爬虫系统化课程kubernetes插件开发的六大方向(上)
kubernetes 已经成为云原生的行业标准,现在几乎所有行业所有公司的所有业务都在基于云进行部署,拓展。但是很多咨询学员其实对于云原生并不太感冒,觉得挺没技术含量的,yml 文件或者 yaml 文件相较于市面上存在的其它语言,它属于声明式的,不需要太多逻辑,就是一个通过不断使用就可以熟练的过程,纯记忆的东西,毫无艺术可言,掌握这些东西,并不会对自己的开发思维和编码能力带来影响。
这种说法,不能说不对,如果单纯从 kubernetes 的 yaml 文件构成上看,的确是这种情况。但是有一个事实却不能忽略,就是云原生解决的是应用服务上云的问题,那你回忆一下,如果你曾经自己部署过线上应用,大概流程是什么样的?你其实要考虑的问题有很多,你要对相应的业务进行技术选型,用哪种语言,是自己重复造轮子,还是用开源框架。
这里举个公司的例子,我刚来小米的时候,业务绝大部分其实已经上云了,也就是你作为程序员,你不需要管运维层面的事情,这是大公司里很流程化的东西,就是各司其职,自己管自己的一亩三分地。但是如果你天天写业务代码,你会觉得你自己能力有很多增长吗?显然是不会的,所以如果有机会能让你参与到一些更底层的标准和规划的制订层面的工作,你会有这方面的兴趣吗?显然每个人诉求不一样,而我就对这方面非常有兴趣,于是一个 out-of-tree 的 CSI 扩展,实现小米商城评论区存储的事情就落到我身上,之前在乐玩,对于 golang 已经比较熟练了,k8s 部署实践经验也比较丰富,我想这也是这个能让我来做的原因。区别还是有的,之前做的都是属于对于 k8s 文档中语法的熟悉程度的问题,就是你见的多了,写的多了,文档查的多了,有些细节你都能照顾到,头脑里再有一些集群部署、有一些架构的思维、有一些网络分层知识储备的东西就可以做。但是基于 k8s 做中间件开发还是不太一样的,因为不但你要对于 k8s 关于 CSI 这部分的原有存储逻辑你要理解,还要对于已经封装的接口和函数脉络有清晰的认识,这样你才知道从哪里下手做扩展。这么说有两个原因,第一个原因是之前的插件开发模式,你确实要对这些东西都有所了解,有很大的灵活性,灵活性高有好处,就是足够灵活,但是也有坏处,就是太灵活,实现方式可能对多方都有所影响,如果你不能了解全貌,很多潜在的问题你可能都没察觉,一旦暴露,特别已经线上部署,恐怕会造成很多不可预料的结果。而现在 out-of-tree 的好处就是,它类似于 hook 的方式,就是有哪些钩子,你只要在相应钩点上做扩展,该钩点存在的作用文档已经说清楚了,这样扩展的东西,对于原系统的稳定性影响限定在很小的范围内,即使出现问题也很容易排查和优化。所以,如果你一直做业务开发,如果有这样的机会,也不妨抓住这样的机会,主动锻炼自己。
我自己部署过很多个网站,从远古时代的 php 系的 wordpress 到后来的 discuz,到 yii 框架我都亲自捣鼓,完成了它们的线上部署过程。到后来玩的 python 比较多,要部署 django 应用到线上,同时要支持 elasticsearch 的扩展功能,再到后面的 java 应用的部署,springboot 那一套线上的部分,再到后来的 golang 的线上应用 gin-vue-admin 等基于 gin 和 gorm 的应用的线上部署,还有伴随职业生涯以来的,从 html+css+jquery 的常规界面,到后来的 vue,react 前后端应用分离前端应用的部署,这些东西缕下来,发现真是个挺浪费时间,又感觉其实都没什么实质技术能力成长的经历。比如说 python2 的时候,编码是个大问题,这个编码可能导致各种莫名的报错,所以你就要一个个查 stackoverflow 来寻找答案,并且又处于 2 和 3 的过渡时候,所以很多兼容方案,包的使用,你就不得不厌其烦的网上找兼容解决方案,然后根据指示一遍一遍尝试解决方案,运行脚本,看问题能不能解决,这些时间你觉得花的值吗?在我看来这些是不值的,这过程中你可能对对编码有一些深入的了解,但是编码在编程体系里面,它是一小块的内容,如果你作为一个智力正常的青年,这些东西,你去读官方文档,花一天时间沉浸式的阅读,我觉得你一定能掌握 ,但是就因为程序类型的千千万,所以,在解决兼容性的编码问题上我浪费了很多时间,却收益平平。还有大家吐槽最多,也最爱举例子的玩笑场景,本地跑的代码正常,提交测试环境,代码就各种抛异常,你还兴冲冲的把测试喊过来给她演示,并言之凿凿的阐述自己是不可能犯错的,本地跑的的确正常,但是测试环境它就不对,你怎么办,你还不是得 debug 解决测试环境的问题。上到正式环增,同样的情况再来一遍,就问你怎么办,你还不是一样没脾气,照样想方设法解决这些问题。所以环境的不一致性导致出现奇奇怪怪的问题,运维之所以在当时从业者数量庞大,保障线上低故障率是重中之重,所以我打时觉得运维一个个闲哈哈拿到手的工资甚至比我们都高的抱怨显然也不够公允。而 docker 的出现,kubernetes 的出现,的确从根本上解决了这个问题,当然,这也促使了运维的转型,如果你现在还是只会一些 linux 命令,只会线上部署的一些流程化操作的东西,那么,这个时候你难逃被时代抛弃的命运。
kubernetes 的出现,并没有导致运维这个职业的消失,只是促进了他们的转型。现在运维基本上都是开发型运维,你不但能对运维的工作有属性上的认识,更能真正在这个体系的一些缺失或者薄弱的环节上,通过代码把这些部分补强做实,让整个公司业务的流转更稳定高效。
讲了这么多 kubernetes 出现的意义,我其实也跟那个咨询学员的认知差不多,如果单纯的只是对 yaml 声明式的语法熟悉的话,那的确没什么技术含量。但是对于高可用集群的部署如果你没思维的话,并且如何将你头脑中那些部署方案与 yaml 的命令有效结合相得益彰,这更是一种能力,所以我觉得现在很多公司里的架构师,其实他们天然就具备这样的能力,再加上对于 yml 语法的熟悉,经历几个项目,那么,基本上的云原生是能够上手的,毕竟云原生可以折腾出的部署模式,其实你在电脑上一个个编译几乎都可以安装下来,只是麻烦一些。但是如果说这就是云原生的全部,显然又有失偏颇,其实能到真正架构师这个层面,许多人已经需要十数年的积累了,而且架构是个很考验经验的职业,你一个公司只有十几个人,你在这样的公司做架构,和你在一个有数万人的公司做架构,你们遇到的问题,需要具体的经验量级是不可同日而语的,同样是架构师,差异就这么大。所以能对架构工作驾轻就熟,同时又能对 kubernetes 体系的东西有认知,并能编写有效的 yml 文件,完成预期业务量支撑体系的线上部署,已经需要一定功力了。
但是这些还都不是云原生到顶的功能,云原生说白了,也是应用线上部署。变的只是之前你可能买的是独立的服务器,你数据库、应用程序、代码仓库可能之前都是编译安装的,现在变成了编码好的镜像,但过程没有变。之前你做负载均衡,可能几台物理机,选出一台 nginx 做 vip 机做流量分发,后面放几个 worker 的 nginx 做实际的请求响应,vip 和 worker 之间可能用 bash 起了一个 keepalived 的脚本,来检测 worker 的存活状态,以期进一步调整流量的分发情况。kubernetes 中一样要解决这些问题,只是你之前可能实打实的要代码层面实现轮询算法,实际多活检测算法,踢掉谁保留谁这些你都要实实在在一行一行代码实现出来,穷尽可能遇到的所有异常场景,kubernetes 现在帮你把这些事情都做了,你只要声明你要集群存活时要稳定保持的状态,这套监控和调度的系统就像忠实的、不需要下班的运维工程师一样帮你把它维持在你需要的状态上。
那么,此时我们进一步思考一下,现在我们抛开 kubernetes 不考虑,现在就只拿部署线上应用的组成部分来看,你都听闻过哪些牛逼的技术解决方案。可能每个人的从业经历不同,我头脑中首先想到的就是 LVS,这基本就是业内响当当名号的东西了,为啥需要这个东西,就是因为一台 F5 的高性能机器(几十万软妹币)太贵了,为了能达到同样处理业务量又降低成本的需求,所以它就横空出世了,我还记得那位开发出 LVS 名叫章文嵩的博士因此获得了什么专利,后来到阿里做了技术专家。另外一个想到的,比较牛逼的东西,就是可以自己写 nginx 的插件,我对这个体验特别深刻的经历就是我之前部署我现在网站的一套系统,用的是 docker swarm 的方式(现在已经全线使用 kubernetes 的方式)。当时用了一个库叫做 openbridge/nginx,它里面支持的 nginx 扩展配置项非常多,而这些扩展配置项都是以 nginx 插件形式存在的,你要在 dockerfile 文件中先对插件进行编译安装,再在 nginx.conf 文件中做启用配置才能让它生效,比如说 ip 白名单控制、访问频率限制、ip 地理国家限制、nginx 缓存、pagespeed 加速等等。所以,你意识到什么了吗?传统部署方式遇到问题或者容易出瓶颈的环节,在 k8s 系统里一样也是容易遇到问题和出瓶颈的环节。比如说 kubernetes 中非常炙手可热的领域就是 calico,即网络配置相关,与 carside 服务网格相关的领域 istio,因为所有线上服务最深入骨髓的痛点都是能应对高并发访问,并且在尽可能降低成本的前提下,来尽可能的提高能处理流量的上限。
所以,我的结论也就呼之欲出了,如果你懂架构,又对 kubernetes 的语法了如指掌,那么,你没准可以高效完成业务上云的需求。但是如果你站在公司层面,在尽可能压低成本的前提下,能无限提高业务应付流量的上限,那你就将变得不可多得。那从什么方向努力可以让自己成为这种不可或缺人才,我觉得起码你要在以下这六个方面有所建树。
一、安全管理和治理框架的扩展
kubernetes 说到底也是一个容器编排的系统,既然是系统肯定就有安全防范的考虑,因此常规系统的安全防范策略无论它内置还是通过外部扩展,只要能加强整个系统的安全性,都是要在保证安全和提高系统复杂度及占有主机性能间寻找平稳。这里才给出 10 点最佳实践,这些最佳实践也是安全防护的可选专注方向,你可以从中选出一个,进一步做深入研究。
-
- 启用
Kubernetes的Role-BasedAccesscontrol(RBAC)
- 启用
RBAC 想必做个应用开发的都不陌生,用来定义谁可以访问 Kubernetes API 和他们有什么权限。在 Kubernetes 1.6 以后是默认启用的。
-
- 针对
APIServer使用第三方身份
- 针对
比如 git 集成,sso,auth2 等
-
- 通过
TLS、防火墙和加密手段还保护ETCD
- 通过
etcd 的重要性无需多言,api-server 交互的所有配置情况、交互参数等都在 etcd 落库,所以一定要加强 etcd 的防护。
针对于 client-server 交互做 TLS 配置有如下选项:
* cert-file=: Certificate used for SSL/TLS connection with etcd
* --key-file=: Certificate key (not encrypted)
* --client-cert-auth: Specify that etcd should check incoming HTTPS requests to find a client certificate signed by a trusted CA
* --trusted-ca-file=<path>: Trusted certification authority
* --auto-tls: Use self-signed auto-generated certificate for client connections
针对于 server-server 交互做 TLS 配置有如下选项:
* --peer-cert-file=<path>: Certificate used for SSL/TLS connections between peers
* --peer-key-file=<path>: Certificate key (not encrypted)
* --peer-client-cert-auth: When this option is set, etcd checks for valid signed client certificates on all incoming peer requests
* --peer-trusted-ca-file=<path>: Trusted certification authority
* --peer-auto-tls: Use auto-generated self-signed certificates for peer-to-peer connections
同时,要在 API server 和 etcd 之间设置防火墙。举例,在分离的节点上运行 etcd,同时用 Calico 对那个节点配置防火墙
-
- 隔离
KubernetesNodes
- 隔离
Kubernetes nodes 必须独占一个区分于其它的节点的网络(kubernetes 调度完成集群部署,它自身也属于一个集群组成的节点),同时它也不应该直接暴露于外网。如果有可能,你甚至应该避免让它在公司内网被直接访问到。
这也只有在 Kubernetes 控制平面和数据平面流量隔离的情况下才有可能实现。否则,两者将流经相同的 pipe,并且对数据平面的开放访问意味着对控制平面的开放访问。理想情况下,节点应该配置一个入口控制器,将其设置为只允许通过 ACL (network access control list)从指定端口上的主节点进行连接。
-
- 监控
NetworkTraffic,用以限制访问 容器化的应用通常会大量使用clusternetworks。监控活动网络流量,同时把它与kubernetesnetworkpolicy做比对,来了解你应用的交互情况,同时识别出其中的匿名访问。
- 监控
同时,如果你通过比较放行了相应流量的访问,你也可以有效的识别出没有被 cluster workloads 高效配置的 network policy。而这些信息可以被用于进一步优化 network policy,移除不必要的连接来减少潜在的攻击风险。
-
- 使用进程白名单
ip 白名单想必使用过 nginx 的访问控制插件的都不会陌生,进程白名单也是同样原理,它是一个非常高效的方式来识别未知运行进程的方式。首先,通过对于应用一段时间的观察来确认正常应用运行行为下的有效进程。然后把它作为识别异常进程的参照。
针对于进程运行这个层面的实时分析是相对困难的。在集群间用以分析和识别正在运行的异常进程所对应的安全访问的有些解决方案是有效的,但是进程已经在运行了,此时做分析不但对系统性能有影响,没太大必要,也有点事后诸葛亮的味道。
-
- 开启
Audit日志
- 开启
要确保 Audit logging 开启,用来监控反常和不需要的 API 调用,尤其是身份验证失败的调用。这类日志通常会出现 Forbiden 状态字样,出现这种情况,通常代表攻击者试图违法获取身份校验凭证,只是被拦截了而已。
当上传文件到 kube-apiserver 的时候,你可以用-audit-policy-file 标签来开启 audit logging,同时也要准备定义哪些事件需要被记录。你可以在None、Metadata` `only、Request`(记录`metadata`和`request)、RequestResponse(`前三者都记录`)中选一个合适的日志级别。
-
- 时刻保持
Kubernetes版本为最新状态
- 时刻保持
这个分享一个我的小经历。gitlab 几乎是做自建代码仓库都要使用的一个开源软件包,我在 20 年 3 月份的时候,当时部署我自己项目的代码仓库,当时找到 demo 示例是一个老版本(后来排查问题才关注到这个点),结果安装完几天之后,腾迅云部署的应用,重启之后几分钟就无法访问,腾讯云管理后台重启迅速登录,跟异常情况抢时间,登录成功后对服务器进行排查,发现 cpu 和内存都被跑满了,后来通过不断的观测问题、查询解决方案,才发现自己机器是被挖矿挂马了(之前文章分享过)。后来才知道是 gitlab 版本太老了,用的低版本 redis 有漏洞被挂马了,参照官方 gitlab 升级策略,常驻脚本先跑了一个挂马进程只要一出现就及时杀除的脚本,同时按照策略先升到 3.xx 再升到 4.xx 最终到一个稳定的版本,终于问题不再出来。所以,针对于线上有维护的开源项目,一定要及时更新到最新版本,有专业团队在维护的项目,他们几乎比你能在第一时间知道存在哪些问题,及时打补丁,所以一定一定要及时升级。
-
- 锁定
kubernet
- 锁定
kubelet 是在每个节点上运行的客户端,它与 container runtime 交互来运行 pods,同时给 nodes 和 pods 上报指标。在 cluster 中的每个 kubelet 暴露一个 API,通过与这个 API 的交互可以启动或关闭 pods,同时也可以做一些其他操作。如果一个未授权用户获得了该 API 的访问权限和在 cluster 上运行 node,他们可以渗透整个集群,对整个集群造成影响。
这是一些你可以锁定 kubelet 和降低攻击风险的配置选项。
* 用 `--anonymous-auth=false` 禁止匿名访问,这样未授权的请求就会报错。这样做,`API` `server`需要向`kubelet`标识自己。这也可以通过添加`-kubelet-clientcertificate`和 `--kubelet-client-key`标记来实现。
* 把`--authorization` 设置成`AlwaysAllow`以外的值来校验请求是否授权。默认`kubeadm`安装工具将它设置为`webhook`,要确保`kubelet`调用在`API` `server`上的`SubjectAccessReview`来授权。
* 在`API`服务器准入控制设置中配置`NodeRestriction`,以限制`kubelet`权限。这只允许`kubelet`修改绑定到自己的节点对象的`pod`。
* 使用`--read-only-port=0`关闭`read-only`端口。这样可以阻止访问运行的`workloads`上的信息。端口也不允许`hackers`控制集群,但是可以在探测攻击的阶段使用。
* 关闭`cAdvisor`,它在旧版`Kubernetes`中是用于提供指标,现在已经被`Kubernetes` `API` `statistics`代替。设置`-cadvisor-port=0`来避免暴露运行的工作负载上的信息。这是`Kubernetes` `v1`.`11`的默认配置。如果你需要运行`cAdvisor`的话,就在`DaemonSet`上使用。
-
- 使用类似于
Aqua这类的工具来保护Kubernetes
- 使用类似于
二、网络相关插件
为什么 Kubernetes 中已经有网络相关的组件了,还需要搞网络相关的插件呢?
ingress 想必你做过 Kubernetes 的相关配置,nodePort、port、targetPort 一脸懵逼的体验你想必也有过,我当初也是一样,了解清楚它们的区别之后,想必你也知道如果要暴露一个真正线上可用的网络,恐怕 nodePort 也不会是你的选择。于是就有了 ingress controller 各种实现方式的对比,而系统内置的 ingress controller(也就是 nginx ingress controller)以及 envoy 之争从未停止。而谈及 envoy 就避不开 istio,Istio 是在 Envoy 基础上开发的,并且使用了 Envoy 作为它的分布式代理(后面会深入分析)。
如果你听说过 service mesh 或者尝试过 istio,你可能有以下这些疑问:
- 为什么
Istio运行在Kubernetes上? Kubernetes的角色是什么?servicemesh在云原生中所担任的角色又是什么?Kubernetes的什么方面可以用Istio进行扩展,它引入的目的是解决什么样的问题?Kubernetes和Envovy及Istio之间的关系是什么?
这部分将带你了解 Kubernetes 和 Istio 的内在运行机制。另外,也将介绍 Kubernetes 内的 load balancing 机制,同时也将把当你有了 Kubernetes,为什么还需要 Istio。
Kubernetes 通过声明式的配置对于应用生命周期的管理是必要的,相对的,service mesh 对内部应用流量、安全管理和监测也是必不可少的。如果你已经通过 Kubernetes 建立起了一个稳健的应用平台,那应该如何建立起服务间的负载均衡和流量管理?这也是 service mesh 能够进入我们视野的原因。
Envoy 引入了 xDS 协议,它支持各种各样的软件协议,比如 Istio、MOSN 等等。Envoy 有效拓展了 service mesh 和云原生基础结构。Envoy 是一个可以通过 APIs 进行配置的一个现代版本的代理,在此基础上衍生出许多不同的使用,比如说 API Gateway、service mesh 中的 sidecar proxy、边缘代理等。
这部分包括以下要点:
kube-proxy充当角色的描述Kubernetes在微服务管理方面的局限- 对于
Istioservicemesh的能力的介绍 Kubernetes、Envoy和Istio中一些概念的对比
kubernetes-对比-service-mesh">Kubernetes 对比 Service Mesh
下面的图表展示了 kubernetes 内服务间的访问关系以及 service mesh(每个 pod model 有一个 sidecar)
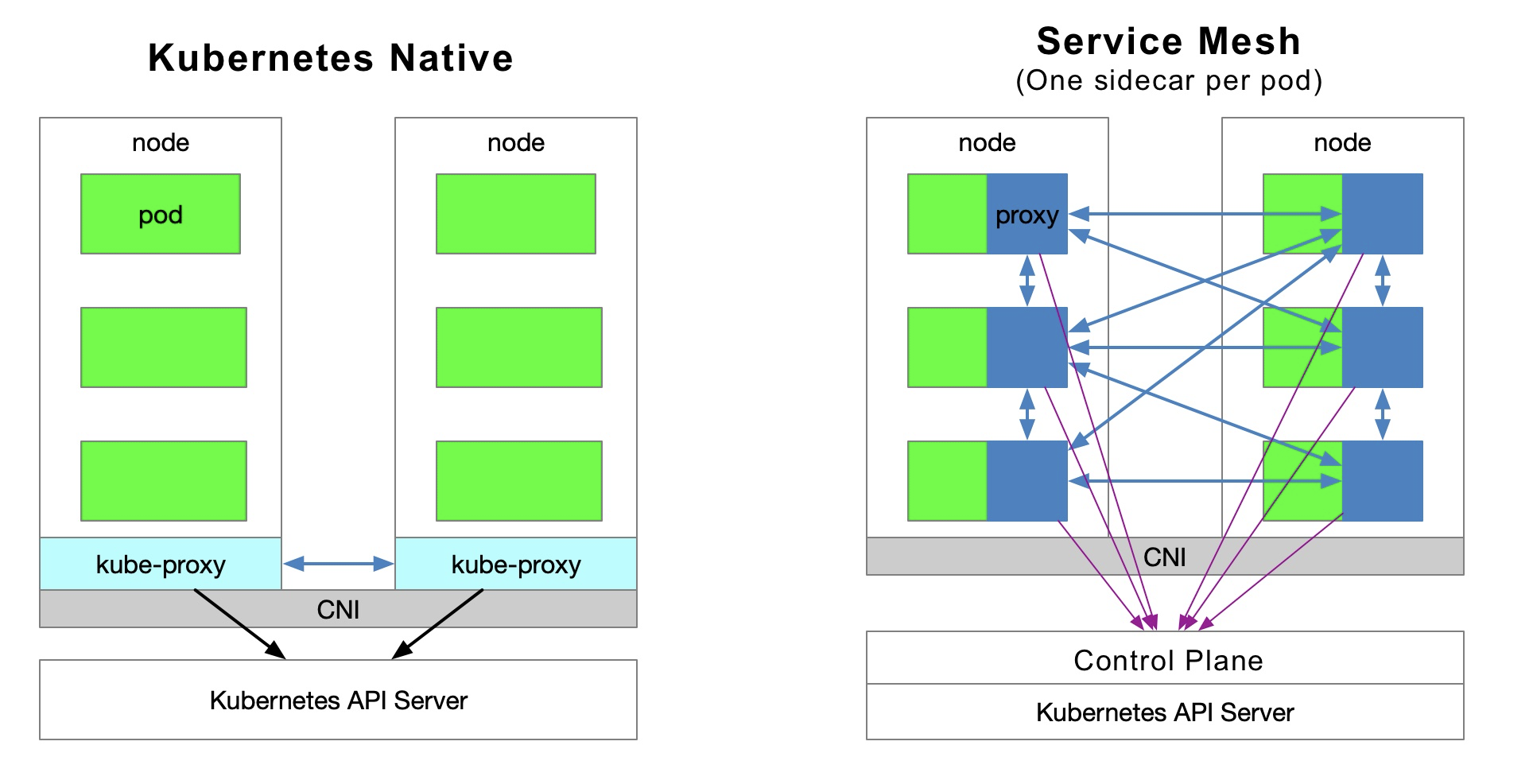
流量定向
Kubernetes cluster 中的每个 node 都部署着一个 kube-proxy 模块,它的作用就是与 Kubernetes API Server 进行通讯,在集群内获取各服务的信息,然后设置 iptables 规则,将服务请求直接发送到相应的 Endpoint(隶属于相同的服务组的一个 pod)。
服务发现
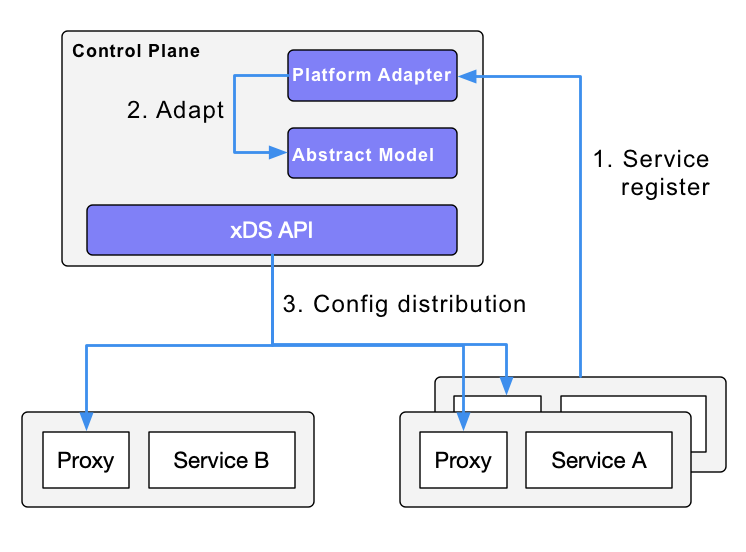
Istio 可以跟随 kubernetes 内的服务注册,同时也可以通过 control plane 内的 platform adapters 与其他的服务发现系统对接。之后针对 data plane 用透明代理生成 data plane 配置(使用 CRD,存储在 ETCD 中)。data plane 的透明代理被部署为每个应用服务的 pod 中的一个 sidecar container,同时所有这些代理都需要请求 control plane 来同步代理的配置。这个代理为透明代理,原因是应用 container 是完完全全不知道这个代理的存在。进程中的 kube-proxy 模块也需要拦截流量,只不过 kube-proxy 拦截的是往返于 Kubernetes 节点的流量,而 sidecar proxy 拦截的是往返于 pod 的流量。
Service Mesh 的弊端
尽管在 Kubernetes 的每个 node 上运行着许多的 pod,把原来的 kube-proxy 路由转发功能放在每个 pod 中会增加响应延迟,因为当 sidecar 拦截流量时会造成更多的 hops,因此会消耗更多的资源。为了更精细的管理流量,就会增加一系列的抽象概念。这将近一步增加学习成本,但随着在云原生领域这项技术越来越流行,大家也就渐渐主动适应这些困难。
Service Mesh 的优势
kube-proxy 的配置是全局的,无法对于每个服务做精细化的控制,而 service mesh 通过 sidecar proxy 的方式让流量控制可以在 Kubernetes 的 service layer 之外完成,让它具备更大的弹性。
kube-proxy 的劣势
首先它无法自动在定向到的 pod 服务异常的情况下自动尝试切换其他 pod。每个 pod 都有一个健康检查机制,当 pod 出现健康问题时,kubelet 会重启 pod,与此同时,kube-proxy 将把 forwarding rules 移除。另外,nodePort 类型的服务无法添加 TLS 或者更复杂的信息路由机制 。
kube-proxy 通过跨一个 Kubernetes 服务的多节点实例实现流量的负载均衡,但是如何在这些服务间做更精细的流量控制———比如针对不同服务版本拆分流量(用不同的 deployments 把相同的服务拆成不同的版本,按比例承接流量),或者做金丝雀发布(灰度发布)和 blue-green 发布?
Kubernetes 的发行组织曾经给出过一种方案来做金丝雀发布,该种方式给一个部署的服务用指定不同 pod label 的方式分配区分不同的 pod,但是看现在 Istio 如火如荼的架势,想必也并非理想型了。
kubernetes-ingress-对比-istio-gateway">Kubernetes Ingress 对比 Istio Gateway
正如上面所说,kube-proxy 仅可以在 kubernetes-cluster 间路由流量。组成 kubernetes-cluster 的 pod 位于由 CNI 创建的网络中。ingress——kubernetes 创建出的资源对象,目的是在 cluster 之外做交流。它被位于 kubernetes 的边缘节点上的 ingress controller 所驱动,用来管理 server-client 类型的流量。Ingress 必须绑定到不同的 Ingress Controller 上,比如 nginx ingress controller 和 traefik。Ingress 只可以对于 HTTP 类型的流量起作用,使用方式也简单。它只可以路由符合有限数量字段的流量,比如说 MySQL、Redis、和各种各样的 RPCs,这些它就无能为力了。这就是为什么你会看到大家都在 ingress resource annotations 中写 nginx 配置元语的原因。仅有的直接支持 server-client 类型流量的方式就是使用服务的负载均衡或者 NodePort 端口,前者需要云服务商支持,后者需要额外的端口管理。有些 ingress controller 支持对 TCP 和 UDP 类型的流量都进行暴露,但是却只能通过 service 的方式,ingress 本身是不支持这样操作的,最常用的 nginx ingress controller,之所以能实现,也不是内置 ingress controller 本身就有支持,而是借助于 ConfigMap 的使用来达到目的。
Istio Gateway 功能与 Kubernetes Ingress 类似,它负责集群的 server-client 间的交互。Istio Gateway 描述了一个负载均衡器,用于承载进出 the edge of the mesh 的连接。这种声明描述了一系列被这些端口使用的开放端口及协议,用于负载均衡的 SNI 配置项等。Gateway 是一个 CRD 扩展,它也重用了 sidecar proxy 的功能,具体怎么配置,可以看看 Istio 的官方网站。
Envoy
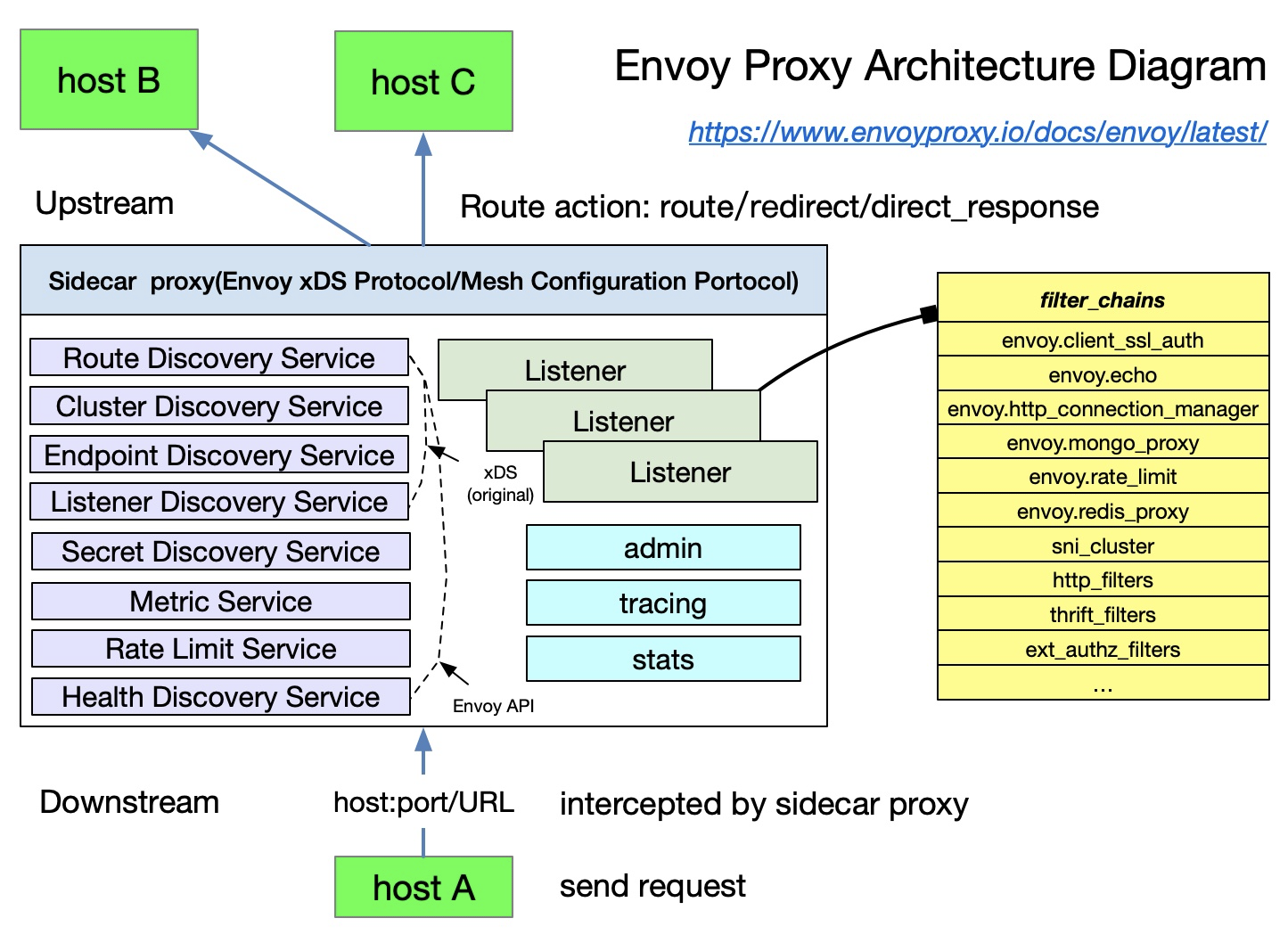
Envoy 在 Istio 中是默认的 sidecar proxy。Istio 基于 Envoy 的 xDS 协议扩展它的 control plane。在谈论 Envoy 的 xDS 协议之前,我们需要先熟悉 Envoy 的基本术语。以下是 Envoy 中的基本术语及其数据结构的列表,更多细节可以翻 Envoy 文档看看。
基础术语
以下是 Envoy 中你需要知道的一些术语:
Downstream: 下游主机连接到Envoy,发送请求,并接收响应,也就是说,发送请求的主机 。Upstream: 上游主机接收来自Envoy上连接和请求,并返回响应;也就是说,接收请求的主机 。Listener: 它是一个命名的网络地址(举例:port、UNIXdomainsocket等等);downstream端可以连接到这个Listener。Envoy暴露一个或多个listener给downstream主机建立连接。Cluster: 它是一个针对upstreamshost做逻辑分组的cluster。Envoy通过服务发现来发现集群成员,此外,可以通过主动的健康检查来确定集群成员的健康状态。Envoy通过负载均衡策略决定集群的哪个成员来路由请求。
可以在 Envoy 中设置多 Listeners,每个 Listener 都可以设置一个 filter chain(filter chain table),同时这些 filter 支持可扩展性有利于更容易管理流量的行为———比如说设置 encryption(加密)、private RPC 等。
xDS 协议是由 Envoy 提出的,在 Istio 中它是默认的 sidecar proxy,但只要实现了 xDS 协议,理论上就可以在 Istio 中作为一个 sidecar proxy 来使用———比如 Ant Group 的 MOSN 开放源代码。
Istio 是一个特征丰富的 service mesh,它包括以下扩展:
TrafficeManagement:Istio最基础的功能PolicyControl:启用系统访问、telemetry采集、配额管理、计费等。Observability: 在sidecarproxy中实现SecurityAuthentication:Citadel组件负责密钥和证书管理 。
istio-中的流量管理">Istio 中的流量管理
以下 CRDS 的定义帮助用户做流量管理 。
Gateway:在边缘网络上描述负载均衡,同时用于接收incoming或者outgoingHTTP/TCP连接VirtualService:它将Kubernetes服务连接到IstioGateway。它也可以执行额外的一些操作,比如在主机被寻址时来定义一系列的路由规则。DestinationRule:DestinationRule中定义的规则决定了流量被路由后的访问策略。简单的说,它定义了流量的路由。其中,这些策略可以定义为负载均衡配置、连接池大小和外部检测(用于识别和驱逐负载均衡池中不健康的主机)EnvoyFilter:它用来描述针对于proxyservices的filter,可以制订由IstioPilot生成的代理配置。这种配置一般很少被初级用户使用。ServiceEntry:默认情况,在Istioservicemesh中的服务在Mesh之外是无法发现服务的。ServiceEntry使得额外的条目可以被添加到Istio内部的服务注册表中,因此,允许mesh中自动发现和服务访问和路由到这些手动添加的服务。
kubernetes-对比-xds-和-istio">Kubernetes 对比 xDS 和 Istio
回顾了 Kubernetes 的 kube-proxy、xDS 和 Istio 中抽象化的流量管理逻辑以后,让我们现在仅针对于流量管理领域来把这三个模块/协议做下对比(要注意这三者并非完全等同)。

一些经验之谈
Kubernetes的精髓是应用程序的生命周期管理 ,特别是部署和管理(弹性扩容、自动恢复,发布)Kubernetes为微服务提供了一个可扩展和高弹性的部署和管理平台servicemesh是基于通过sidecarproxies拦截服务间的流量的透明代理,然后通过controlpanel的配置来管理它们的行为servicemesh将流量管理从Kubernetes中解耦出来,不需要kube-proxy组件来支持servicemesh内的流量,并通过提供更接近微服务应用层的抽象来管理服务间的流量,具安全性和可监测性。xDS是针对于servicemesh配置的一种协议标准。servicemesh是对kubernetes内部服务的一种更高层级的抽象。
做下总结
如果 Kubernetes 的管理对象是 pod,那么 service mesh 的管理对象就是 service,所以只是用 Kubernetes 来管理微服务,然后加配 service mesh 来做 service-client 流量更精细的管理而已,逻辑就这么简单。如果你不想对服务做管理 ,那样的话,用一个类似 Knative 这样的无服务平台就可以了,当然这就是后话了。
这部分中,我从覆盖网络插件中选取了 Istio 这个极具代表性的例子,并对它与 kube-proxy 这个 kubernetes 集群内 pod 上自带的可以处理有关网络请求的组件进行了比较,并把引入 Istio 在解决哪些问题做了详细说明,把实现 Envoy 首先提出的 xDS 协议通过 sidecar proxy 的方式率先将 kubernetes 内部的 kube-proxy 承接的流量彻底解耦成集群管理模块之间的流量与外部 server-client 类型的流量,这就是它存在的意义。而我在文章开始的部分,也基本讲清楚了,kubernetes 是服务集群的管理工具,但是集群服务跑起来稳定运行以后,应用存在的意义还是要精细化的管理 server-client 类型的流量,而 k8s 没出现之前,如何高效承接流量就一直是互联网时代技术革新的必争之地,因为这是实实在在如果有效改进会省下许多银子的部分,所以 k8s 时代,web2.0 时代会成为瓶颈的东西,今天依然会最先成为瓶颈,k8s 让集群部署更加高效化,但是之前 3 台服务器搞不定的问题,不是说你用 k8s 就可以搞定了,它没有强化你的流量处理能力,只是把上线过程高效化、规范化和可监测化了。你可能会说,你知道阿里云的 MSE 的云原生网关,性能很强,之前可能需要 3 台能承接下来的访问流量,现在 1 台就可以了,所以你讲的是错的!但我提醒大家要明白,k8s 是顺应当前互联网发展而新兴的技术,因为它已经成为行业标准了,上去的诸多好处也已被广大企业接纳愿意花钱,所以 k8s 就成为业务投入的目标,所以对它的优化和拓展才导致了它有如今的强劲的性能,就是之前 500 个程序员的时间可能花在了传统部署模式上,现在不用那套了,用 k8s 了,因此 k8s 相比于传统的一些部署模式才会如此亮眼,假如这 500 人还在传统模式上精工细作,你想哪个会胜出。k8s 只是一个工具,工具提升效率,但是工具并不能无中生有!无中生的有也是因为投入才有产出的,如果没有盈利点,阿里云会搞个 MSE 出来吗?用膝盖都想得明白吧!
因此,原来要处理网络请求你需要思考的技术方案,假如就给你 3 台机器,没成本再加了,你 k8s 出现前想咋解决并且验证有效了,今天依然可以用那些方法,只是 k8s 现在又成了一个门槛,可能你之前按着文档或者网上答案,一步一步贴代码完成相应服务的部署上线,现在如果没人分享,没中文教程,你可能就要自己啃英文,不断尝试,把想要的部署架构以 k8s 支持的声明方式,或者插件扩展的开发方式引入进来,以方便 k8s 的集中管理。这也是我为什么说网络相关的 k8s 方向的深度挖掘是一个很值得追踪方向的原因,因为互联网所有根基的东西,恐怕说通信网络为第一,没有人会反对吧?

三、存储扩展
存储的扩展解决的依然是传统互联网时代都要面临的问题,如果你曾经对接过七牛云你一定知道我在说什么。同样是服务器集群,k8s 部署之后管理方便了,但是有些存储相关的业务,你放在自己服务器上,特别你的服务还跨时区支持全球访问的话,那么,在保证业务通过 k8s 部署后稳定运行的基础上,你还要考虑到各地用户的访问体验,如果全部都要自建机房,可能也没多大必要,另外开销也太大。所以提供全球都有节点部署的服务器集群,在针对于存储方面能有效做支持就是性价比很高的解决方案,就不妨把这类业务对接到这些第三方。一是这些提供存储的厂商有全球节点布局,同时术业有专攻,植根在存储、CDN 等领域的专业团队,他们在处理相应业务场景上的经验以及投入成本都非常大,也代表着他们可以提供出更专业及更具性价比的方案。而在 k8s 中对于存储做扩展也是很多 sass 平台、baas 平台常常面临的问题,那 k8s 中如果想对存储做扩展,应该从哪几方面入手呢?
看过我前面部分的朋友,应该都不会陌生,我提到过我主动接手,基于 CSI 的 out-of-tree 模式开发的存储扩展插件。现在 CSI 已经成为主流,如果不出大问题,未来也将是主流,为什么?
我们知道 in-tree 模式,天然耦合在 kubernetes 中,如果针对其做开发,对于 kubernetes 可能产生影响,并且迭代效率肯定很慢,对于有针对性需求的朋友肯定是不友好的。后面也有了 flexvolume 的插件开发模式被得到支持,但是这种模式的插件不能理解为一个真正的常驻内存的有效业务扩展方式,如果你以这种模式开发过,或者大概了解过,你也清楚,它基本就是在用 shell 语法来支撑逻辑,然后把开发出的脚本放到 kubernetes 插件开发要求放置的目录,然后在 kubernetes 的 yaml 文件中指定就可以,也因为这些原因,所以 out-of-tree 模式的非 shell 方式的插件开发亟需得到支持,于是就有了 CSI 当前流行的这种方式。因为已经对于 CSI Identity、CSI Controller、CSI Node 主要的职责进行了划分,所以你根据对接的外部存储的类型,只要选择合适的组成部分,并实现该部分要求你实现的所有接口,插件就开发完了。好处我前面也有说到,一是对 kubernetes 的系统侵略性小,开发规范明确,不至于太灵活而你又没有评估清楚可能造成的影响,而对整个 kubernetes 集群造成影响。
对于这段话进一步解释一下,选择合适的部分,就是 CSI Identify、CSI Controller、CSI Node 都有各自的职能,比如说 CSI Identify 主要对外暴露插件本身的信息,确保插件以健康态运行;CSI Controller 划分成 Provision 和 Attach 两个阶段,前面的主要与创建删除 Volume 流程有关,后面的主要解决把存储卷附着在某个节点或者脱离某个节点的流程,并且你如果你不处理块存储相关的业务,实际你并不需要实现 Attach;CSI Node 主要目的是针对于 kubernetes 节点上的 volume 提供相关功能,Volume 的挂载可分为 NodeStageVolume 和 NodePublishVolume 两个阶段,前面针对块存储,后面主要解决 pod 挂载目录的问题。你知道这些部分的主要作用,就可以根据你存储业务要支持的类型,选择需要哪部分,不需要关注哪部分,大方向确定了,再把里面需要实现的接口实现出来,插件也就开发完毕了。所以,存储相关插件的开发也是 kubernetes 继续深入一个值得关注的方向。
四、CI/CD 相关的插件
docker 在 k8s 生态中现在扮演的角色很尴尬,但你要知道哦!docker 最初对于 google 站出来做容器编排的行业标准想把 docker 收编麾下的时候,docker 可是嗤之以鼻的,什么导致 docker 在云原生生态中的角色变得不那么重要了呢?我觉得 CI/CD 的推波助澜绝对是杀手级的!毕竟 docker 最初和现在做的镜像和容器管理,cgroup 其实早都可以做了。而 kubernetes 之所以成为云原生的行业标准,就是因为它不只解决了这两个问题,也把集群生命周期管理、环境隔离、scrum(敏捷开发)高效简单的落了地。而 CI/CD 就是 scrum 不或或缺的一环。有了它的存在程序的自动化构建、测试、部署、业务集群的伸缩、运行状态的容错、流量重放、流量镜像、高效的部署节点的管理与维护都成了现实,业务代码 1 天上 8 版 18 版甚至 180 版都有可能,这在传统部署时代是很难想象的。
这个可以扩展的方向就太多了,DevOps 的简化部署工具有很多,从简单的集成到 github、gitlab 内的 gitlab-runner,到伴随着 java 开发历史的 Jenkins,再威名远扬的 devStream。在 DevOps 这个领域,针对特定需求,本身就存在着各种各样好用的工具,或者工具本身也充当着加强或者优化它工具的拓展平台,就比如说 Jenkins,如果你想完成自动编译部署,它本身很多与代码库、与验签相关的组成部分它并不提供,你就要安装 Jenkins 内置的几个插件,它们可以完美支持你基于 Jenkins 的自动化集成部署任务,当然也因为这种拓展的灵活性的存在,所以如果你不熟悉流程,不跟过几个项目,不亲手操作几次,你可能就掌握不了这个过程,所以这也是 Jenkins 为人所诟病的地方。devStream 可以理解成为一个类似于其它语言项目中的包管理工具,它本身就集成有各种各样的功能,所以把它称之针对于 DevOps 的工具链管理器,既然你看到了工具链几个字,就能想象到它不是提供单一某方面的功能,而是对于 DevOps 的全链路涉及到的工具都进行了集成,比如,说到项目管理,大名鼎鼎的 jira 想必无人不知无人不晓,我们公司现在有一些项目它的管理工具依然是 jira。源代码管理这个太重要了,以至于至今存在的几家都有自己固定的客群,比如著名的同性交友网产 github.com,比如公司内部部署基本都用到的 gitlab,针对于小团队或者相对低性能机器做了针对性优化的 gitea。持续集成,少不了我前面提到的 Jenkins,当然现在又涌现出了大量优化的同类型工具,比如说 CircleCI、TravisCI 等等。持续交付、持续部署领域好用的工具,比如说 FluxCD、Flux2、Argo CD 等。证书和密钥管理这里也是不可或缺的环节,这里就少不了提一嘴 Vault 了,它是证书和密钥管理的成形解决方案,很多基于 Dubbo 的服务中心项目后端用到的配置中心也是对接在 Vault 上,当然万年不变定律也依然有效,那些大厂都有自己的封装,比较有名的比较阿里的 diamond,某度的 disconf 还有国外知名的 netflix 用的 archaius。但是 applo 绝对是搞这个少不了的角色。再来说集成的监控和日志记录工具,这个就太多了 ELK 几乎无人不知无人不晓,Prometheus 和 Grafana 更几乎是所有公司的做监控和日志的不二之选,也是 AOP 思想的集大成者,总之,如果说 DevOps 的话,简直工具一箩筐,根本说不完,正因为选择多,也就面临着一个问题,就是选择困难症人群那简直就是噩梦,而 devStream 出现就类似于给你一个把这些好用的 DevOps 相关的工具都集成到一块的脚手架,你开箱即用即可。
所以我们先来说说针对于 devStream 做二次开发的逻辑,再来讲一讲针对于我提到的这些工具链上的好用工具,如果你想做二次开发,你应该秉承的思路。
DevStream 的插件开发思路,跟我前面提到的针对于 CSI 插件的开发思路都类似,或者说现在主流的插件开发思想就是这样,类似于接口的概念,就是接口定义出相应的属性和方法,你来把这些实现出来,这样做既能符合规划,不僭越到核心代码中,又可以实现一定的扩展灵活性,简直不要太好用好不好。
devStream 主要通过三个配置文件来定义你的 DevOps 工具链,即主配置文件,变量配置文件和工具配置文件。主配置文件里又包含以下几个专有属性,varFile 用来指定 var 文件的路径,toolFile 被称为工具文件的文件路径,而 state 是与状态相关的配置。它们都支持指定外部 yaml 文件,文件中声明属性信息和 rbac 相关。
整个的处理流程如下图:
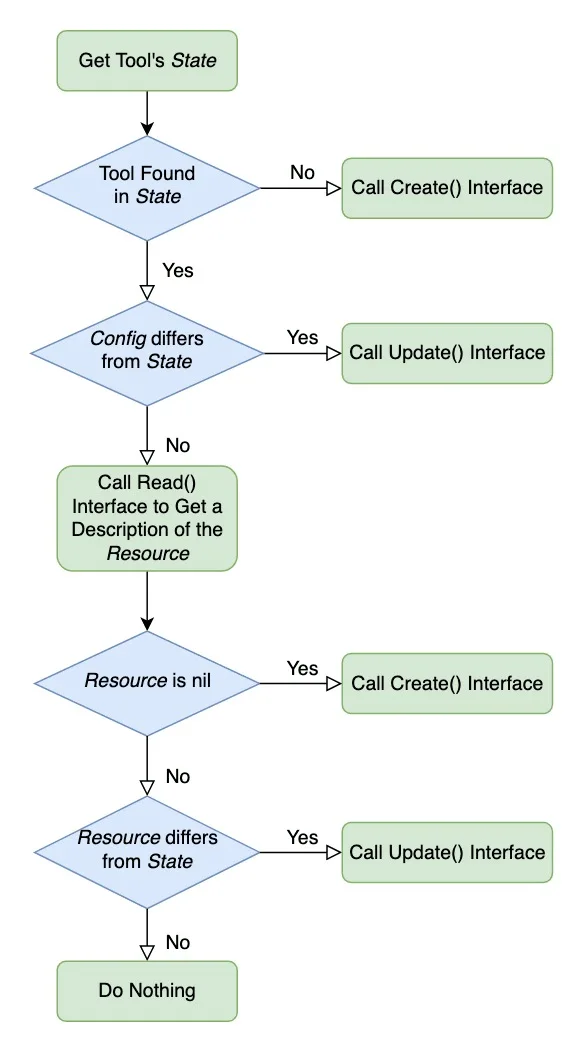
devStream的工作流程
从这个图中,我们大概可以得到这样的信息,devStream 首先会获取工具的状态,如果状态中找不到工具,调用 Create()进行创建,找到了调用 Update(),如果没检测到变化则调用 Read()获取资源的描述信息,如果没资源可用,依然调用 Create()函数进行创建,把资源与存在资源做对比,如果有变化调用 Update()函数,如果没有变化,则忽略此次操作。
devStream 的构建要用到它的命令行工具,称为 dtm。就像如果你有一个 docker swarm 的项目你想把它转换成可以支持 k8s 方式来部署,那么,你可以下载一个 kompose 的工具,这个原理也是一样,就是能帮你脚手架出插件的组织结构,即要有哪些目录,要有哪些默认的文件等。
我们用命令 dtm develop create-plugin 来创建插件,我们以创建一个测试插件为例,取名 plugin-test,执行完这个命令,生成如下目录树:
$ tree .
.
├── README_when_create_plugin.md
├── cmd
│ └── plugin
│ └── plugin-test
│ └── main.go
├── docs
│ └── plugins
│ └── plugin-test.md
└── internal
└── pkg
├── plugin
│ └── plugintest
│ ├── create.go
│ ├── delete.go
│ ├── options.go
│ ├── plugintest.go
│ ├── read.go
│ ├── update.go
│ └── validate.go
└── show
└── config
└── plugins
└── plugin-test.yaml
12 directories, 11 files
脚手架工具已经把插件基础结构生成出来了,你就可以根据你的业务需求,开发对应插件了,这就考验你的 golang 的功力了。
而针对于工具链上我上面提到的那些各流程中都非常好用的工具,它们的扩展对于一些公司的某些类业务也是必不可少的,想要做些类扩展的开发,我给出一个我采用的思路。就比如说你想对 k8s 的执行流程有清晰的认识,甚至对代码层面的调用过程都如数家珍,那么,你首先就要对于 k8s 执行到哪个环节了,调用到哪个服务了,头脑中有清晰的层次感,那这种层次感如何获得?肯定就是不断的折腾呀,不断的部署,部署不同类型的服务,观察引起的细微变化,这样你就能对于 k8s 的执行流程就有了非常直观的概括性的认知。之后就是进一步深入细节了,比如说所有交互的作用都依赖于 k8s 的 api-server,而跟这个接口做交互的方式就是声明式的 yaml 文件,因此,你就可以进一步探究为啥这个指令就能引发 pod 的创建,那个声明指令就能引发 replicate 的增减或者分配资源的更新,那肯定就有一个类似于 mvc 模式里的 controller 类似的东西存在,它能把指令参数获取到并下发给调度服务。所以你就可以一点点深入阅读这些代码了。所以你觉得这样的思路对于你开发 DevOps 工具链上其他工具的插件有所借鉴。
由于篇幅已经太长了,其余2个方向及一些极有用的工程化云原生开发技巧,我们放到下篇文章中,敬请期待,感谢阅读!


