写了这么多golang程序,我来给出一些针对于使用golang的并发性和并行性特征来提高系统性能的专业性建议
关于人类的认知能力,很少有概念像“多任务处理”一样引起如此多的争议。多任务处理需要大量的认知处理,并允许人类同时利用记忆储备并投射到未来。然而,多任务处理的想法引发了争议,其中一种观点认为这是一项人类的壮举,使我们与所有其他动物分开,而另一种观点则认为人脑无法同时执行多个高级脑功能。
然而,科学无疑已经证明,人类确实有能力迅速在任务之间切换,并成功地从一个事物转移到另一个事物。
多任务处理在计算机中扮演了类似的角色,但具有不同的名称 - 并发和并行处理。
并发和并行处理
在软件开发中,多线程应用程序通常需要并发和并行处理。了解这两个过程之间的重要但微妙的区别非常重要。例如,考虑一个建造汽车的团队的隐喻。
对于并发,您可以有多名工人为汽车构建不同的部件,但他们共享一个组装部件的公共工作台。同时只有一名工人可以在工作台上进行组装,因此当一名工人在工作台上进行组装时,其他工人在后台操作他们的零件。并行处理则使用多个工作台,工人可以同时在不同的工作台上组装部件。
golang和并发性">Golang和并发性
作为一个普遍的概念,Go社区广泛使用并发性。实现Go并发的关键是使用 Goroutines - 轻量级、低成本的方法或函数,它们可以与其他方法和函数并发运行。
Golang在其基础中提供了特定的 CSP(Communication Sequential Processes)范例,利用Goroutines方便地进行并行处理,以促进代码的并发执行。它有效地充当一个“调度程序”,将固定数量的系统线程映射到可能无限数量的Goroutines来执行。
这对开发人员意味着什么?您可以编写可并发执行的代码,该代码可以由计算机的不同核心并行执行或按顺序执行,具体取决于Go调度程序的运行时。
在Golang中,通常通过Go通道在Goroutines之间交换数据以实现并发。但是,开发人员如何组织代码以使其内部一致且不具有竞态条件呢?在本文中,我将描述我在做了若干个Golang项目被我广泛使用的一些模式,用于在微服务中并行处理数据。
通常,我们使用算法并行化或数据并行化来利用托管计算机的多个处理器核心,并加快计算速度。
算法并行化
算法并行化意味着程序包含可以独立执行的不同阶段。在大多数情况下,一个阶段依赖于另一个阶段或该阶段产生的数据。一个有用的例子是计算和传输任务。在代码中,计算任务不应该被传输任务阻塞,因此最好同时运行它们。通常,我们使用以下模式来关联和运行任务:
package main
import "fmt"
type Figure struct {
Length int
Width int
Square int
}
const n = 2
func main() {
ff := []Figure{Figure{1, 2, 0}, Figure{3, 2, 0}, Figure{1, 10, 0}}
squarec := make(chan Figure, n)
go func() {
computeSquare(ff, squarec)
}()
send(squarec)
}
func computeSquare(ff []Figure, squarec chan<- Figure) {
for _, f := range ff {
f.Square = f.Length * f.Width
squarec <- f
}
close(squarec)
}
func send(sourcec <-chan Figure) {
count := 0
batch := make([]Figure, 0, n)
for f := range sourcec {
batch = append(batch, f)
count++
if count == n {
// imitate sending batch
fmt.Println(batch)
batch = make([]Figure, 0, n)
count = 0
}
}
// imitate sending rest
fmt.Println(batch)
}
首先,我们运行计算图形平方的例程(go routinue)computeSquare。然后我们运行发送任务。当我们完成数据计算时,我们使用squarec关闭通信通道。当所有数据都从通道接收并通道关闭时,数据传输完成。
我们应该为通道squarec := make(chan Figure, n设置什么大小的缓冲区?这主要取决于传输机制。如果数据的发送是定期逐个进行的,则使用缓冲区没有意义。如果数据以批量方式发送,因此传输会收集一批数据然后再发送它们,则应该将n = batchSize。此外,如果我们想调查哪个任务需要最长时间 - 数据计算还是传输,则有n> 0是有意义的。
选择所需的缓冲区大小后,我们可以使用块分析器运行代码。如果带有缓冲区的通道仍然被阻塞,则数据传输速度比计算速度慢。另一方面,如果计算速度较慢,我们仍然可以对其进行优化,以使整个过程更快地运行。
请注意,应该由负责向通道发送数据的组件(函数computeSquare)始终关闭通道。这样,我们就永远不必担心在尝试向其发送数据时关闭通道。
如果我们想要并行化的子任务存在链式结构,则我们希望以类似的方式将它们放入链中:
package main
import (
"fmt"
)
type Figure struct {
Length int
Width int
Height int
Square int
Volume int
}
const n = 2
func main() {
ff := []Figure{
Figure{1, 2, 5, 0, 0},
Figure{3, 2, 4, 0, 0},
Figure{1, 10, 3, 0, 0}}
squarec := make(chan Figure, n)
volumec := make(chan Figure, n)
go func() {
computeSquare(ff, squarec)
}()
go func() {
computeVolume(squarec, volumec)
}()
send(volumec)
}
func computeSquare(ff []Figure, squarec chan<- Figure) {
for _, f := range ff {
f.Square = f.Length * f.Width
squarec <- f
}
close(squarec)
}
func computeVolume(squarec <-chan Figure, volumec chan<- Figure) {
for f := range squarec {
f.Volume = f.Square * f.Height
volumec <- f
}
close(volumec)
}
func send(sourcec <-chan Figure) error {
count := 0
batch := make([]Figure, 0, n)
for f := range sourcec {
batch = append(batch, f)
count++
if count == n {
// imitate sending batch
fmt.Println(batch)
batch = make([]Figure, 0, n)
count = 0
}
}
// imitate sending rest
fmt.Println(batch)
return nil
}
这样,计算阶段computeSquare和computeVolume都可以与数据发送任务同时运行。很多时候,计算可能会失败,在这些情况下,代码应提供一种返回错误代码并停止处理的方法。如果每个任务都返回一个错误,我们的代码会是什么样子?
package main
import (
"fmt"
"sync"
)
type Figure struct {
Length int
Width int
Height int
Square int
Volume int
}
const (
n = 2
statusOK = 0
statusError = 1
)
func main() {
errc := make(chan error)
status := statusOK
errGroup := sync.WaitGroup{}
errGroup.Add(1)
go func() {
for err := range errc {
status = statusError
fmt.Printf("error processing the code: %s\n", err)
}
errGroup.Done()
}()
ff := []Figure{
Figure{1, 2, -5, 0, 0},
Figure{3, 2, 4, 0, 0},
Figure{1, 10, 3, 0, 0},
Figure{1, 10, -3, 0, 0},
Figure{-1, 10, 3, 0, 0},
Figure{1, 10, 3, 0, 0}}
squarec := make(chan Figure, n)
volumec := make(chan Figure, n)
go func() {
computeSquare(ff, squarec, errc)
}()
go func() {
computeVolume(squarec, volumec, errc)
}()
send(volumec, errc)
close(errc)
errGroup.Wait()
}
func computeSquare(ff []Figure, squarec chan<- Figure, errc chan<- error) {
for _, f := range ff {
if f.Length <= 0 || f.Width <= 0 {
errc <- fmt.Errorf("invalid length or width value, should be positive non-zero, length: %d, width: %d", f.Length, f.Width)
}
f.Square = f.Length * f.Width
squarec <- f
}
close(squarec)
}
func computeVolume(squarec <-chan Figure, volumec chan<- Figure, errc chan<- error) {
var err error
for f := range squarec {
if f.Height <= 0 {
err = fmt.Errorf("invalid height value, should be positive non-zero, height: %d", f.Height)
errc <- err
}
// skip if error happens during previous figure calculation
if err == nil {
f.Volume = f.Square * f.Height
volumec <- f
}
}
close(volumec)
}
func send(sourcec <-chan Figure, errc chan<- error) {
var err error
count := 0
batch := make([]Figure, 0, n)
for f := range sourcec {
if f.Volume > 25 {
err = fmt.Errorf("cannot send figures with volume more than 25, volume: %d", f.Volume)
errc <- err
}
// skip if error happens during sending
if err == nil {
batch = append(batch, f)
count++
if count == n {
// imitate sending batch
fmt.Println(batch)
batch = make([]Figure, 0, n)
count = 0
}
}
}
if err == nil && len(batch) != 0 {
// imitate sending rest
fmt.Println(batch)
}
}
这段代码变得稍微有些复杂。首先,我们需要引入一个额外的用于错误errc的通道和一个新的Goroutine来从通道中读取错误。然后我们需要使用errGroup waitgroup,以允许在检索并打印所有错误后优雅地关闭代码。当我们在main函数结尾处关闭错误通道时,它会发生。
还请注意,computeSquare仅在遇到错误时才存在,但是computeVolume继续在输入通道squarec上循环,否则computeSquare将无法写入通道。因此,computeVolume独立于阶段中的错误从通道squarec读取所有数据。发送任务也是如此 - 尽管发送错误,它仍然从输入通道中读取所有传入数据。
数据并行化
第二种并行化代码的方式是通过数据来完成。当我们有一个输入数据数组时,并且数据项可以独立处理时,就会发生这种情况。它们不依赖于彼此或相关。实现数据并行处理的最简单方法是使用sync包中的WaitGroup。
然而,让我们考虑一下在处理数据时计算步骤可能返回错误的情况。对于这种情况,有一个标准机制-errgroup包中的Group:https://godoc.org/golang.org/x/sync/errgroup。 我们将在本文开头的上一个示例基础上使其更加复杂,并除了算法并行处理外还进行数据并行处理。本质上,我们将同时使用Goroutines计算体积和平方,并并行发送结果回来。
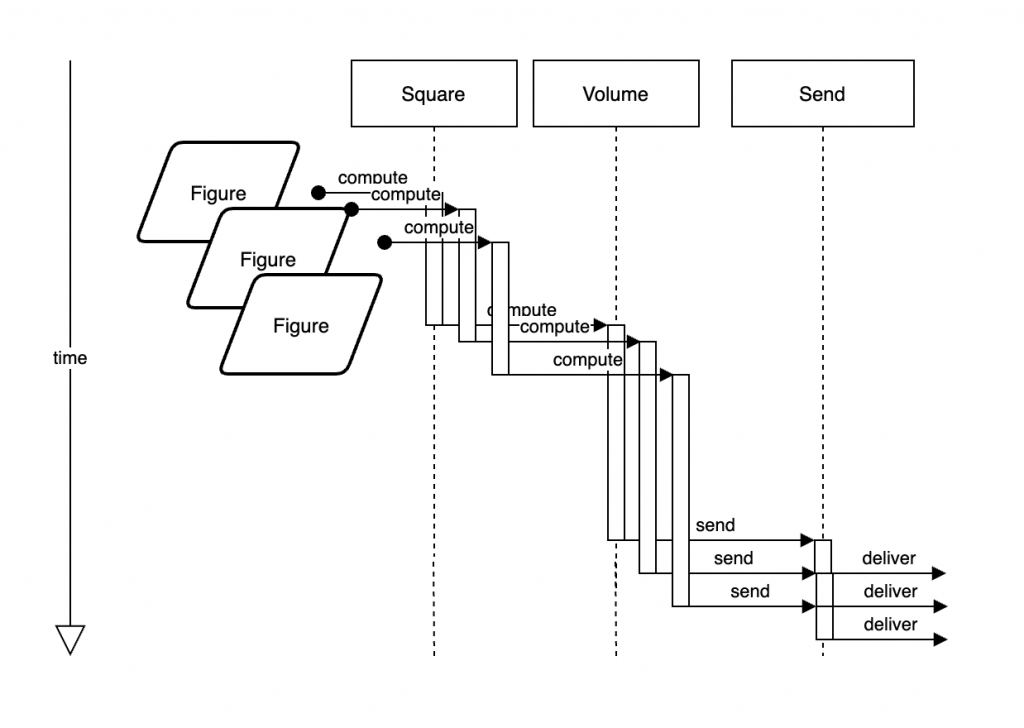
在先前的示例中,我们同时执行了Square、Volume和Send函数;但是,在Square和Volume步骤中,数据是逐个迭代和处理的。现在,我们将同时处理每个Figure。
这是它之前是如何执行的流程图:
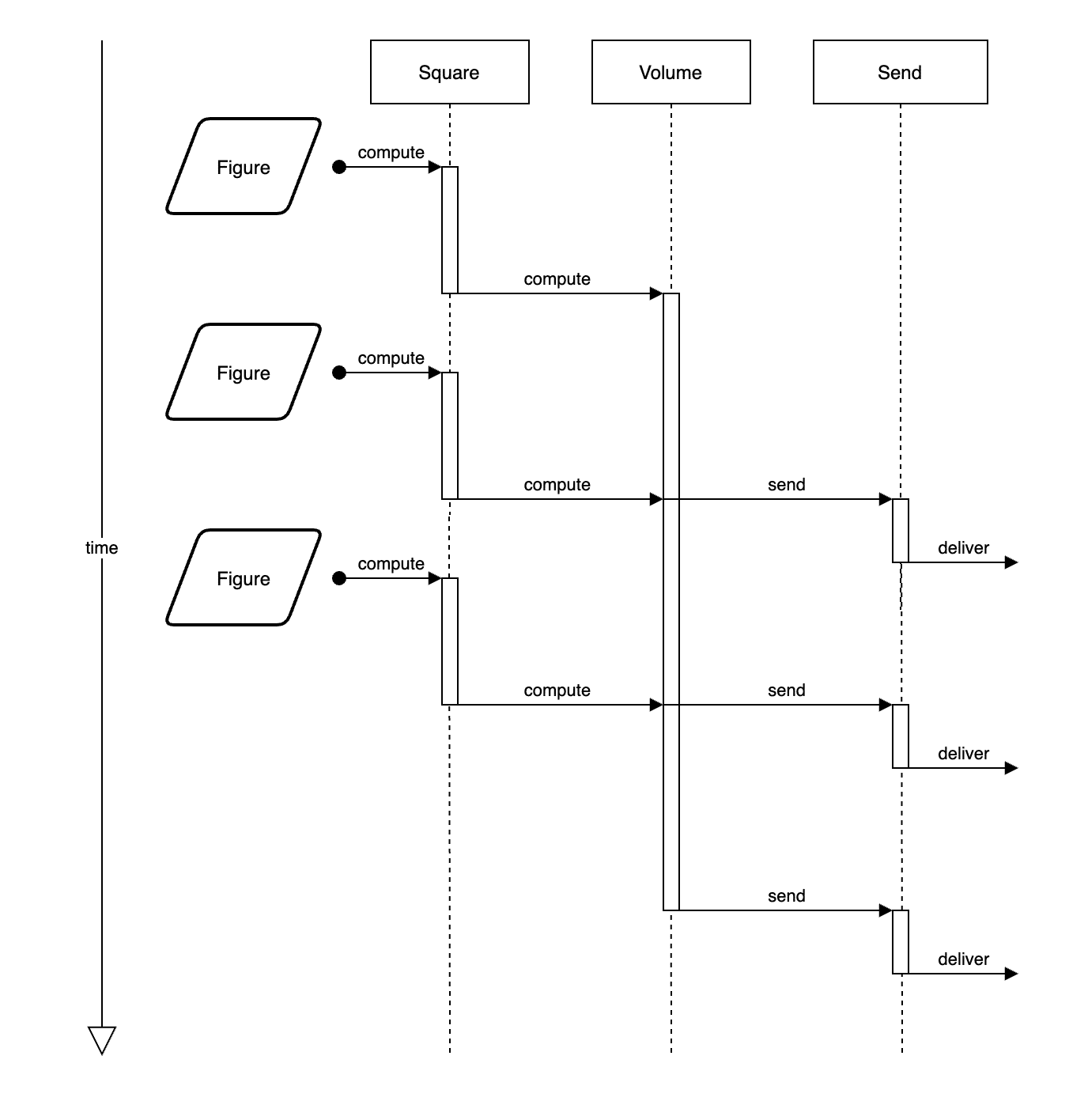
下图是我们准备在这做的事:
package main
import (
"fmt"
"sync"
"golang.org/x/sync/errgroup"
)
type Figure struct {
Length int
Width int
Height int
Square int
Volume int
}
const (
n = 2
statusOK = 0
statusError = 1
)
func main() {
errc := make(chan error)
status := statusOK
errProcess := sync.WaitGroup{}
errProcess.Add(1)
go func() {
for err := range errc {
status = statusError
fmt.Printf("error processing the code: %s\n", err)
}
errProcess.Done()
}()
ff := []Figure{
Figure{1, 2, -5, 0, 0},
Figure{3, 2, 4, 0, 0},
Figure{1, 10, 3, 0, 0},
Figure{1, 10, -3, 0, 0},
Figure{-1, 10, 3, 0, 0},
Figure{1, 10, 3, 0, 0}}
squarec := make(chan Figure, n)
volumec := make(chan Figure, n)
go func() {
if err := computeSquare(ff, squarec); err != nil {
errc <- err
}
close(squarec)
}()
go func() {
if err := computeVolume(squarec, volumec); err != nil {
errc <- err
}
close(volumec)
}()
send(volumec, errc)
close(errc)
errProcess.Wait()
}
func computeSquare(ff []Figure, squarec chan<- Figure) error {
eg := errgroup.Group{}
for _, f := range ff {
fClosure := f
eg.Go(func() error {
if fClosure.Length <= 0 || fClosure.Width <= 0 {
return fmt.Errorf("invalid length or width value, should be positive non-zero, length: %d, width: %d", fClosure.Length, fClosure.Width)
}
fClosure.Square = fClosure.Length * fClosure.Width
squarec <- fClosure
return nil
})
}
return eg.Wait()
}
func computeVolume(squarec <-chan Figure, volumec chan<- Figure) error {
eg := errgroup.Group{}
for f := range squarec {
fClosure := f
eg.Go(func() error {
if fClosure.Height <= 0 {
return fmt.Errorf("invalid height value, should be positive non-zero, height: %d", fClosure.Height)
}
fClosure.Volume = fClosure.Square * fClosure.Height
volumec <- fClosure
return nil
})
}
return eg.Wait()
}
func send(sourcec <-chan Figure, errc chan<- error) {
var err error
count := 0
batch := make([]Figure, 0, n)
for f := range sourcec {
if f.Volume > 25 {
err = fmt.Errorf("cannot send figures with volume more than 25, volume: %d", f.Volume)
errc <- err
}
// skip if error happens during sending
if err == nil {
batch = append(batch, f)
count++
if count == n {
// imitate sending batch
fmt.Println(batch)
batch = make([]Figure, 0, n)
count = 0
}
}
}
if err == nil && len(batch) != 0 {
// imitate sending rest
fmt.Println(batch)
}
}
由于errgroup仅返回一个错误,因此我们仅将该错误发送到错误通道。请注意,在计算函数中,我们将figure复制到fClosure变量中。这是因为errgroup接收变量f的闭包,并且“for”循环中的变量将始终在更改。因此,我们将在闭包中获得不正确的值。由于数据是并发处理的,代码不能保证我们将按照相同的顺序接收输出,因此程序给出了非确定性的结果。使用分组算法将根据输入中的数据项创建与数据项数量相同的Goroutines。这可能从RAM和CPU使用的角度来看不是最优的,并且对于大型数据输入而言可以降低整体性能。在这些情况下,我们通常使用工人;而且由于我们的阶段返回错误,因此我们确保使用出现错误的工人。我们使用自己实现的出现错误的工人:
package errworker
import (
"sync"
)
type ErrWorkgroup struct {
limiterc chan struct{}
wg sync.WaitGroup
errMutex sync.RWMutex
err error
skipWhenError bool
}
func NewErrWorkgroup(size int, skipWhenError bool) ErrWorkgroup {
if size < 1 {
size = 1
}
return ErrWorkgroup{
limiterc: make(chan struct{}, size),
skipWhenError: skipWhenError,
}
}
// Wait waits till all current jobs finish and returns first occurred error
// in case something went wrong.
func (w *ErrWorkgroup) Wait() error {
w.wg.Wait()
return w.err
}
// Go adds work func with error to the ErrWorkgroup. If err occurred other jobs won't proceed.
func (w *ErrWorkgroup) Go(work func() error) {
w.wg.Add(1)
go func(fn func() error) {
w.limiterc <- struct{}{}
if w.skipWhenError {
// if ErrWorkgroup corrupted -> skip work execution
w.errMutex.RLock()
if w.err == nil {
w.errMutex.RUnlock()
w.execute(fn)
} else {
w.errMutex.RUnlock()
}
} else {
w.execute(fn)
}
w.wg.Done()
<-w.limiterc
}(work)
}
func (w *ErrWorkgroup) execute(work func() error) {
if err := work(); err != nil {
w.errMutex.Lock()
w.err = err
w.errMutex.Unlock()
}
}
这个工人组可以接受无限数量的任务,但在任何单一时刻只执行构造函数func NewErrWorkgroup(size int,skipWhenError bool)中给定数量的任务。如果某些任务失败,则此工作池不会执行其余的入站任务;为了绕过这个问题,我们指定skipWhenError = true。这是通过受互斥锁errMutex保护的错误检查完成的。Mutex是指互斥对象,它使多个程序线程能够共享同一个资源,如变量或数据资源,但不能同时进行。当程序启动时,将创建具有唯一名称的Mutex,即errMutex。这保护Goroutines正在读取和写入的位置,并防止出现竞争条件(并导致代码中的错误)。注意:Mutex可在sync包中使用,并充当锁定机制,以确保在任何给定时间只有一个Goroutine运行关键代码部分。
正如您所看到的,该工人使用limiterc通道来限制工人数量。因此,所有任务都作为闲置(阻塞)Goroutines保持,并且不会消耗CPU。
使用工人的代码如下所示:
package main
import (
"fmt"
"github.com/guntenbein/goconcurrency/errworker"
"sync"
)
type Figure struct {
Length int
Width int
Height int
Square int
Volume int
}
const (
n = 2
statusOK = 0
statusError = 1
)
func main() {
errc := make(chan error)
status := statusOK
errGroup := sync.WaitGroup{}
errGroup.Add(1)
go func() {
for err := range errc {
status = statusError
fmt.Printf("error processing the code: %s\n", err)
}
errGroup.Done()
}()
ff := []Figure{
Figure{1, 2, 5, 0, 0},
Figure{3, 2, 4, 0, 0},
Figure{1, 10, 3, 0, 0},
Figure{1, 10, -3, 0, 0},
Figure{1, -10, 3, 0, 0},
Figure{1, 10, 5, 0, 0}}
squarec := make(chan Figure, n)
volumec := make(chan Figure, n)
go func() {
if err := computeSquare(ff, squarec); err != nil {
errc <- err
}
close(squarec)
}()
go func() {
if err := computeVolume(squarec, volumec); err != nil {
errc <- err
}
close(volumec)
}()
send(volumec, errc)
close(errc)
errGroup.Wait()
}
func computeSquare(ff []Figure, squarec chan<- Figure) error {
ew := errworker.NewErrWorkgroup(2, true)
for _, f := range ff {
fClosure := f
ew.Go(func() error {
if fClosure.Length <= 0 || fClosure.Width <= 0 {
return fmt.Errorf("invalid length or width value, should be positive non-zero, length: %d, width: %d", fClosure.Length, fClosure.Width)
}
fClosure.Square = fClosure.Length * fClosure.Width
squarec <- fClosure
return nil
})
}
return ew.Wait()
}
func computeVolume(squarec <-chan Figure, volumec chan<- Figure) error {
ew := errworker.NewErrWorkgroup(3, true)
var err error
for f := range squarec {
fClosure := f
ew.Go(func() error {
if fClosure.Height <= 0 {
err = fmt.Errorf("invalid height value, should be positive non-zero, height: %d", fClosure.Height)
return err
}
fClosure.Volume = fClosure.Square * fClosure.Height
volumec <- fClosure
return nil
})
}
return ew.Wait()
}
func send(sourcec <-chan Figure, errc chan<- error) {
var err error
count := 0
batch := make([]Figure, 0, n)
for f := range sourcec {
if f.Volume > 40 {
err = fmt.Errorf("cannot send figures with volume more than 25, volume: %d", f.Volume)
errc <- err
}
// skip if error happens during sending
if err == nil {
batch = append(batch, f)
count++
if count == n {
// imitate sending batch
fmt.Println(batch)
batch = make([]Figure, 0, n)
count = 0
}
}
}
if err == nil && len(batch) != 0 {
// imitate sending rest
fmt.Println(batch)
}
}
结构上,如果我们使用错误等待组(error waitgroup),则与代码并没有太大的区别。但是,它确实可以帮助我们节省RAM和CPU,因为我们可以并行运行所有内容,这使我们能够正确分配资源。假设计算体积所需的时间比计算平方要长。我们可以通过将任务分配给3个工人的体积阶段和2个工人的平方阶段来平衡它。
在Go并发编程中,我们始终使用-race标志进行测试,以便在代码中发现竞争条件的信息。这是Go的一项便利功能,因为它允许在软件开发的非常早期发现竞争条件。


