油管1个月迅速赚美dollar经验及colly实战爬取美女图片站点源码级细节分享,绝对不容错过golang技能buff加成!
本文总共分为四部分,第一部分扯闲片,也算是打个广告,想看技术干货,直接从第二部分开始,但是如果你想搞钱或者欣赏美女,还是建议你从头食用,效果更佳~还有上万上高清美女私房图片可以领取哟!嘻嘻。第二部分,主要是讲colly之前的引子,用大名鼎鼎的scrapy做开胃菜,帮你系统了解一下scrapy是如何实现自己的爬虫代理的!正所谓殊途同归,只有举一返三,方能融会贯通!第三部分,我们的主角colly该出场了,把实现它代理的方式通通告诉你,保证你的golang开发功力又会提高一大截!第四部分,牵扯到爬虫,那些必然面对的问题一个跑不了,而最关键的怕就是重复过滤了,于是我把我在colly里使用redis做布隆过滤的方案分享给你,相信你如果有爬虫需求,这也是迟早都用得上的不时之需,顺便也提了下我对colly实现分布式的理解!
colly被我使用的由来以及对于自媒体搞钱创业者从油管赚钱的经验分享以及对国内林林总总dog平台的吐槽">第一部分:讲讲colly被我使用的由来,以及对于自媒体搞钱创业者从油管赚钱的经验分享,以及对国内林林总总dog平台的吐槽
最近几个月大量生产了上万个视频,包括我自己选定的领域,以及接的一些商单。
国内的短视频平台,视频平台,我之前已经写过文章分享过,现在在坚持更新的平台只有抖音,为什么呢?因为这是我收学徒的渠道,也能为我中长视频提供素材,同时也相对来说,那种公平、公正、凡事因循宿果你都能明明白白,至于抖音本身依然很狗,可能只是铁拳还没打向我而已。而至于西瓜、b 站之流,我之前文章中就分享过,我 4 天时间就达标中视频计划,结果因为一个改标题的问题,这个傻逼的平台,像其他国内所有平台一个操性,就说不符合价值之类,具有负面引导性,我去了麻辣个逼,因此弃更,b 站一路操性,麻袋上绣花,一代不如一代,舔的让人恶心。
再总结下油管运营情况,油管已经开了六七个 channel,大概年初开始的,有三个已经开始赢利了,现在收益不多,几百到上千美刀不等。最近 1 个月又在 2 个题材方向对于油管平台做了测试,大概一周时间生产了 1500 个视频,每天每个频道 15 个视频,效果也比较显著,按现在的趋势,大概再有一到 2 个月时间也能达到开通收益门槛了,现在觉得国内狗逼平台最大的问题估计是他们都不知道自己该服务于社会准则还是一群狗的拍脑袋。如果让我分享目前我年初开始做油管,以及最近一个月时间觉得最有效的油管运营经验,我觉得是以下这 3 条:
一、数量大占据绝对优势,大力出奇迹,只要视频质量在及格线以上,你只要短时间之内足够多,你就具有绝对的竞争优势
二、油管讲求规律更新,不要三天打鱼两天晒网,就现在这个卷到如此的时代,如果连坚持你都做不到,你能获得成功我觉得挺天方夜谭的
三、视频时长要上要心机一些。比如有些几分钟,这种想快速达到 4000 小时播放量,是相对慢很多的,所以你要在这种时间长度的频道下,有意搜集或创作一些半小时、一小时、甚至更长时长的视频,这也是我准备在抖音开直播的原因!这样一结合就很容易达到开通收益门槛,我截图,你们感受下:
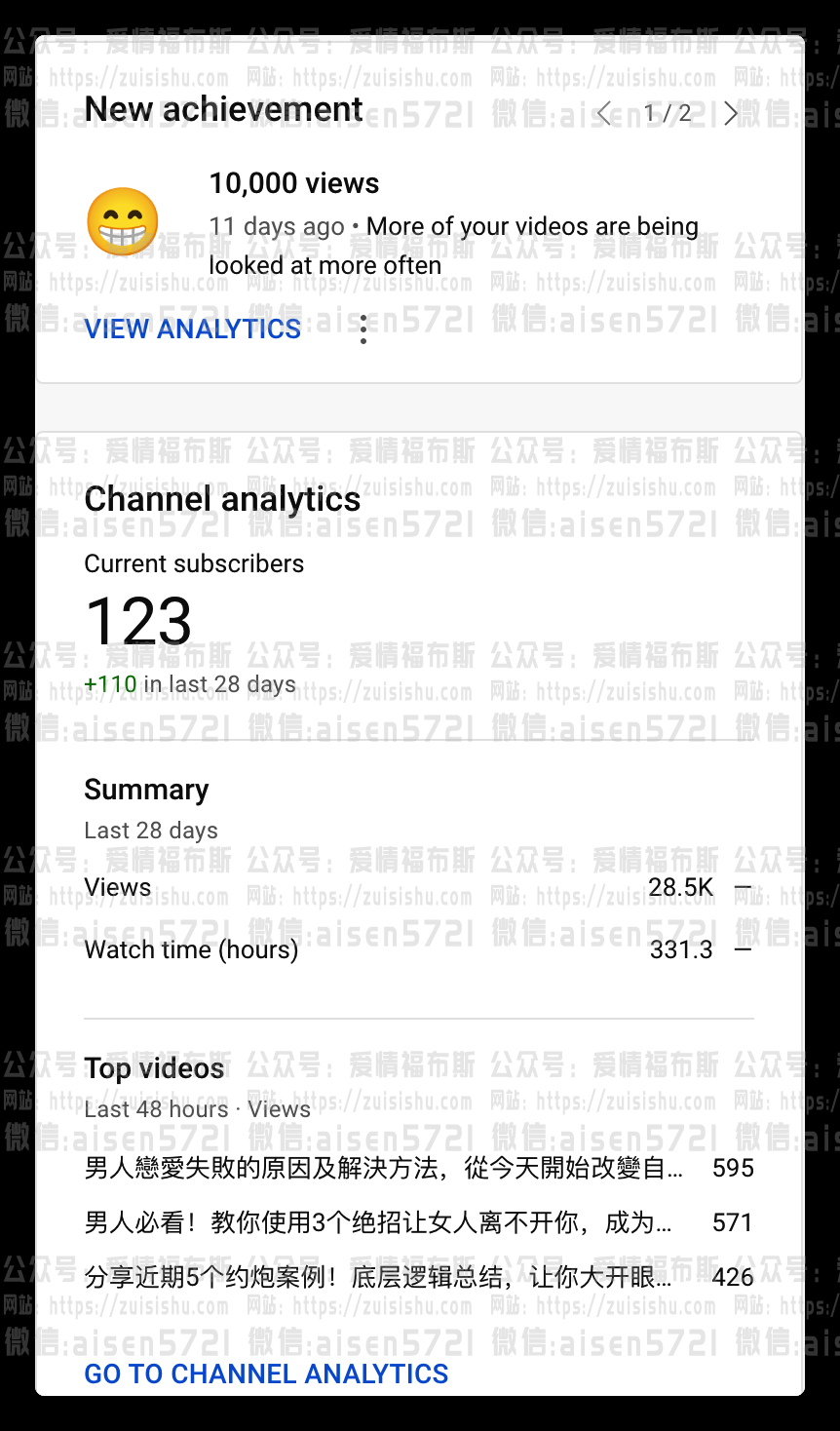
这是测试其中的一个频道,都是几分钟的视频,所以大概一个月时间,它播放时长330小时,距离4000小时播放时长相对长点
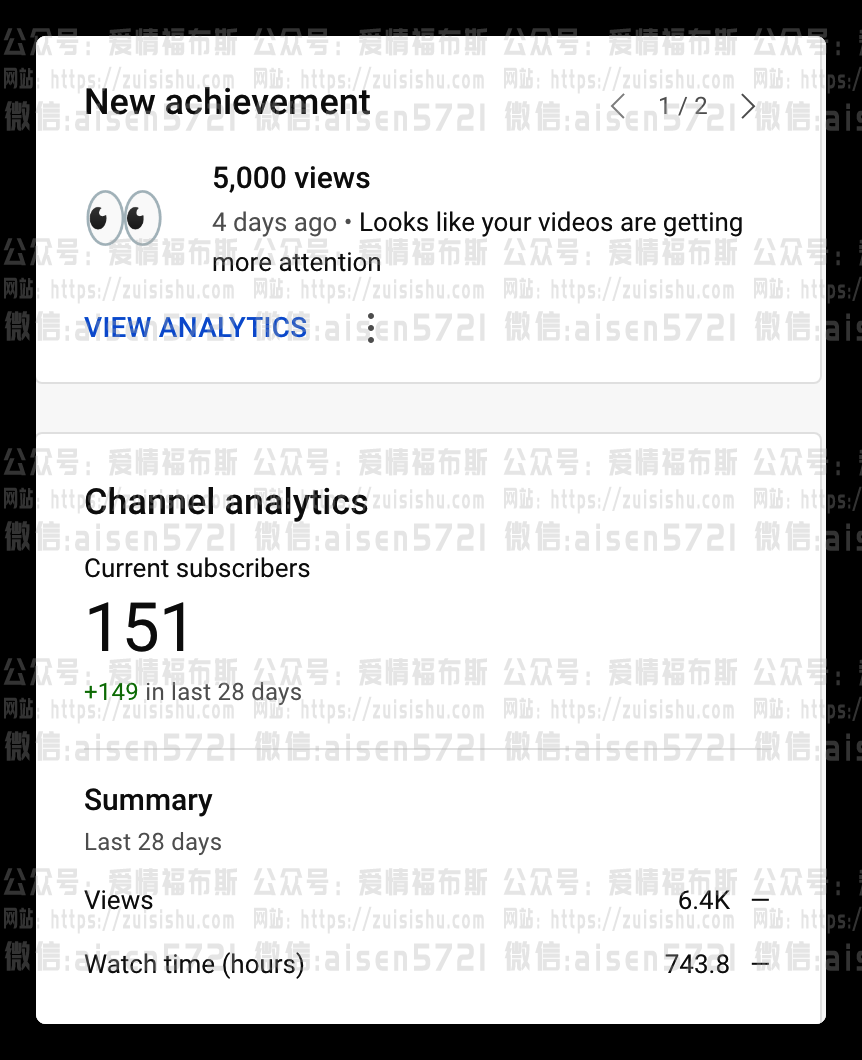
这是测试其中的另一个频道,都是15分钟以上的视频,还有好多几个小时的,所以大概一个月时间,它播放时长740小时,距离4000小时播放时长是不是感觉近在咫尺?
开始正文之前,先打个硬广,如果你想运营自己的油管频道,或者有量产视频的需求,欢迎骚扰。同时也请这类人不要联系我,最近通过知乎上还有公众号文章过来的人,有套方案的,有些我自认为有问必答,结果聊到钱的环节时候,说我的报价贵,他自己去闲鱼买那种快速搬运的软件才多少钱,我就用我知乎上的回复来提示下这类人,不要联系我,谢谢,彼此没交集就是对彼此最好的尊重!
好了,下面正文开始。
因为我自己所涉及的领域会跟两性相关,通过我不断的观察和分组实验,美女绝逼是亘古不变的男性追求,我之前怎么批量生产视频的文章,我在文章开头秀了一把我自动生成的封面,当时的背景图片是我本人,就技术领域而言无可厚非,但是针对于情感领域,必须封面要足够性感,配上我生成封面文字的脚本,两者相得益彰,这也是我搞流量的手段,现在通过油管后台数据的观察,效果可观,但是我之前的图片都是知乎上随便找的,用的 chrome 的图片下载扩展,随便用用可以,它需要你针对于 chrome 的滚动条,你想下载至界面某位置的图片,就要拉到某位置,挺累的,效率也不高,恰巧在找图片的时候,发现了某网站,恰好符合我的要求,于是就有了把该站点图片全部下载下来,用于随机生成封面图使用。
先看一下生成的效果。







这次跟之前最大的改变就是图片进行了平铺,因为几乎所有图片都是竖版的,这也能理解,我本身也有业余给拍照的业务,女孩子嘛,还是想发美美盆友圈的,所以竖版几乎成了习惯,但是这样在一些横屏封面的网站,比如说油管,比如说国内的西瓜视频、bilibili 就不适合了。所以我就做了平铺,这个平衡当然也有讲究,我调整了很多个版本,比图片原来最从左到右排,后来发现左侧文字占版,所以右到左排最合理,一张图重复几遍,和几张不同的图拼成一张,并以最右图片为标准,使所有目录下图片都被使用到,也是我最终选择的思路,也是现在用的逻辑,几张不同图从右向左迭代,至于哪种效果好,男生更吃哪一套,可能就仁者见仁智者见智了,我个人比较偏好于现在使用这一种。我已经把图片进行了打包,如果想欣赏一二,欢迎自行领取。
scrapy实现代理方式我们从中可以汲取什么历久弥新的东西">第二部分:举一返三,方能融会贯通,先让我们看看scrapy实现代理方式,我们从中可以汲取什么历久弥新的东西
而这次抓取这些图片,就是用的 colly,也是基于 golang 很有名的一套爬虫框架。
想用 colly 做爬虫的念头已经萌生很久了,我之前有分享过我的一些有关爬虫的经验,其实相对于用 colly,我可能用 python 系的 scrpy 的效率更高,但是毕竟对于 golang 还是有些执念的,恰好借些时机将念头付诸实施。
关于框架的使用,其实感觉没什么好说的,毕竟多找找例子,多看看 demo 就可以了。但是在这个过程中我思考了一下自己之前用 golang 实现框架的一些细节,发现有些东西自己实现下来,比如说一些更容易跟程序运行逻辑结合的中间件,你非要读一下它的源码不可,不然你实现的灵活性将受到很大的限制。
比如说之前开发 scrapy 的中间件的时候,你当然可以使用封装好的方法,在scrapy.Request的请求参数里面把这个代理配置上去就可以,但是你要知道这种实现手法,是基于底层的什么方面的什么函数在起作用,这样你就能更容易从底层切入,也能对框架的结构有更深的理解,举例:
#方法一:我上面说的,在Request中传一个参数
def start_requests(self):
for url in self.start_urls:
return Request(url=url,callback=self.parse,headers={"User-Agent":"xx"},meta={"proxy":"http:/154.112.82.262:8050"})
#方法二:创建自定义的代理中间件
from w3lib.http import basic_auth_header
class MyCustomProxyMiddleware(object):
def process_proxy(self,request,spider):
request.meta["proxy"] = "http://xxx.xx.x.x:8050"
request.headers["Proxy-Authorization"] =
basic_auth_header("<proxy_user>", "<proxy_pass>")
#然后在DOWNLOAD_MIDDLEWARES对于你自定义的中间件进行配置,这样爬虫运行时才会加载到这些配置,并保证在执行时你的配置可以被用到
DOWNLOADER_MIDDLEWARES = {
'myproject.middlewares.CustomProxyMiddleware': 350,#优先级越高,会越先执行,
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': 400,
}
#方法三:在settings.py文件中把代理ip以数据结构lista或以文件的形式声明,同上步一样,也需要在DOWNLOAD_MIDDLEWARES中进行配置
ROTATING_PROXY_LIST = [
'proxy1.com:8000',
'proxy2.com:8031',
'proxy3.com:8032',
]
# above is same as add this to settings.py
ROTATING_PROXY_LIST_PATH = '/my/path/proxies.txt'
#启用
DOWNLOADER_MIDDLEWARES = {
'rotating_proxies.middlewares.RotatingProxyMiddleware':610,
'rotating_proxies.middlewares.BanDetectionMiddleware':620
}
#方法四,几乎用这种方式都是针对隧道代理
class MyCustomProxyMiddleware(object):
@classmethod
def from_crawl(cls,crawler):
return cls(crawler.settings)
def __init__(self,settings):
self.username = settings.get('PROXY_USER')
self.password = settings.get('PROXY_PASSWORD')
self.url = settings.get('PROXY_URL')
self.port = seetings.get('PROXY_PORT')
def process_request(self,request,spider):
host = f'http://{self.username}:{self.password}@{self.url}:{self.port}'
request.meta['proxy'] = host
我准备讲的是colly的爬虫,你可能好奇,为啥我把scrapy给的这么详细,我想你能通过我的这个层层递进的scrapy中的代理实现方案,能用我这个思维递进的角度来看后面我要讲的colly设置代理的两种方式,因为几乎是殊途同归的,简单对于scrapy这几种方案做下总结,前面的方式,直接meta中设置代理,最简单,不用自定义新的代理中间件,随处使用,可能不方便的点就在于,几乎固定的代码ip地址会跨很多项目,或即使一个项目也用好久几乎是不太可能的,所以这种就把代理和爬虫本身耦合做的很高,因为针对一些复杂的爬虫项目,特别是有些需要的dom元素值是很多异步加载得到的,那么这个爬虫类,可能会有很多自定义的解析函数,那么当这些地方就加了代理后,突然代理换了,那你就要全部改一遍,即使用一些相对稳定性较好的隧道代理方式,但是耦合性本身依然是存在的。
而后面自定义代理类的好处在就在于,它就是完全独立出的抽象类,你可以在任何一个项目中把这个代理类copy进去,只需要在配置文件中把代理配置更改一下就行,这样耦合的问题就得到了很好的解决,而它因为覆写了底层的爬虫request类,就是所有调了scrapy.Request函数的地方都自动加上了代理,是不是感觉方便多了。
holly代理的实现思路也和这个是一致的,简单你就可能修改代码时要关注的细节更多,可能要more check一下你的代码。而对于holly底层的代码如果了解更清楚,你也可以在colly里实现出类似于scrapy中覆写类级别的代理扩展。
但是colly这个框架,相比于scrapy,在作为一个爬虫框架的完善性方面,我觉得还是有所欠缺的,一是文档的可阅读性和清晰度,另外一个是golang本身在传值和传值时候,想保留旧结构,但又要基于旧结构运算后以获得新结构,你要处理好新旧结构间数据的流转。
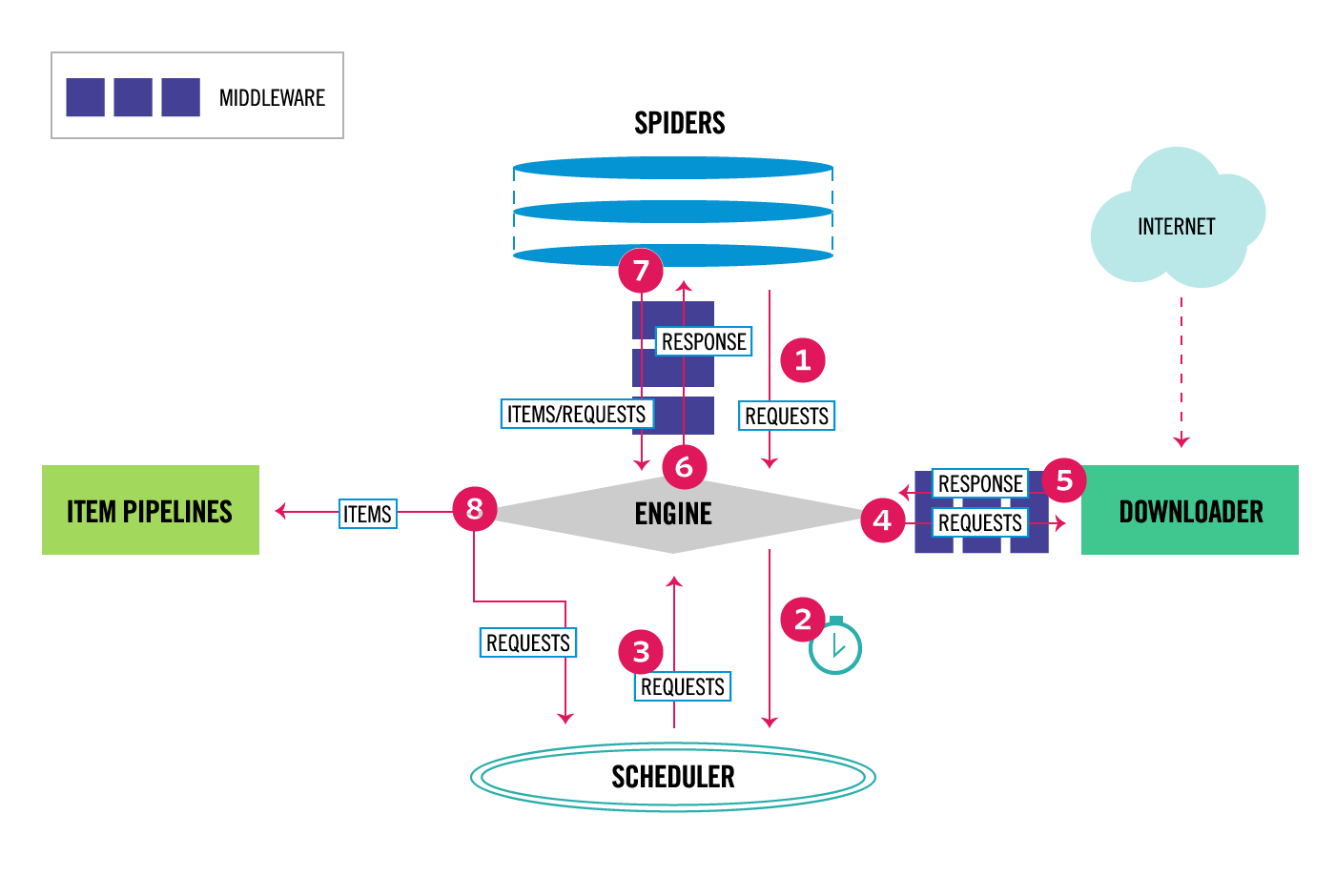
这是scrapy的架构图
- Engine获取爬虫要抓取的请求
- Engine在Scheduler中调度请求并请求抓取下一个链接
- Scheduler把下个请求返回给Engine
- Engine通过Downloader Middlewares把请求发给Downloader(主要用到函数process_request)
- 页面下载完(这里的下载是指页面dom解析可以放在内存被解析,注意跟图片下载有所区分),Downloader产生响应,并通过DownloadMiddleware连同page一同被送到Engine(主要用到函数process_response)。
- Engine收到Downloader响应过来的东西,再把它通过Spider Middleware发送到Spider做执行(主要用到函数process_spider_input)。
- Spider处理Response和返回的scraped item以及新的Request被通过Spider Middleware再次发到Engine做执行(主要用到函数process_spider_output)。
- Engine把执行完的Items发送给Item Pipeline,之后把执行完的Request送到调度器,同时挑可执行的next Request继续做抓取
- 流程周而复始(从步骤3)直接Scheduler没有可处理Request了,执行结束。
scrapy本身已经应用了很多设计模式,所以它的设计相对更符合现在软件设计的一些思想,而我用下来,感觉colly感觉更多有点面向过程的意思,main.go这个入口文件,是不是因为它是main所以它就很重,当然你完全也可以自己按需把它进行重整,丰俭由人!
colly闪亮登场从源码角度告诉你实现colly代理的几种方式以及最高效的方式是哪种">第三部分:主角colly闪亮登场,从源码角度告诉你实现colly代理的几种方式,以及最高效的方式是哪种
下面我们开始看可以用来给colly加代理的方式:
-
- 最基础也是最简单的方式就是直接用setProxy(),类比scrapy中最基础的方法
package main
import (
"bytes"
"log"
"github.com/gocolly/colly"
)
func main() {
// Instantiate default collector
c := colly.NewCollector(colly.AllowURLRevisit())
// 设置代理,与scrapy最简单的方式属实殊途同归了
c.SetProxy("http://proxy.example.com:8080")
...
// Request Page
c.Visit("http://httpbin.org/ip")
}
-
- 使用RoundRobinProxySwitcher,代理地址很多,甚至从文本文件中读取的时候使用的方式
package main
import (
"bytes"
"log"
"github.com/gocolly/colly"
"github.com/gocolly/colly/proxy"
)
func main() {
// Instantiate default collector
c := colly.NewCollector(colly.AllowURLRevisit())
proxyList := []string{
"http://Username:[email protected]:20000",
"http://Username:[email protected]:21000",
"http://Username:[email protected]:22000",
"http://Username:[email protected]:23000",
}
// Create Rotating Proxy Switcher
rp, err := proxy.RoundRobinProxySwitcher(proxyList...)
if err != nil {
log.Fatal(err)
}
// Set Collector To Use Proxy Switcher Function
c.SetProxyFunc(rp)
...
c.Visit("http://httpbin.org/ip")
}
-
- 使用代理API节点
package main
import (
"bytes"
"log"
"github.com/gocolly/colly"
"net/url"
)
func main() {
// Instantiate default collector
c := colly.NewCollector(colly.AllowURLRevisit())
...
// Create Proxy API URL
u, err := url.Parse("https://proxy.xx.xx/v1/")
if err != nil {
log.Fatal(err)
}
// Add Query Parameters
q := u.Query()
q.Set("api_key", "YOUR_API_KEY")
q.Set("url", "http://httpbin.org/ip")
u.RawQuery = q.Encode()
// Request Page
c.Visit(u.RawQuery)
}
-
- 自定义代理IP池
如果你使用过网上的一些免费的IP代理,你应该知道自己如果想高效使用这些免费代理,简单点你可以把这些地址抓下来写进一个文本文件,然后随机读取ip作为代理协助访问,但是这样做问题很明显,这些免费代理IP的质量差强人意,基本可用的很少,或者影响时间过长,所以如果你想高效用这些免费代理,你不可避免自己要着手搭建高性能的代理ip池,而要搭建这种池子,不可避免,你就需要对于所使用到的ip有效性有一套判断规则,即什么时候丢弃无效代理ip,如何有效控制有效ip的使用频次,使目标站点反爬机制不轻易识别出你,基于这些思考,所以我们要实现的自定义代理IP池也是基于这种思路进行构建的。但是额外说一句,免费的可能是最贵的,这么折腾下来,虽然你可能又是redis,又是数据库,能同步抓取目标站点提供的免费ip,但是能用的几乎一个都没有!!!所以这个问题最有效的方式还是充钱!!如果投入产出比很高或者预计很高,该花的钱是不能省的!
下面从源码角度挖掘如何实现的方案,c.Visit()是请求最核心的方法,追踪底层实现它的函数,我们会发现与请求相关能在请求中添加代理的关键函数有两个:一个是RoundRobinProxySwitcher,一个是SetProxyFunc,实现逻辑如下:
type ProxyFunc func(*http.Request) (*url.URL, error)
func (c *Collector) SetProxyFunc(p ProxyFunc) {
t, ok := c.backend.Client.Transport.(*http.Transport)
if c.backend.Client.Transport != nil && ok {
t.Proxy = p
} else {
c.backend.Client.Transport = &http.Transport{
Proxy: p,
}
}
}
func (r *roundRobinSwitcher) GetProxy(pr *http.Request) (*url.URL, error) {
index := atomic.AddUint32(&r.index, 1) - 1
u := r.proxyURLs[index%uint32(len(r.proxyURLs))]
ctx := context.WithValue(pr.Context(), colly.ProxyURLKey, u.String())
*pr = *pr.WithContext(ctx)
return u, nil
}
func RoundRobinProxySwitcher(ProxyURLs ...string) (colly.ProxyFunc, error) {
if len(ProxyURLs) < 1 {
return nil, colly.ErrEmptyProxyURL
}
urls := make([]*url.URL, len(ProxyURLs))
for i, u := range ProxyURLs {
parsedU, err := url.Parse(u)
if err != nil {
return nil, err
}
urls[i] = parsedU
}
return (&roundRobinSwitcher{urls, 0}).GetProxy, nil
}
代码逻辑还是比较简单的,你提供代理列表,并将ParseFunc函数作为返回值,这个函数作用是从给定的代理列表中随机选一个封装成url.URL。爬虫在运行期间,每个请求都会调用该函数生成代理,之后随着http请求一并发送。
所以要实现思路有了,就是我们也要实现出ProxyFunc这个函数,此时回味一下我刚才说的ip代理池的实现思路,要剔除掉无效的代理以及要可以控制使用代理的频次,不让自己暴露,触发目标站的Ban IP机制。这个实现思路让你类比到了一些什么?是不是有点LRU的味道,还有点优先级队列的味道,再进一步分析,LRU如果一个代理priority高,它会始终被使用,那样的话,不是直接暴露了,所以这是一个优先级队列的问题,有效的代理根据调用时间进行由远到近的优先级排序,如果最早被使用的代理ip跟当前使用时间又满足请求时间间隔,它就会封包到请求链接中,用做代理,协助完成请求。
优先级队列一搜网上golang代码一片一片的,随便找个改改,话说你晓得为啥优先级队列代码这么多吗?因为大厂面试题该类型出现频次很高,前30之内,所以如果你一点思路都没有,建议重点复习下。
type Proxy struct{
IP string
Port int
expireTime time.Time
lastCalledTime time.Time
}
type ProxyHeap []*proxy
func (h ProxyHeap) Len() int { return len(h)}
func (h ProxyHeap) Less(i,j int) bool {
return h[i].lastCalledTime.Before(h[j].lastCalledTime)
}
func (h ProxyHeap) Swap(i, j int) {
h[i],h[j] = h[j],h[i]
}
func (h *ProxyHeap) Push(x interface{}){
*h = append(*h,x.(*.Proxy))
}
func (h *ProxyHeap) Pop() interface(){
old := *h
n := len(old)
x := old[n-1]
*h = old[0:n-1]
return x
}
type ProxyPool struct{
proxies ProxyHeap
delay time.Duration
mu sync.Mutex
one chan string
}
func NewProxyHeap(delay time.Duration) *ProxyPool{
ch := make(chan string,0)
return &ProxyPool{
proxies: make(ProxyHeap,0)
delay: delay,
mu:sync.Mutext{},
one:ch,
}
}
func (p *ProxyPool) Add(proxy *Proxy){
p.mu.Lock()
defer p.mu.Unlock()
heap.Push(&p.proxies,proxy)
}
func (p *ProxyPool) GetProxy(ctx context.Context) error{
for {
select{
case <-ctx.Done():
return ctx.Err()
default:
for p.proxies.Len() == 0{
return errors.New("No valid proxy")
}
for p.proxies.Len() > 0{
if time.Now().After(proxy.lastCalledTime.Add(p.delay)){
proxyURL := fmt.Sprintf("http://%s:%d",proxy.IP,proxy.Port)
p.one <- proxyURL
proxy.lastCalledTime = time.Now()
heap.Pop(&p.proxies)
heap.Push(&p.proxies,proxy)
break
}else{
time.Sleep(proxy.lastCalledTime.Sub(time.Now()))
}
}
}
}
}
//如何在代码中使用呢?
func main() {
pool := NewProxyPool(2 * time.Second)
//我只是找了一个提供免费代理ip网站,下载了它们提供的txt格式文件,我本身也没打算采用这种方式,只是测试使用,因为我知道这种免费ip挺不靠谱的,还是得充钱。当然此处你也可以连mysql,redis,把免费ip代理站点的ip增量写进数据库,这边colly从数据库读取来使用,全自动化的流程就成形了
fi, err := os.Open("./http_proxies.txt")
if err != nil {
fmt.Printf("Error: %s\n", err)
}
defer fi.Close()
br := bufio.NewReader(fi)
for {
a, _, c := br.ReadLine()
if c == io.EOF {
break
}
final := strings.Split(string(a), ":")
ipAddress := final[0]
port := final[1]
var portInt int
if v, err := strconv.Atoi(port); err == nil {
portInt = v
}else{
panic(err)
}
fmt.Printf("####%v\n", ipAddress)
fmt.Printf(">>>>%v\n", portInt)
// fmt.Println(string(a))
pool.Add(&Proxy{
IP: ipAddress,
Port: portInt,
expireTime: time.Now().Add(30 * time.Second),
lastCalledTime: time.Now(),
})
}
go func() {
err := pool.GetProxy(ctx)
if err != nil {
fmt.Println("Error:", err)
}
}()
url := "https://httpbin.org/ip"
q, _ := queue.New(
1, // Number of consumer threads
&queue.InMemoryQueueStorage{MaxSize: 10000}, // Use default queue storage
)
c := colly.NewCollector()
c.AllowURLRevisit = true
c.SetProxyFunc(pool.ProxyFunc)
...
c.Visit('xx')
}
这里说下关键点,我们为什么要使用sync.Mutex?为了避免构建代理ip列表时,重复操作同一资源,虽然不够优雅,也应该用channel来做,但是这只是处理个简单列表,也没必要搞那么复杂。为什么要使用channel?我们知道这是一种golang中并发协程时一种加锁的机制,它是数据通信的桥梁,且本身是线程安全的,所以引入它它的目的是实现对访问时间间隔的限制,也就是说如果你不用channel机制的话,你硬性设置前后次请求的间隔时间,会导致可能你永远没拿到有效代理ip情况下,你程序实际就在那空跑,在那浪费资源,而我们加上channel就是让request直接到拿到有效代理ip才执行,如无有效代理,就将程序阻塞住,这样不会空跑,也就不会浪费带宽,浪费机器性能。
当然这个优先级队列你完全也可以用redis来实现,那队列就是现成的,proxyHeap你就不用自己实现了,你只要从redis里往出get*东西,再加个重试机制,满足时间间隔且用来做请求,如果请求成功就换下个链接,否则针对这个链接就不断换代理重试,实在取不到了,记录需要补充执行的记录逻辑。
colly可以分布式运行">第四部分:聊点杂的,如何应用布隆过滤,如何让colly可以分布式运行
关于布隆过滤,相信有过爬虫实操经验的都不陌生,golang中其实用内置结构bit也是可以实现布隆过滤的,但是没必要,都放到内存里搞,内存就是瓶颈。所以还是把redis搞进来,这里我使用的方式是redis提供的BloomFilter模块,直接把它的bin执行目录配置到redis.conf中,然后重启redis指定这个模块的位置,同时指定配置文件的位置,这样redis就支持了一种新的BloomFilter的数据结构,单机执行,电脑性能也足够强,站点数据量不大,所以没有具体体会,但是如果是抓取千万级别以上的数据量,就要注意碰撞问题了。
再说一说分布式的问题,由于colly的设计之初就是基于单机的:
q, _ := queue.New( 2, InMemoryQueueStorage{MaxSize: 10000},)
所以与scrapy又殊途同归了,要实现分布式,你要么,自己实现爬虫执行引擎(列表抓取器、详情抓取器、图片抓取器)、调度器(受控于引擎,传导链接)、存储器(mysql、mongo、图片等落库、落盘)等。要么,就用redis。把抓取链接都堆到里面,此时你消费redis,无论用colly,用scrapy亦或是node系的puppeteer等都请自便了!
好了,今天这篇有关colly的大杂烩文章就分享到这里了,希望你能有所收获!
如果你有志于业务开发,想提高自己的技术实力,欢迎加入我的课程: 彻底学会python&golang系统化课程,直播授课,课堂答疑,课后1对1指导,我将从算法、web应用、爬虫等不同的角度,帮助你夯实你开发知识的同时掌握最具实践的python&golang,并将java的对比及设计模式等贯穿在整个教学过程中,让你在激烈的竞争中更容易脱颖而出。
如果你对云原生感兴趣,想提高自己的技术实力,欢迎加入我的课程: 架构师云原生强化课程,直播授课,1对1指导,我将从实践的角度,帮你了解一步步实现一个高可用的云原生系统涉及的方方面面,帮助你夯实你kubernetes相关知识的同时,对于网络底层的东西有前所未有的认知改变,让你在激烈的竞争中更容易脱颖而出,从此从容面对各种各样的业务场景 。
如果你对于油管运营,自动化生产视频感兴趣,欢迎联系我定制视频,我也收自动化生产视频全流程商业化方向的徒弟,介绍链接见:全自动化批量生产视频课程&适配环境入场部署方案有兴趣也欢迎联系!
差不多再有2个月左右,这个油管channel就可以开通收益权限,赚美刀了
这个应该这个月之内,就应该可以达到开通收益权限赚美刀了


