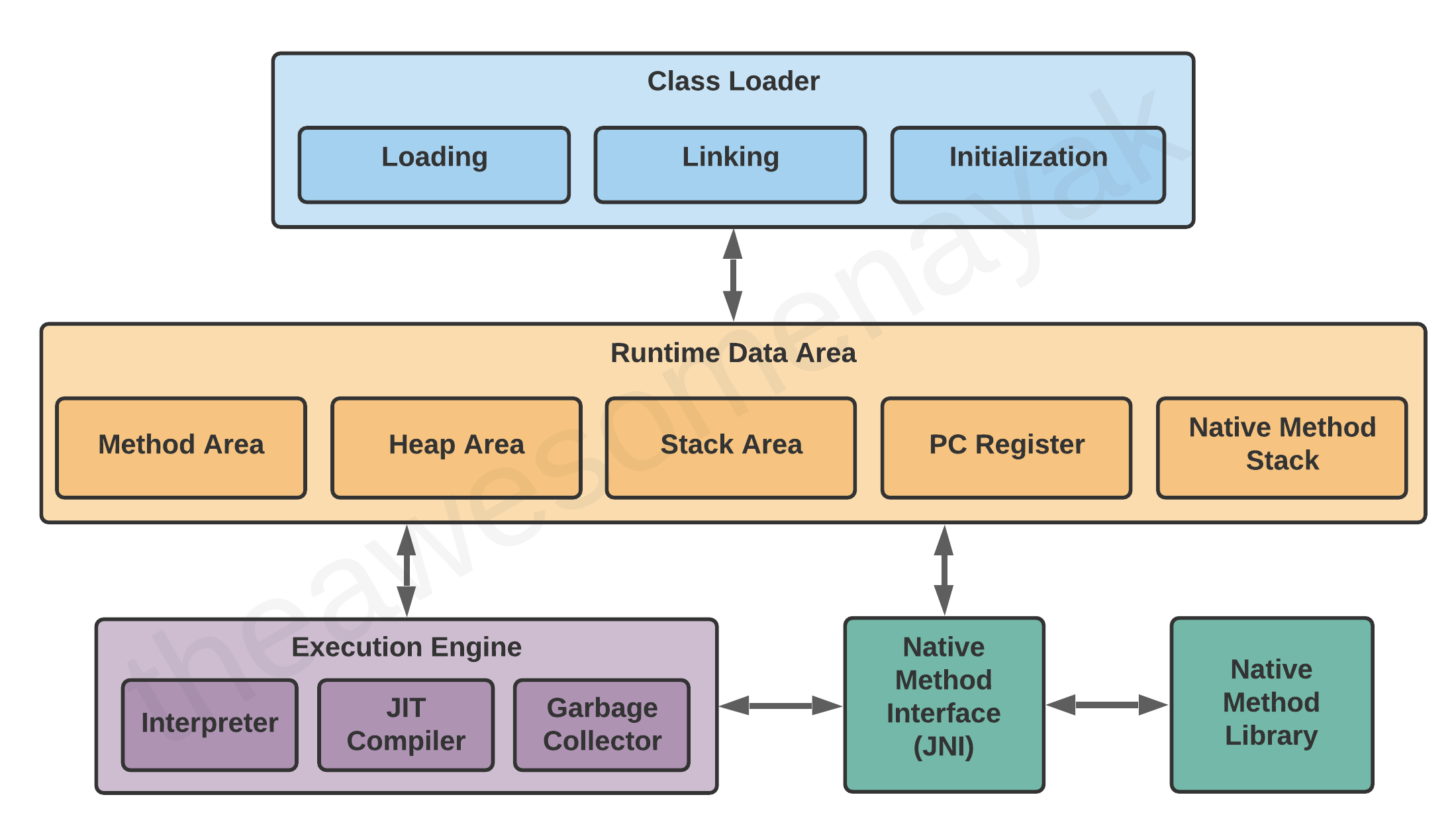 让我们来详细看看各部分。
让我们来详细看看各部分。
Class Loader
当你编译一个.java 源文件时,它会被编译成以.class 结尾的 byte code 文件。当你在程序中尝试使用这个类文件时,类文件就会把它加载进主内存上。
首个被加载进内存的是包含 main()方法的类。
类加载过程中有三个阶段:loading,linking,initialization
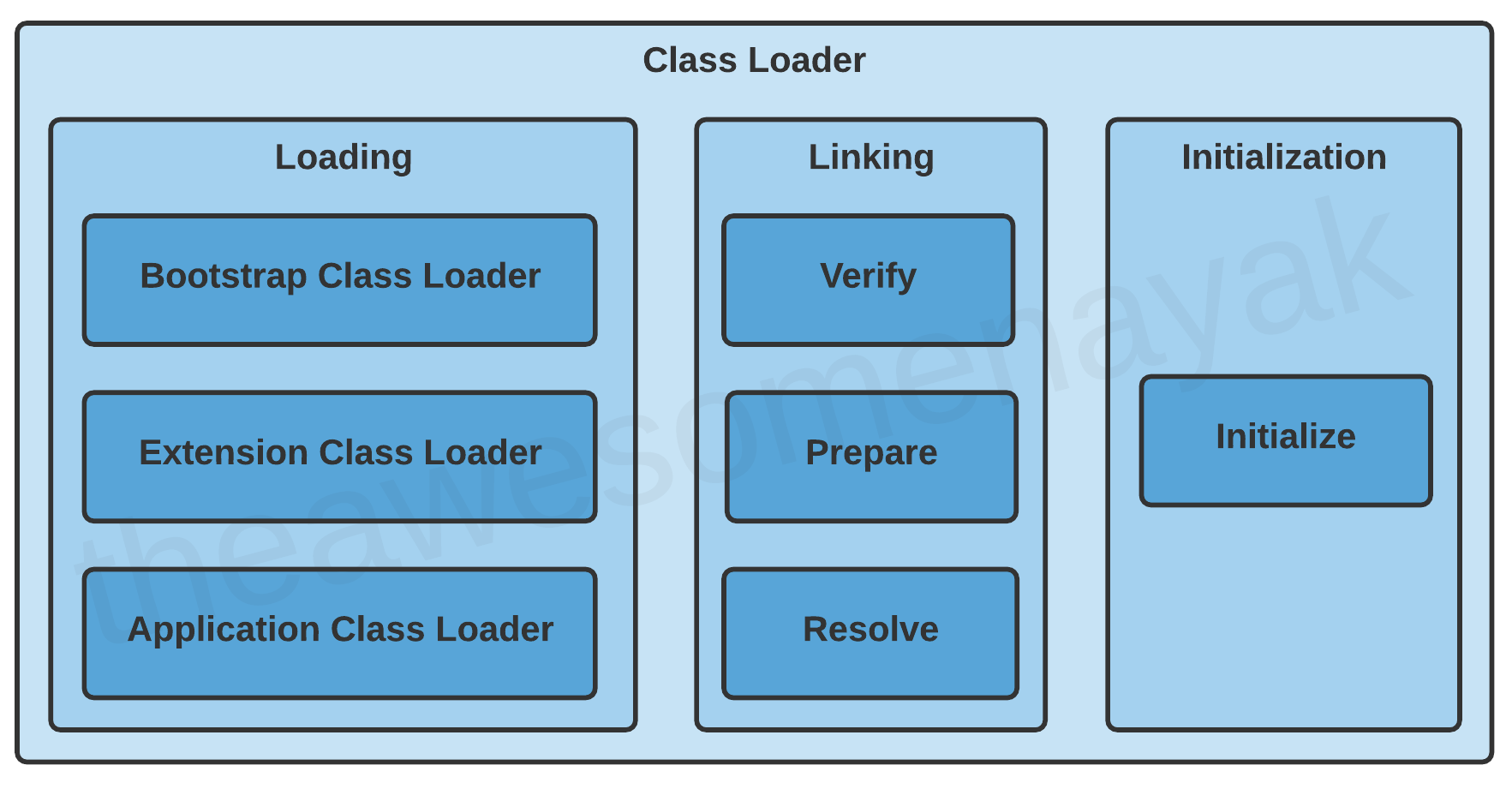
loading
loading 涉及使用具体名称的类或者接口的二进制表示(bytecode),并从中生成原始的类或接口。
在 Java 中有三个内建的 class loader: Bootstrap Class Loader-这是根加载类。它是 Extension Class Loader 的超类,同时加载标准的 Java packages,比如 java.lang,java.net,java.util,java.io 等等。这些 packages 是存在于 rt.jar 文件中,还有些核心库存在于$JAVA_HOME/jre/lib 目录下。
Extension Class Loader-这是 Bootstrap Class Loader 的子类,同时也是 Application Class Loader 的超类。会加载在$JAVA_HOME/jre/lib/ext 目录下 Java libraries 的扩展。
Application Class Loader-这是最终 class loader,同时也是 Extension Class Loader 的子类。会加载在 classpath 路径下相应的文件。默认情形下,classpath 被设置为应用的当前目录。classpath 也可以通过在命令行加-classpath 或是-cp 参数修改 classpath。
JVM 用 ClassLoader.loadClass()方法把类加载进内存。它会用全名加载 based class。
如果父类加载器找不到 class,它将工作委托给子类加载器。如果 last child class 也无法加载相应 class,就会抛出 NoClassDefFoundError 或 ClassNotFoundException。
Linking
类加载进内存后,就进入 linking 阶段。Linking 意味将一个类或者接口及程序的不同元素及依赖连接到一起。
Linking 包含以下步骤: Verification:这个阶段通过一组约定或者规则对于.class 文件的正确性进行检查。如果校验失败,就会抛出VerifyException。 举例,如果 code 已经被 Java11 编译,但是却让它在 Java8 的平台上运行,则 Verification 阶段则会失败。
Preparation:在此阶段,JVM 为一个类或接口的静态字段开辟内存,并用默认值初始化它们。这个可以类比一个 javascript 中的变量声明和变量赋值阶段,不是声明了变量直接就开辟了空间并把值初始进去,而是先用默认值初始化,再进行赋值,完成变量初始化的过程,后面 Intialization 部分会讲到,请关注。 举例:假如你在相应类中声明了如下变量:
private static final boolean enabled = true;
在 Preparation 阶段,JVM 给变量 enabled 开辟内存空间,同时对它设置默认布尔初始值,注意此时值是 false。
Resolution:在此阶段,符号引用被存在于运行常量池中的直接引用替代。 举例:在此阶段,如果有对其它类的引用或是在其它类中存在常量,最终都会被实际引用替代。
Intialization
Intialization 涵盖了执行类或者接口的初始化方法(被称为<clinit>)。包含了调有类的构造方法,执行静态块,赋值所有静态变量。这是 class loading 的最后一个阶段。 举例:回看我们前面声明过的代码:
private static final boolean enabled = true;
在 Preparation 阶段,enabled 被设置为默认值 false。在 Intialization 阶段,变量被赋值为 true。
注意:JVM 是多线程的。会发生多线程在同一时间都试图去对同一个类做初始化的情况。这会导致并发连接问题。你需要在多线程环境下,处理好线程安全以使程序正常运行。
Runtime Data Area
在 Runtime Data Area 里有五个组件:
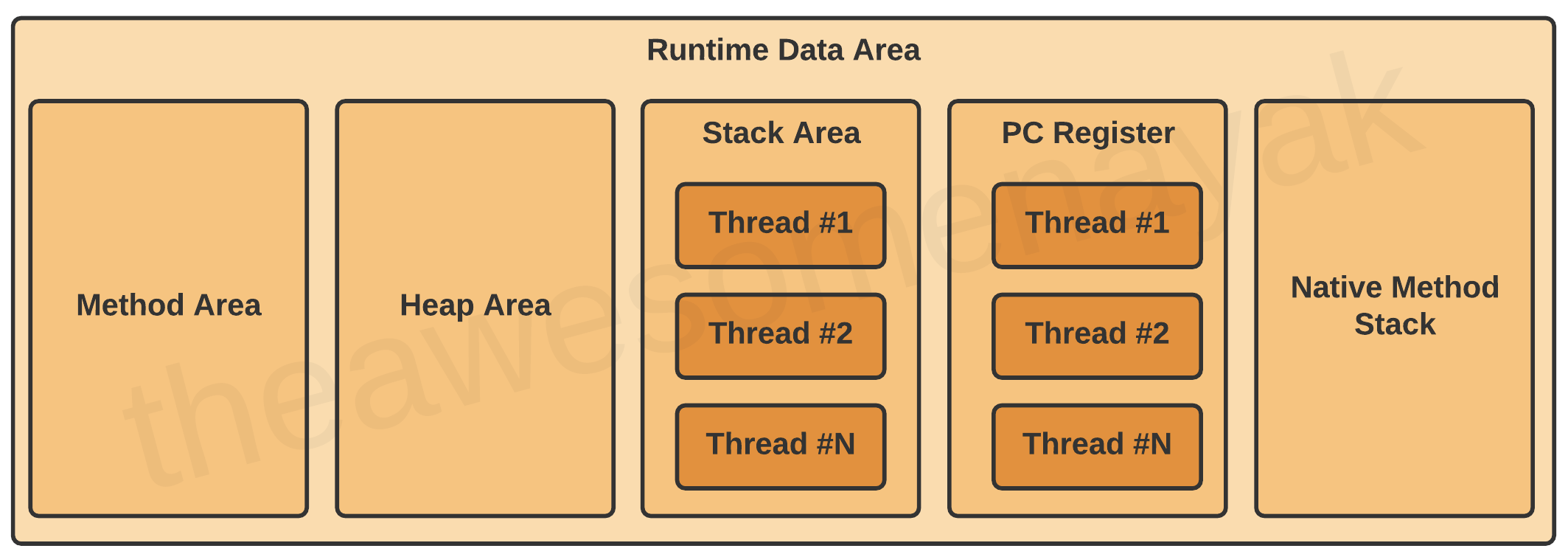
我们来分别看下每个部分。
Method Area
所有类级别的数据,比如 run-time 常量池,字段,方法数据,方法和构造方法的代码都存储在这里。
如果在方法区的内存对于程序启动是不足的,JVM 就会抛出 OutOfMemoryError。 举例,假设你定义了如下的类:
public class Employee{
private String name;
private int age;
public Employee(String name,int age){
this.name = name;
this.age = age;
}
}
在示例代码中,字段级别数据如 name 和 age,还有构造方法的详情被加载进方法区。
方法区是在虚拟机启动的时候被创建的,每个 JVM 只有一个方法区。
Heap Area
所有的对象及它们响应的实例变量都存储在这。这是为所有类实例和数组分配内存的运行时数据区域。
举例预想你声明了如下实例:
Employee employee = new Employee();
在这段代码实例里,一个 Employee 实例被创建,同时被加载进 heap area。
heap 是在虚拟朵启动时创建的,每个 JVM 只有一个 heap area。
注意:由于 Method 和 Heap Area 为多个线程共享相同的内存,所以存储在此区域的数据是非线程安全的。
Stack Area
无论何时当一个线程在 JVM 中被创建,一个拆分开的 runtime stack 也同时被创建。所有的本地变量,方法调用,特殊结果都被存储在 stack area。
如果在线程中需要处理所需要空间比可用栈空间更大,JVM 就会抛出 StackOverflowError。
对于每次方法调用,在栈内存中所创建的 entry 被叫做 Stack Frame。当方法调用完毕以后,Stack Frame 也会被销毁。
Stack Frame 被切分成三个子部分: Local Variables-每个 frame 包含一个变量数组,被称为 local variables。所有的 local variables 及其值都存储在这里。数组的长度在 compile-time 被确定。 Operand Stack-每个 frame 包含一个 last-in-first-out(LIFO)栈,被称为_operand stack_。其扮演着一个 runtime workspace 的角色去执行任意中间操作。stack 的最大深度是在 compile-time 时被确定。 Frame Data-所有方法对应的符号都存储在这里。在抛异常的场景中,catch block 相关的信息也被存储在这里。
举例有如下一段代码:
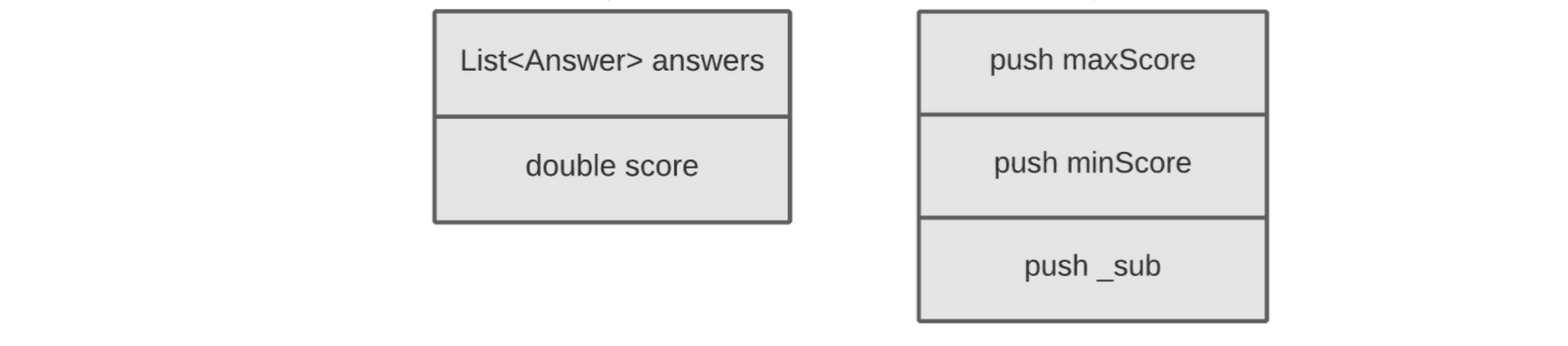
double calculateNormalisedScore(List<Answer> answers){
double score = getScore(answers);
return normalizedScore(score);
}
double normalizedScore(double score){
return (score - minScore) / (maxScore - minScore);
}
这段示例代码里,变量如 answers 和 score 被放置在 Local Varaibles 数组中。Operand Stack 中包含变量及做加减乘除运算的操作符。
注意:由于 Stack Area 是不共享的,它是继承性线程安全的。
Program Counter(PC) Register
JVM 支持同时使用多个线程。每个线程有它自己的 PC Register,用来持有当前正在执行的 JVM 指令的地址,指令被执行后,PC Register 就被下个指令更新。
Native Method Stacks
JVM 包含支持_native_方法的栈。这些方法是用 Java 以外的语言如 C 和 C++写的。对于每个新线程,一个拆分到的_native method stack_也就被同时分配了。
Execute Engine
当 bytecode 被加载进主内存,细节在_runtime data area_就可用了,下一步就是运行程序。_Execution Engine_通过在每个类中代码来做这件事。
然而,在执行程序之前,bytecode 需要被转译成机器指令。JVM 可以用一个解析器或者一个_JIT_编译器作为执行引擎。
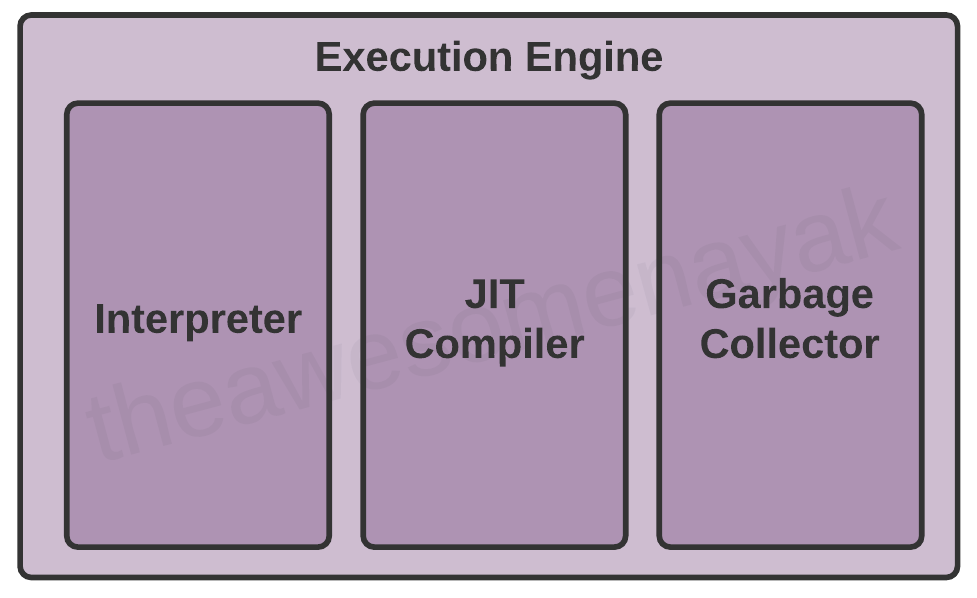
Interpreter
解析器一行一行的读取和执行 bytecode 指令。由于是一行一行执行,解析器会相对慢一些。
另一个解析器的劣势是当一个方法被调用多次,每次都需要一个新的解析器。
jit-compiler">JIT Compiler
_JIT Compiler_克服了解析器的劣势。_Execution Engine_首先用解析器去执行 bytecode,但当它发现有重复代码时,它就会使用 JIT 编译器。
JIT Compiler_之后编译整个 bytecode,同时把它转成_native machine code。_native machine code_被直接用于重复方法调用,还可以改善系统的性能。
JIT Compiler_由几个几部分组成: 1.Intermedia Code Generator-生成中间层代码 2.Code Optimizer-优化中间代码来提高其性能 3.Target Code Generator-把中间代码转成_native machine code 4.Profiler-发现 hotspots(可重复执行的代码)
为了更好理解_interpreter_和_JIT Compiler_的差别,我们来看下面一段代码:
int sum = 10;
for(int i=0;i<=10;i++>){
sum += 1;
}
System.out.println(sum);
解析器在循环的每次迭代中都要从内存中取到 sum 的值,然后把 i 的值累加上去,再把结果写回内存。这是个非常昂贵的操作,因为每次循环都要访问内存
然而,_JIT Compiler_能够识别代码中有 HotSpot,并对它执行优化。它会在线程的_PC register_上存储一个 sum 的本地副本,同时在循环中持续把 i 的值做累加。当循环完成以后,它就会把 sum 的值写回到内存。
注意:_JIT Compiler_编译代码比_interpreter_的一行行解析代码花更多的时间。如果你打算只执行程序一次,使用解析器是更好的选择。
Garbage Collector
_Garbage Collector(GC)_从_heap area_收集和移除未引用的对象。它是通过销毁已用内存,使其在运行时自动重生成未使用内存的过程。
_Garbage Collection_使 Java 内存高效,因为它从_heap memory_中移除未引用的对象,同时为新对象释放空间。它包含两个阶段: 1.Mark-在这一步,_GC_识别内存中的未使用对象 2.Sweep-在这一步,_GC_移除前一阶段识别出的对象
_Garbage Collections_是由 JVM 每隔一段时间自动完成的,同时不需要单独处理。它也可以通过调用*System.gc()*触发,但是执行是无法保证的。
JVM 包含 3 种不同类型的_garbage collectors_: 1.Serial GC-这是_GC_最简单的实现,设计用于在单线程环境上运行小应用。它使用一个单线程做垃圾处理。当它运行时,会在整个应用暂停时导致“stop the world”事件。JVM 使用-XX:+UseSerialGC 参数做_Serial Garbage Collector_。 2.Parallel GC-在 JVM 中这是 GC 默认应用,同时也被称为_Throughput Collector_。它使用多线程来做_garbage collection_,但是运行时仍然会暂停应用。JVM 使用-XX:+UseParalleGC 参数做_Paralle Garbage Collector_。 3.Garbage First(G1)GC-G1GC 设计用于有更大的_heap size_可用的多线程应用(超过 4GB)。它把 heap 划分成一系列 size 相同的区域,同时使用多线程扫描它们。G1GC 标识垃圾最多的区域,就首先对该区域执行垃圾收集。JVM 使用-XX:+UseG1GC 参数做 G1 Garbage Collector。 注意:这里有另外一种类型的垃圾收集被叫做_Concurrent Mark Sweep(CMS) GC_,然而,从 Java9 开始已经被反对使用了,同时在 Java 14 中被完全移除并全力 G1GC
java-native-interfacejni">Java Native Interface(JNI)
有时也有必要使用 native(non-java) code(举例:C/C++)。这可能是在我们需要与硬件交互的情况下,或者为了克服 Java 中的内存管理和性能限制。Java 通过 Java 本地接口(JNI)支持本地代码的执行。
JNI 起到了一个支持其它语言如 C/C++的 packages 许可桥梁的作用。这在你需要写完全不被 Java 支持的代码时是尤其有益。比如一些平台的一些特色只能用 C 语言来写。
你可以使用_native_关键词描述提供给本地库的方法应用。你也需要引入 System.loadLibrary()把共享库加载进内存,使其函数可以在 Java 中使用。
Native Method Libraries
_Native Method Libraries_是用其它语言,如 C,C++和汇编语言写的库集合。这些库通常以._dll_或者.so 后缀结尾的文件。这些库可以通过 JNI 来加载。
jvm-errors">Common JVM Errors
- ClassNotFoundException-通常发生在_Class Loader_试图使用_Class.forName_加载类时。
- NoClassDefFoundError-通常当编译器成功编译类时,但_Class Loader_无法在运行时定位类文件。
- OutOfMemoryError-JVM 无法定位对象,因为超内存了,也没有更多内存来做垃圾回收了。
- StackOverflowError-如果 JVM 在处理线程时创建新的堆栈帧时耗尽空间,就会发生这种情况。
总结
本文我们讨论_Java Virtual Machine_的结构和它们多样的组件。通常我们不会深入挖掘 JVM 的内部机制或者当代码运行时它是如何工作的。
当运行出错时,我们需要调整 JVM 或者修复内存泄漏,我们需要尝试搞懂它的内部机制。
对于中高级的后端开发人员,这也是非常流行的面试问题。深入理解 JVM 的运行机制会帮助你写出更好的代码,避免栈相关的陷阱及内存错误。




{kind=link}