劲爆!抖音2周涨粉到10000!教你如何用Puppeteer抓取到的抖音数据科学投抖加!
我上次的文章已经提及了我面临的问题:要投放抖加,但是手上没数据,所以没法很高效的找相似账号。这篇文章就把自己通过使用puppeteer抓取pc版抖音相关关键字下面的用户,从而方便筛选粉丝量在10-30万之间,并且涨粉周期是在最近1~3周内的puppeteer使用经验跟大家分享一下。本文会分为以下三部分,第一部分主要讲一些宏观的,如果你想将自己的puppeteer爬虫大规模应用或做分布式部署,我个人的一些思考。第二部分会讲我在开发这个基于puppeteer的抖音爬虫过程中遇到的一些问题及解决方案。第三部分会把puppeteer和playwright及python系一些爬虫,假如来做同样一件事的一些优劣势进行一下对比,方便你在自己项目中使用时,能更精准的选型。
puppeteer应用或者实现其分布式部署">第一部分:如何高效部署自己的puppeteer应用或者实现其分布式部署
-
- 首先明确自己的技术选型及对于后期的扩展
比如说如果你只是临时使用,只想找到一些相似的账号,就没必要把这个爬取功能架构搞的很复杂,做成分布式,数据库应用布隆过滤啥的来去重,支持增量抓取。因为我目前的需要只是大致看下数据,再手动看下账号内容是否符合我投相似账号的标准,所以我这个版本没有做成分布式。

抓取下来的数据,直接写到了文本文件中
由于目前基础的功能已经具备,我有在考虑要不要做一个属于自己的数据分析平台,只做精细化的我所属于行业的数据分析平台,如果有了这样的目的,为了配合这个目的,就需要对于puppeteer整体的部署方式,抓取性能,数据存储,数据展现等方面做全新的评估分析,以确定最终的方案。
puppeteer并行服务的方式">先说一些可以通过简单扩展,以达到让puppeteer并行服务的方式
-
- 最简单的把要处理的url放在loop中,这样可以在浏览器的各新开tab中轮次执行,但是这种性能提升的有限,运行过程由于是阻塞的,限制了内存和cpu的使用,但由于运行的各任务是独立的,所以可以缩减总体的运行时间,如果中间哪次执行出错,会导致内存泄露。
const browser = await puppeteer.launch({/* ... */});
const urls = [/* ... */];
const results = [];
for (const url of urls) {
const page = await browser.newPage();
await page.goto(url);
// run test code
const result = ...;
results.push(result);
await page.close();
}
await browser.close();
-
- 利用异步处理模式来编排资源,可以让浏览器和请求页面的运行更可靠,也是我们编写node程序中常用的手段,即
async ...await方式,把构造浏览器对象和构造请求页面方法抽象成函数,方便browser资源的共享以及请求页面的复用,各page异步请求,不会形成阻塞,提高了性能。
- 利用异步处理模式来编排资源,可以让浏览器和请求页面的运行更可靠,也是我们编写node程序中常用的手段,即
const withBrowser = async (fn) => {
const browser = await puppeteer.launch({/* ... */});
try {
return await fn(browser);
} finally {
await browser.close();
}
}
const withPage = (browser) => async (fn) => {
const page = await browser.newPage();
try {
return await fn(page);
} finally {
await page.close();
}
}
const urls = [/* ... */];
const results = [];
await withBrowser(async (browser) => {
for (const url of urls) {
const result = await withPage(browser)(async (page) => {
await page.goto(url);
// run test code
return ...;
});
results.push(result);
}
});
-
- 以串行的方式运行,就是把上述的
for ... loop循环的方式,用Promise.all函数来替代,由于Promise.all天然就以数组映射的方式处理逻辑,也以数组方式返回结果,你就省去了自己维护返回结果的步骤,也省去了上面为每轮循环引入变量收集值的步骤。
- 以串行的方式运行,就是把上述的
缺点也很明显,并行嘛,每个请求地址都会在浏览器里开一个新Tab,这是相当耗费内存的,同时打开所有链接地址,那处理的url地址越多,内存消耗越巨大,RAM会被迅速消耗,操作系统可能就完全终止了(OOM Killer原因),即使没崩,也会由于资源不断的交换使整个抓取过程效率越来越低。
const results = await withBrowser(async (browser) => {
return Promise.all(urls.map(async (url) => {
return withPage(browser)(async (page) => {
await page.goto(url);
// run test code
return ...;
});
}))
});
// starting url1
// starting url2
// starting url3
// url1 finished
// url3 finished
// url2 finished
所以,我们的目的应该是即可以享受并行的好处,又能有效控制并行对资源的消耗,真正在整体上提升系统的运行性能,所以就有了下面的方式。
-
- 使用
Bluebird提供的Promise.map方法,它支持对于并发数量的控制,也就是你可以自定义在一个串行进程里多少任务被执行,当前一个消费完成以后再启用新的,好处与Promise.map对处理结果的返回都是自身集成的,不用人工干预,同时在不拖垮机器的前提下,最大可能发挥机器性能。
- 使用
const bluebird = require("bluebird");
const results = await withBrowser(async (browser) => {
return bluebird.map(urls, async (url) => {
return withPage(browser)(async (page) => {
await page.goto(url);
// run test code
return ...;
});
}, {concurrency: 3});
});
// starting url1
// starting url2
// starting url3
// url1 finished
// starting url4
// url3 finished
// starting url5
// url2 finished
// url4 finished
// url5 finished
-
- 上面方式的另一种替代方案,
RxJs的mergeMap方法,唯一区别是上面方法直接返回数组形式,这个因为是元素流处理方式,所以你需要用toArray函数做一下转化。
- 上面方式的另一种替代方案,
const rxjs = require("rxjs");
const {mergeMap, toArray} = require("rxjs/operators");
return rxjs.from(urls).pipe(
mergeMap(async (url) => {
return withPage(browser)(async (page) => {
console.log(`Scraping ${url}`);
await page.goto(`${host}/${url}`);
const result = await page.evaluate(e => e.textContent, await page.$("#result"));
console.log(`Scraping ${url} finished`);
return result;
});
}, 3),
toArray(),
).toPromise();
// starting url1
// starting url2
// starting url3
// url1 finished
// starting url4
// url3 finished
// starting url5
// url2 finished
// url4 finished
// url5 finished
// [url1, url3, url2, url4, url5]
-
- 上述方法存在一个弊端,就是返回值是乱序的,不是以处理数据的顺序来返回数据,此时需要用到
orderedMergeMap函数。
- 上述方法存在一个弊端,就是返回值是乱序的,不是以处理数据的顺序来返回数据,此时需要用到
return rxjs.from(urls).pipe(
orderedMergeMap(async (url) => {
return withPage(browser)(async (page) => {
console.log(`Scraping ${url}`);
await page.goto(`${host}/${url}`);
const result = await page.evaluate(e => e.textContent, await page.$("#result"));
console.log(`Scraping ${url} finished`);
return result;
});
}, 3),
toArray(),
).toPromise();
// starting url1
// starting url2
// starting url3
// url1 finished
// starting url4
// url3 finished
// starting url5
// url2 finished
// url4 finished
// url5 finished
// [url1, url2, url3, url4, url5]
-
- 如果不想自己来实现,可以用成熟的
package,比如说puppeteer-cluster,可以指定并发主进程的数量,并等待执行完成,进行下一轮次
- 如果不想自己来实现,可以用成熟的
const { Cluster } = require('puppeteer-cluster');
(async () => {
const cluster = await Cluster.launch({
concurrency: Cluster.CONCURRENCY_CONTEXT,
maxConcurrency: 2,//指定并发的主进程(工作进程)数量
});
await cluster.task(async ({ page, data: url }) => {
await page.goto(url);
const screen = await page.screenshot();
// Store screenshot, do something else
});
cluster.queue('http://www.google.com/');
cluster.queue('http://www.wikipedia.org/');
// many more pages
await cluster.idle();
await cluster.close();
})();
-
- 以上也可以看得出,基本来解决的都是单台机器上最大化性能的方式,假如执行性能不是瓶颈,那也就是如何尽快把抓取链接全部消耗完的问题,这个就是个充钱的问题了,有钱就多上机器,就是这么直观暴力。
这也几乎是所有分布式系统的部署的通用解决方案了。比如我在使用golang做分布式爬虫的时候,我的经验就是你要抽象出不同的服务,特定服务只做特定的事。比如说可以抽象出专门抓取链接的爬虫,把所有抓取到的链接都统一提交到某个rpc服务地址上,由抽象出的调度中心,专门用来调度抓取详情的爬虫,有效将这些链接源源不断分配给这些业务爬虫,这些业务爬虫只负责抓取界面详情,但是不做写库等操作,专门抽象出用于存储目的rpc服务,专门接收业务爬虫爬到的详情数据进行入库,这样一来,哪个环节薄弱,或者资源调用不均衡,就可以往哪里加强。比如说原来开了三台机器,专门用来爬取链接,但是运行一段时间发现,这三台链接抓取链接的速度太快了,后面详情爬虫的消费能力完全不匹配,这个时候,你就可以调整,让抓取链接的爬虫减少为两台,另外一台也部署成业务爬虫,用这种方式来整体提高爬虫集群的性能。
puppeteer抓取抖音数据时遇到的问题及解决方案">第二部分:使用puppeteer抓取抖音数据时遇到的问题及解决方案
-
- 切记切记,如无必要,勿增实体
这是“奥卡姆剃刀”的原理,尽量把事情搞简单,不要人为复杂化。我开始的时候就在这方面浪费了一些时间。因为我无意中发现了一个对于puppeteer的交互机制做了进一步封装的很好用的包,叫做expect-puppeteer,再看样例的时候,它有个函数叫做expect可以帮你自动解决一些puppeteer中wait*式等待dom节点加载完毕的操作,而且这个扩展package已经非常成熟,所以我心心念念想把它应用在自己项目里,但是国内一些帖子里面,这个expect关键字,最常出现的讲解场景,就是jest单元测试框架时面,这就导致我把应该聚集的在puppeteer上的精力,分散到了又部署puppeteer,又部署jest(我前面文章有提及过),最终单元测试框架部署完成,也把puppeteer整合了进去,但是这个隶属于jest的expect关键字非我初衷想使用的expect,所以一直运行不成功,甚至一度想放弃。后来果断弃用jest,只聚集在puppeteer的使用上,开发在步入正轨,这其间浪费了一些时间,虽然说对于jest框架的使用也算是经验的成长,但是其实与我需要迅速完成相似账号数据的抓取,这个初衷背离甚远,所以,希望大家在有目的做事情的时候,一定要“如无必要,勿增实体”。
- 对于抖音这种平台,应该是有相应的数据安全部门,所以对于数据抓取的防范做的十分严格。所以抓取的时候,不能频次太高,每次请求之间要有时间间隔,要浏览器换头,但是这些本质上都是临时解决方案,最终还是要做代理ip池。
现在免费的代理ip汇总地址上抓取回来能用的寥寥无几,所以还是要购买付费隧道代理。隧道代理说白了,就是在链接交互的入口就把针对ip的监控及防爬策略给解决掉了,只只需要配置一个地址,代理ip池就可以生效了,相当于把防爬的业务逻辑前移了,转嫁给ip代理服务商了,你只需要专注在业务逻辑上就可以了,不然你还要有一套ip代理的维护策略,以保证ip代理的高效且稳定。
const browserConfig = {
args: [
...
//设置HTTP隧道服务地址
'--proxy-server=xxxxxx:xxxx'//ip代理商给你的地址
...
],
};
const options = {
...
browserConfig,
...
};
;(async () => {
try {
const browser = await puppeteer.launch(options);
...//业务代码
})();
-
- 对于
userDataDir的设置,我在上篇文章中已经有讲过了,这次抓取抖音,感受更深了,一定要配置。
- 对于
比如mac上,cookies之类保存位置是:'/Users/guruyu/Library/Application Support/Google/Chrome/Default'
const options = {
...
userDataDir: '/Users/guruyu/Library/Application Support/Google/Chrome/Default',
...
};
;(async () => {
try {
const browser = await puppeteer.launch(options);
...//业务代码
})();
由于抖音未登录用户,限制了查看数据的条数,所以你必须登录,所以还是要操作登录表单那些东西,但是成功登录之后,cookies就被缓存下来了,下次就不必再操作表单进行登录了,由于我用的是本机chrome浏览器,所以我的配置地址像上面这样,如果你使用的是puppeteer,它自带了chromium,这个时候你可能就要找到它默认配置的存放位置进行指定,这里还是建议使用puppeteer-core,然后再操作系统自带chrome浏览器,这样不需要考虑版本的问题,也不需要特别针对chromium的维护,而且系统上安装进这个还增添了硬盘负担。
-
- 对于页面div元素点击,及弹出窗口的tab点击,我用div选择器都没生效,最后使用的都是xpath选择器结合着文本选择器共同使用
由于我是要抓取特定领域的用户,而抖音用户搜索中就包含了用户名中包含关键字,简介中包含关键字,由于我只是想找符合我既定条件的相似账号,所以我采用了用关键字搜索用户的操作,由于未登录,所以自动下拉一屏二屏就弹出要点击登录,点出弹出窗口之后,有三种登录方式,我要切到密码登录,用如下方式来处理。
const scrollable_section = 'text/登录后可查看更多精彩视频';
await page.waitForSelector(scrollable_section, {timeout: 0}).catch(error => console.log('failed to waitfor the selector'));
const [button] = await page.$x('//*[@id="douyin-right-container"]/div[5]/div/div[7]/div[3]/div/div/div[2][contains(.,"登录")]');
弹出窗口中tab切换的处理逻辑类似。
-
- 针对于登录弹窗的处理,一定要加
waitForSelector处理,也就是等dom节点加载完毕再做表单处理,不然或者会出现节点定位超时,或者是出现找不到节点的报错
- 针对于登录弹窗的处理,一定要加
if (newPage) {
await newPage.waitForSelector('.web-login-normal-input__input');
await newPage.type('.web-login-normal-input__input', '18996125721');
...
}
-
- 针对于滚动下拉的业务逻辑
这个网上有很多实现的方式,基本都是使用setInterval定时器,100ms滚一次,再针对于对已抓取到的数据的处理逻辑,实现相应的方法,比如是写文件,还是存储数据库。这与很多带翻界网站抓取的最大区别就在于,你没有界面范围,你定义的函数的作用域范围是在node上下文之内,而puppeteer运行起来以后,作用域范围是浏览器的console中,所以,你打算在自动滚动函数里面加业务代码做写文件、写库操作,你会发现都是不管用的,你需要的是把puppeteer作用域内获取的数据回流到node作用域内,才能做写库操作、写文件操作,但是下拉滚动你又找不到截止点,我这里提供一个思路,就是人为指定一个clientHeight的最大高度,越大越好,然后用它来除每屏的高度,以此来形成循环。由于我目前已经达到抓取目的,这里没有再深究,后续如果有更好的方案,我再分享了出来。
puppeteer与playwright及python系如scrapy等爬虫技术的对比">第三部分:puppeteer与playwright及python系,如scrapy等爬虫技术的对比
由于playwright只跑了个demo,用node就把手上活干完了,所以这里对于playwright的理解可能个人色彩比较浓。对于python系的爬虫,不说框架,只说常用的packages,像requests、beautifulsoup、selenium、urllib等这些我都使用过。而框架范围内,像成熟的scrapy我的使用经验最为丰富,我的所有站点的内容,图片资源等,如果有需要,我都用它来帮助解决,所以我对它和puppeteer对比下的理解应该是相对客观和有一定借鉴性的。
如果你只是抓一些界面上的内容之类的,不涉及到交互或者对js等文件进行执行,那scrapy应该是更好的选择,因为业务生态已经比较成熟,拓展成分布式也很简单,官方文档也很齐全,如果对于python有一定了解的话,也容易上手。针对于涉及到界面交互,或者涉及到要触发js才能有效获得数据的交互,scrapy也不是不能做,并且也因此衍生出了很多解决方案,比如我之前分享的用selenium,用PhantomJs、分析界面加载时js流转从而找到有效执行的二封引擎及执行函数,用execjs来做触发,及puppeteer诞生之后,发包出的Pyppeteer,但是都由于种种原因,这些都由于这样那样的原因,逐渐再淡出历史的舞台。比如我前面分享过的由于最开始selenium与chromium版本的问题,花了好多时间都没配置好,这是很不友好的,等同于你在非必要的问题上浪费了很多时间,python2的编码问题类似,也因此颇受诟病。像execJs,我之前抓取某个国外站点,这需要你非常的耐心,能够对javascript做debug过程有清晰的理解,把界面dom元素间的联动关系、触发原理有着深刻的理解,才能找到有效的执行步骤,然后用python构建出这样的执行步骤,才有可能抓到数据,对于有些加密甚为严格的站点,你不是只有研究出执行步骤就能解决问题,页面中很多节点的函数值,都是经过了加密算法的混淆,甚至是js运行时构建出了类似于执行引擎的小生态,相当于操作系统层面又做了二次加密,对于这种加密机制的破译,可以反编译出来几乎短时间内是不可能的。而像Pyppeteer,我上篇文章也做过分析,由于不是官方的发包,所以会出现莫名其妙的bug,现在似乎也不维护了,所以,某种层面scrapy确实不适合我陈述的以上场景上来使用,有点事倍功半。
而puppeteer恰恰解决了这些问题,直接用浏览器,模拟人的操作,这是任何反爬手段都无法杜绝的。playwright由于是官方开发原生支持python,所以如果有python经验,肯定更容易上手。而puppeteer只支持谷歌家自己的浏览器,playwright由于是微软开发,又已经在puppeteer成熟后又做了革新,无论团队能力、公司实力、还是基于事物发展的普遍原理,它都没理由不比puppeteer强,我看文档,有个操作录制的功能,指定生成出文件的位置,你操作,他捕捉你的“手势”直接就把代码写好了,这想想就很香了,至于更深刻的体验,只有等使用之后,才有发言权了。
好了,今天这篇有关puppeteer抓取抖音数据,算是puppeteer的一次深度使用的帖子到这里就结束了,做下总结。puppeteer是基于node开发的,所以node系能提高性能的手段在它上面同样适用,所以第一部分,针对改造你的puppeteer让它高性能、甚至部署成为分布式,我分享了9种方式,相信随着你业务的深入,可能有些方案不准就用得上了。第二部分,分享了我在抖音用户数据抓取过程中趟的一些坑,如果你有类似需求,可以借鉴一二,没准会少走一些弯路。第三部分,分享了自己对于puppeteer、playwright、scrapy自己的一些理解,属于一家之言,但是算是scrapy的深度用户,所以应该可以对你的业务选型有一定的启发作用。
最后再打个广告,自己在量产短视频平台如抖音、快手、bilibili、youtube等平台的视频,与设想一致,由于独特的剪辑手法,所以视频在这些平台都很受欢迎,自己的西瓜视频也参与了中视频计划,用了不到四天的时间就突破了17000的播放量,进入了审核状态。首先让大家一起来欣赏一下这番操作下来的战果,基本用时5天达到初始账号超过了96%的同类创作者(这句是抖音创作者平台的统计数据)。

2023.03.03数据|抖音效果
2023.02.28数据|微信视频号数据,大概发了7天,30多个视频吧,周末的时候给推了流,数据就出来了
2023.02.28数据|微信视频号数据,大概发了7天,30多个视频吧,周末的时候给推了流,数据就出来了
2023.02.28数据|微信视频号给推流后的播放量,之前一直500左右
2023.02.28数据|抖音同样,大概发了7天,30多个视频吧,周末的时候给推了流,之前一直跑500的初始流量左右,然后就爆到1000~2000区间了
抖音同样,大概发了7天,30多个视频吧,周末的时候给推了流,之前一直跑500的初始流量左右,然后就爆到1000~2000区间了
2023.02.28数据|西瓜视频,2023年2月23号开始发,前面3天一天10~20个,后面几天一天20个,就过了中视频计划17000的门槛
2023.02.28数据|2023年2月23号开始算,到27号下午收到满足17000审核门槛通知,90多个视频,用时4天多一点

2023.02.28数据|这是西瓜视频后台对我的视频的数据统计,可见效果是相当不错的
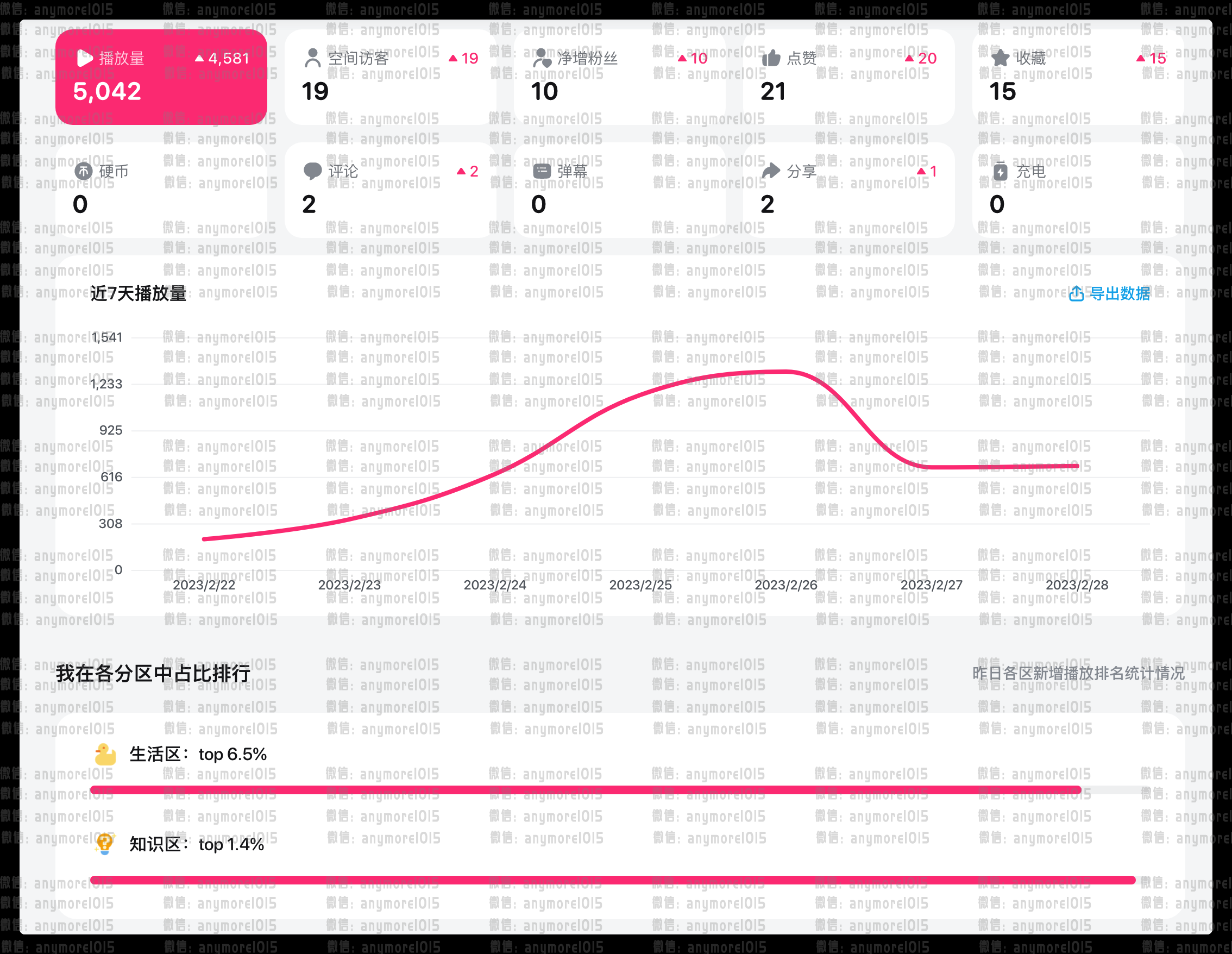
2023.02.28数据|bilibili的后台数据
所以,你有视频订制的需求,欢迎联系我。




{kind=link}